SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现
唯一索引可通过以下方式实现:
PRIMARY KEY 或 UNIQUE 约束
在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动对一列或多列创建唯一聚集索引。 主键列不允许空值。
在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束。 如果不存在该表的聚集索引,则可以指定唯一聚集索引。
有关详细信息,请参阅 Unique Constraints and Check Constraints 和 Primary and Foreign Key Constraints。
独立于约束的索引
可以为一个表定义多个唯一非聚集索引。
有关详细信息,请参阅 CREATE INDEX (Transact-SQL)。
索引视图
若要创建索引视图,请对一个或多个视图列定义唯一聚集索引。 视图将执行,并且结果集存储在该索引的页级别中,其存储方式与表数据存储在聚集索引中的方式相同。 有关详细信息,请参阅 创建索引视图。
创建唯一非聚集索引限制和局限
如果数据中存在重复的键值,则不能创建唯一索引、UNIQUE 约束或 PRIMARY KEY 约束。
唯一非聚集索引可以包括包含性非键列。 有关详细信息,请参阅 Create Indexes with Included Columns。
使用SSMS数据库管理工具创建唯一非聚集索引
使用表设计器创建唯一非聚集索引
1、连接数据库,选择数据库,选择数据表-》右键点击-》选择设计。

2、在表设计器窗口-》选择要添加索引的属性列-》右键点击-》选择索引/键。
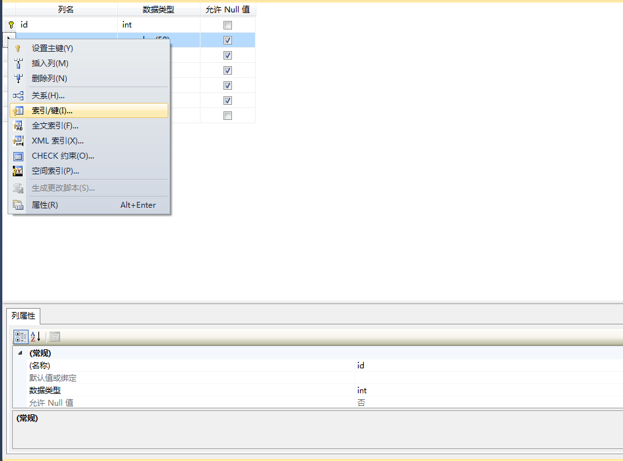
3、在索引/键弹出框-》点击添加,添加索引-》在常规窗口类型选择索引-》点击列选择数据列。
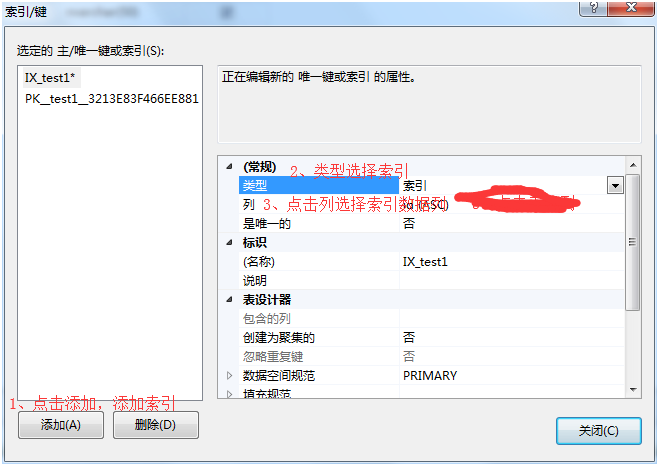
4、在索引列弹出框-》点击添加索引列-》点击选择索引列排序规则-》可以把一个索引建立在多个数据列上-》点击确定。
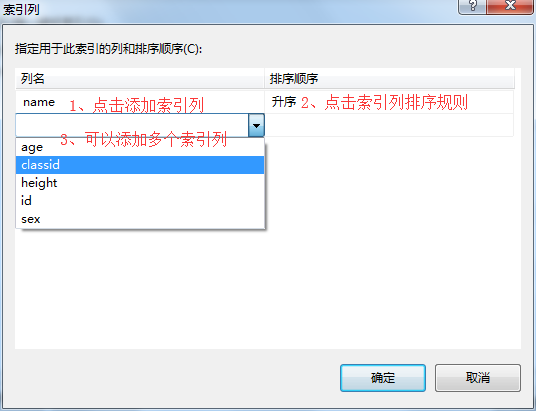
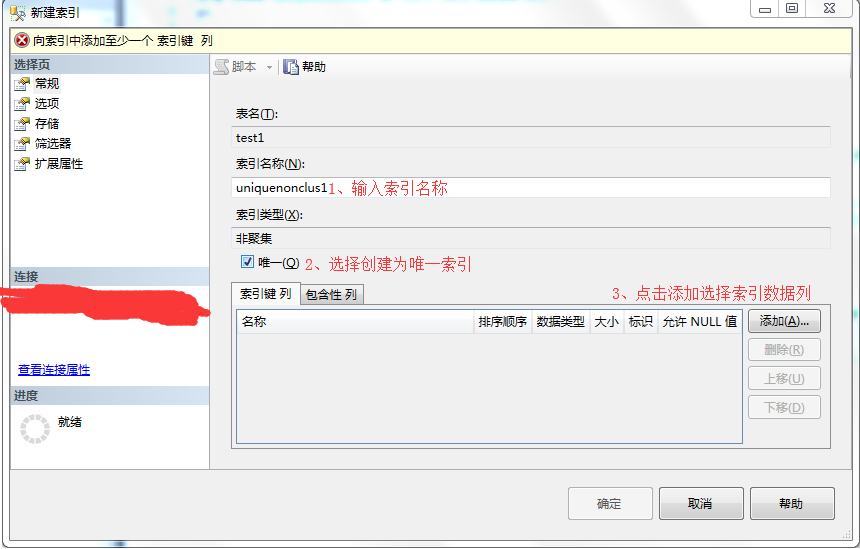
5、在索引/键弹出框-》选择创建唯一索引-》输入索引名称-》输入索引描述-》选择创建为非聚集索引-》其它可以选择默认-》点击关闭。
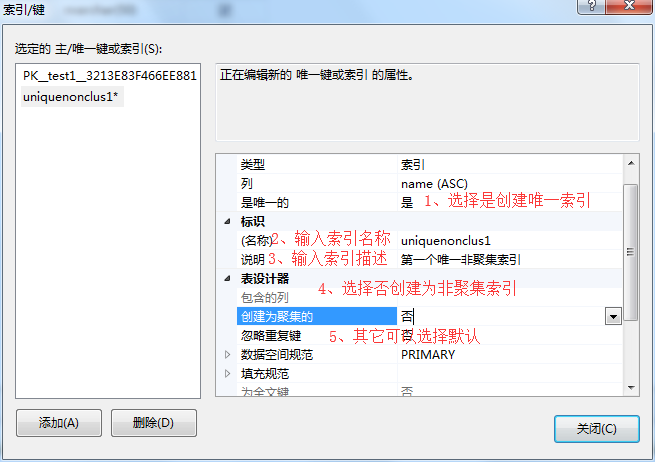
6、点击保存(或者ctrl+s)-》关闭表设计器-》刷新表-》查看结果。
使用对象资源管理器创建唯一索引
1、连接数据库,选择数据库,选择数据表-》展开对象资源管理器-》右键点击索引-》选择新建索引-》选择非聚集索引。

2、在新建索引弹出框-》输入索引名称-》选择创建为唯一索引-》点击添加,选择索引数据列。
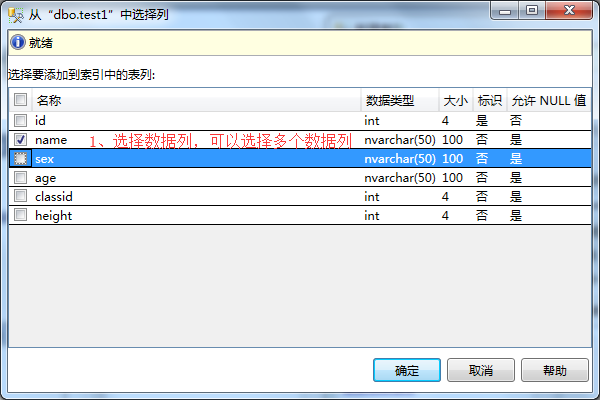
3、在数据表列-》选择索引要添加的数据列,可以选择多个-》点击确定。
4、在新建索引窗口-》点击包含性列-》点击添加。
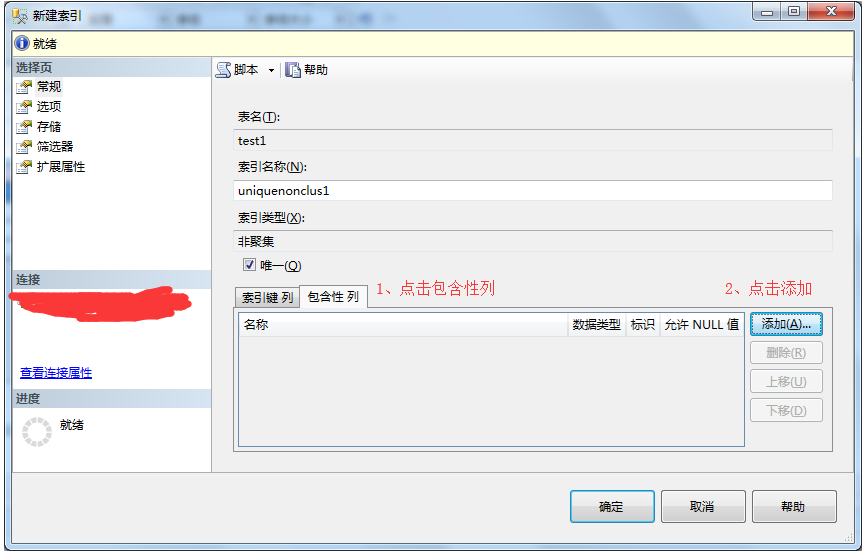
5、在数据表列-》点击选择包含性列,可以选择多个-》点击确定。
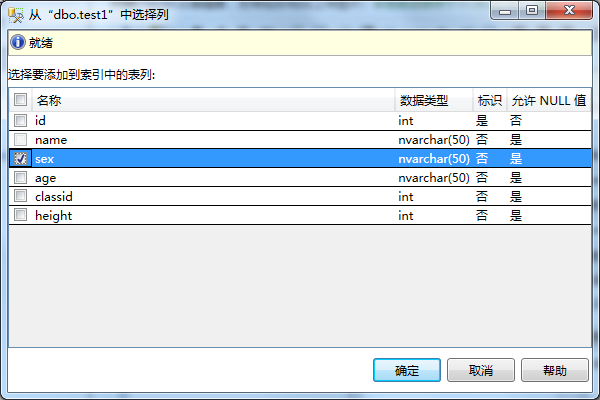
6、在新建索引窗口-》点击选项-》可以自己设置索引属性。
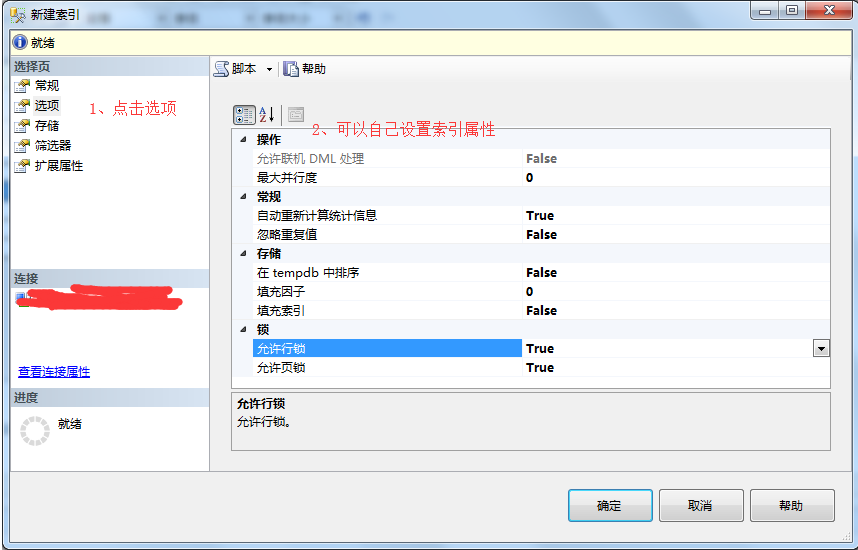
7、在新建索引弹出框-》点击存储-》设置索引和数据存储规则。
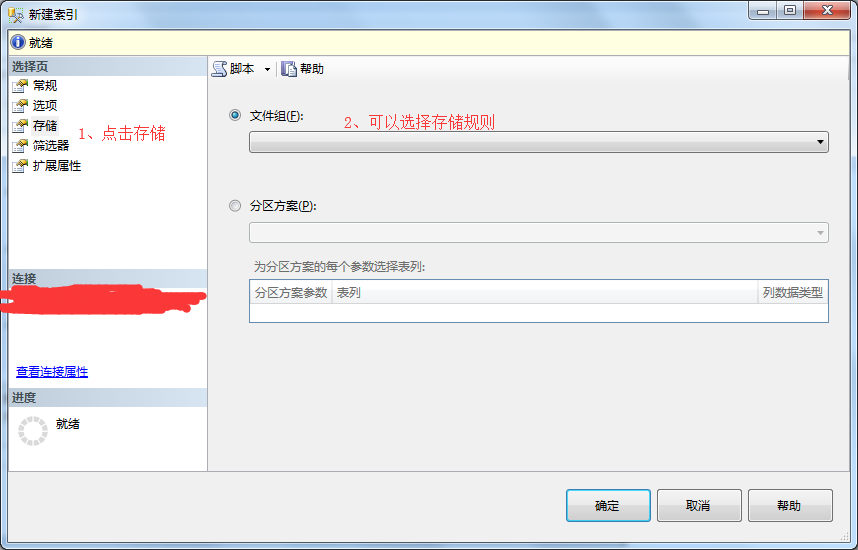
8、在新建索引弹出框-》点击筛选器-》输入筛选规则。
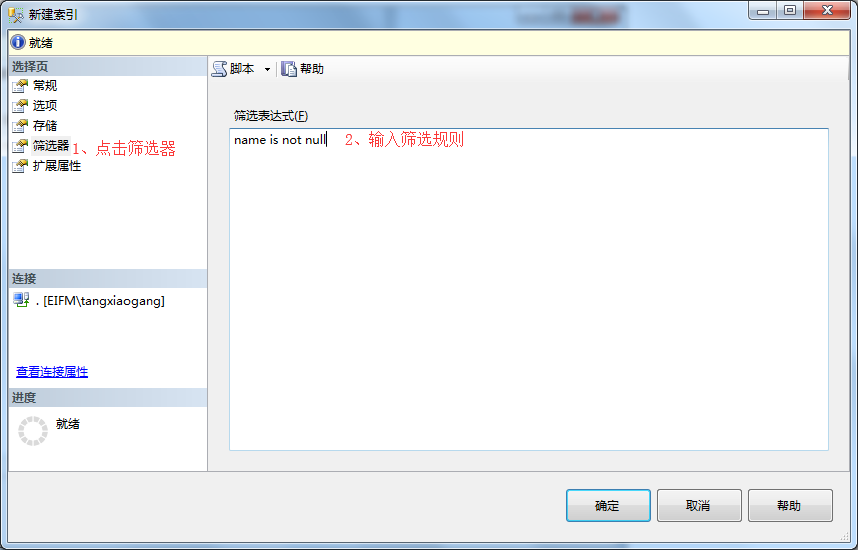
9、在新建索引弹出框-》点击扩展属性-》输入扩展属性名称-》输入扩展属性名称-》可以输入多个扩展属性-》点击确定。

10、查看创建结果。
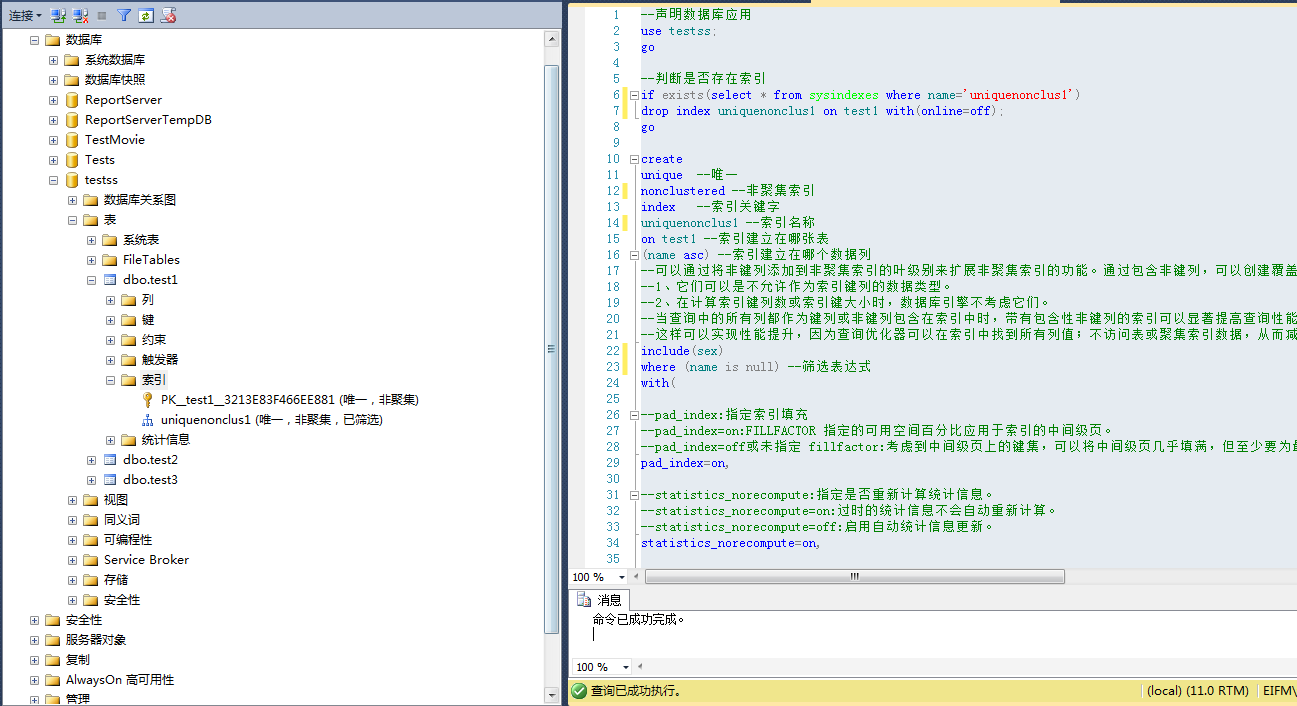
使用T-SQL脚本创建唯一非聚集索引
语法:
--声明数据库引用
use 数据库名;
go
--判断索引是否存在
if exists(select * from sysindexes where name=索引名)
drop index 索引名 on 表名 with (online=off);
go
--添加索引
create
--[unique] --指定聚集索引是否唯一
[clustered | nonclustered] --指定为聚集索引
index 索引名称 --索引名称
on 表名 --索引添加在哪个表
(列名 [asc | desc],列名 [asc | desc],...) --索引添加在哪个数据列
--可以通过将非键列添加到非聚集索引的叶级别来扩展非聚集索引的功能。通过包含非键列,可以创建覆盖更多查询的非聚集索引。这是因为非键列具有下列优点:
--1、它们可以是不允许作为索引键列的数据类型。
--2、在计算索引键列数或索引键大小时,数据库引擎不考虑它们。
--当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。
--这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。
include(列名,......)
where (筛选表达式) --筛选表达式
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key={ on | off },
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
--maxdop=max_degree_of_parallelism,
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression={ none | row | page | columnstore | columnstore_archive }
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];--数据空间规范
go
--添加注释
execute sp_addextendedproperty N'MS_Description',N'索引说明',N'schema',N'dbo',N'table',N'表名',N'index',N'索引名称';
go
示例:
--声明数据库应用
use testss;
go
--判断是否存在索引
if exists(select * from sysindexes where name='uniquenonclus1')
drop index uniquenonclus1 on test1 with(online=off);
go
create
unique --唯一
nonclustered --非聚集索引
index --索引关键字
uniquenonclus1 --索引名称
on test1 --索引建立在哪张表
(name asc) --索引建立在哪个数据列
--可以通过将非键列添加到非聚集索引的叶级别来扩展非聚集索引的功能。通过包含非键列,可以创建覆盖更多查询的非聚集索引。这是因为非键列具有下列优点:
--1、它们可以是不允许作为索引键列的数据类型。
--2、在计算索引键列数或索引键大小时,数据库引擎不考虑它们。
--当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。
--这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。
include(sex)
where (name is null) --筛选表达式
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=on,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=on,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=off,
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key=off,
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing=off,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=1,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=1
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression=none
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];
go
--添加唯一聚集索引描述
execute sp_addextendedproperty N'MS_Description',N'第一个唯一聚集索引',N'schema',N'dbo',N'table',N'test1',N'index',N'uniquenonclus1';
go
创建唯一非聚集索引优缺点
优点:
1、只要每个列中的数据是唯一的,就可以为同一个表创建多个唯一非聚集索引。
2、唯一索引提供帮助查询优化器生成更高效的执行计划的其他信息。
3、唯一索引能够确保定义的列的数据完整性。
4、多列唯一索引能够保证索引键中值的每个组合都是唯一的。
5、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
6、在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
缺点:
1、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2、索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。
3、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
SQLServer之创建唯一非聚集索引的更多相关文章
- SQLServer之创建唯一聚集索引
创建唯一聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动 ...
- SQLServer之创建非聚集索引
开始之前 典型实现 可以通过下列方法实现非聚集索引: UNIQUE 约束 在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束. 如果不存在该表的聚集索引,则可以 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQL Server 2014,表变量上的非聚集索引
从Paul White的推特上看到,在SQL Server 2014里,对于表变量(Table Variables),它是支持非唯一聚集索引(Non-Unique Clustered Indexes) ...
- SQL聚集索引和非聚集索引的区别
其实对于非专业的数据库操作人员来讲,例如软件开发人员,在很大程度上都搞不清楚数据库索引的一些基本知识,有些是知其一不知其二,或者是知其然不知其所以然.造成这种情况的主要原因我觉的是行业原因,有很多公司 ...
- 你能说出SQL聚集索引和非聚集索引的区别吗?
最近突然想起前一阵和一朋友的聊天,当时他问我的问题是一个非常普通的问题:说说SQL聚集索引和非聚集索引的区别. AD:WOT2015 互联网运维与开发者大会 热销抢票 其实对于非专业的数据库操作人员来 ...
- SQL Server-聚焦聚集索引对非聚集索引的影响(四)
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任 ...
- 索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引.我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构. 非聚集索引的逻辑呈现 简单来说,非聚集索引是表的子 ...
- SQL Server-聚焦聚集索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没 ...
随机推荐
- nfs服务启动失败:Failed to start NFS status monitor for NFSv2/3 locking..
今天碰到个问题,服务器重启后,nfs服务就启动不了了,关闭都关不了.查看系统日志报下面的错: Aug 10 17:08:53 prod-r3-slt-s-01 systemd: Started Pre ...
- spark使用udf给dataFrame新增列
在 spark 中给 dataframe 增加一列的方法一般使用 withColumn // 新建一个dataFrame val sparkconf = new SparkConf() .setMas ...
- "无需开发经验" 也能拥有小程序
本文分享嘉宾:毛帅,又拍图片管家资深开发工程师,主要负责又拍图片管家.图管小程序第三方平台.图管小程序等项目的开发.维护及拓新工作.熟悉 JS / C++ 等语言,有丰富的 NodeJS 开发经验,热 ...
- Qt之QComboBox定制(二)
上一篇文章Qt之QComboBox定制讲到了qt实现自定义的下拉框,该篇文章主要实现了列表式的下拉框,这一节我还将继续讲解QComboBox的定制,而这一节我将会讲述更高级的用法,不仅仅是下拉列表框, ...
- 带着新人学springboot的应用02(springboot+mybatis+缓存 中)
继续接着上一节,大家应该知道驼峰命名法吧!就是我们javabean中属性一般命名是lastName,userName这种类型的,而数据库中列名一般都是last_name,user_name这种的,要让 ...
- 不在models.py中的models
概述 如何让你定义的model不在models.py中 在app的models目录中的models 你新建一个app后这个models.py就会自动建立,里面只有几行代码.那么如果是一个中大型项目,每 ...
- Asp.Net SignalR 集线器不使用代理的实现
不使用生成代理JS的实现 可能有同学会觉得使用集线器很麻烦,要么引入虚拟目录,要么在生成期间生成js文件,再引入js文件进行开发.难道就没有比较清爽的方式吗?这个当然是有的,先不要(。・∀・)ノ゙嗨皮 ...
- RabbitMQ消息队列(十一)-如何实现高可用
在前面讲到了RabbitMQ高可用集群的搭建,但是我们知道只是集群的高可用并不能保证应用在使用消息队列时完全没有问题,例如如果应用连接的RabbitMQ集群突然宕机了,虽然这个集群时可以使用的,但是应 ...
- iBinary C++STL模板库关联容器之map/multimap
目录 一丶关联容器map/multimap 容器 二丶代码例子 1.map的三种插入数据的方法 3.map集合的遍历 4.验证map集合数据是否插入成功 5.map数据的查找 6.Map集合删除元素以 ...
- 图像检索(1): 再论SIFT-基于vlfeat实现
概述 基于内容的图像检索技术是采用某种算法来提取图像中的特征,并将特征存储起来,组成图像特征数据库.当需要检索图像时,采用相同的特征提取技术提取出待检索图像的特征,并根据某种相似性准则计算得到特征数据 ...