1.1 Introduction中 Topics and Logs官网剖析(博主推荐)
不多说,直接上干货!
一切来源于官网
http://kafka.apache.org/documentation/

Topics and Logs
话题和日志 (Topic和Log)
Let's first dive into the core abstraction Kafka provides for a stream of records—the topic.
让我们更深入的了解Kafka中的Topic。
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
Topic是发布的消息的类别或者种子Feed名。对于每一个Topic,Kafka集群维护这一个分区的log,就像下图中的示例:
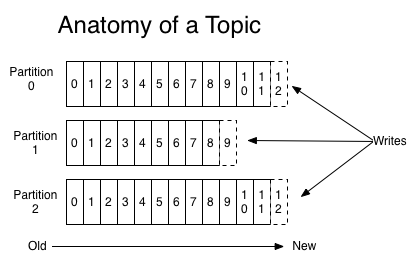
Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
The Kafka cluster retains all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
Kafka集群保持所有的消息,直到它们过期, 无论消息是否被消费了。 实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。
这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。
但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。
再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。
Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点。
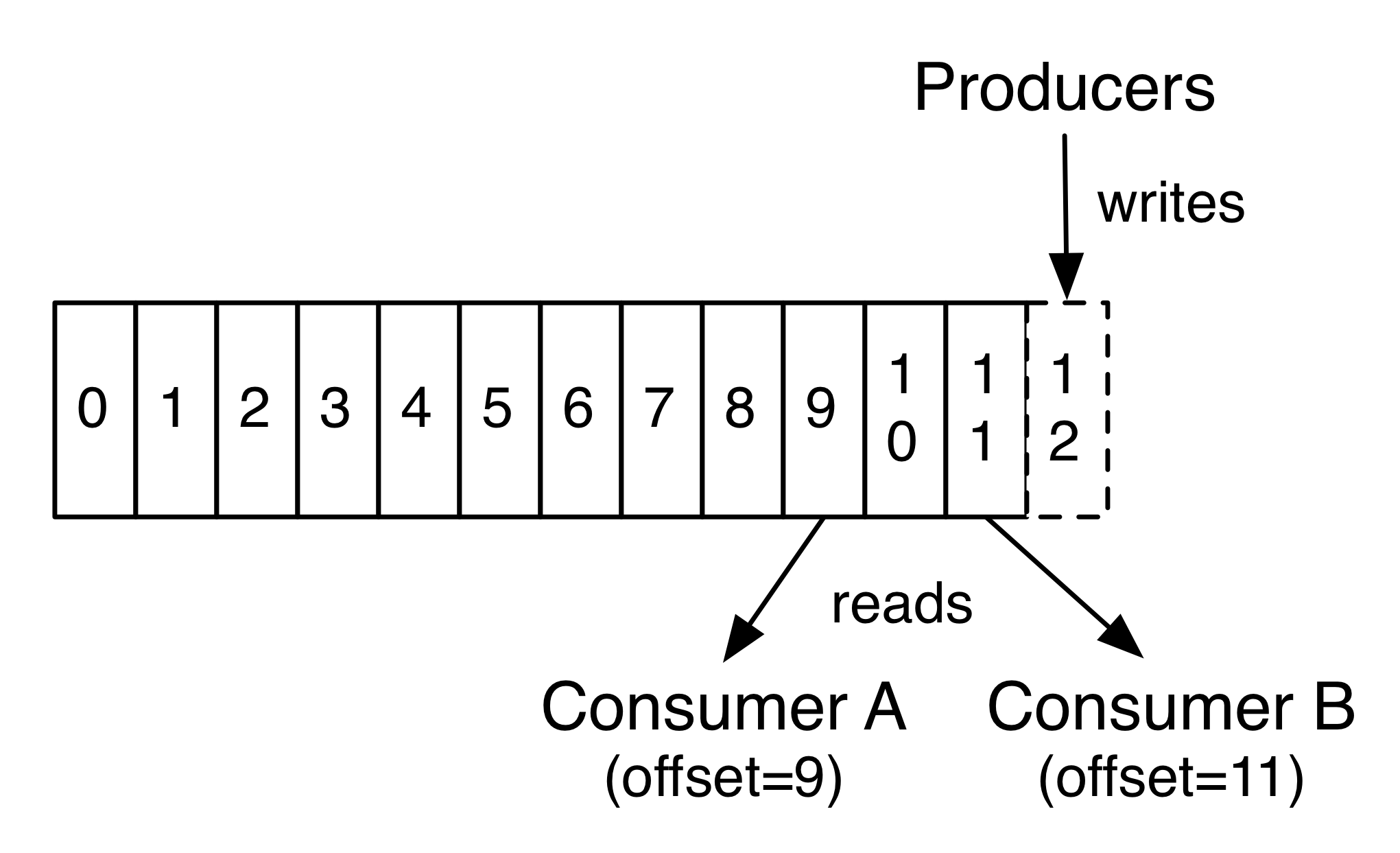
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is consumed by any existing consumers.
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
1.1 Introduction中 Topics and Logs官网剖析(博主推荐)的更多相关文章
- Flume Channel Selectors官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) 一切来源于flume官网 http://flume.apache.org/Flu ...
- Flume Channels官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) 一切来源于flume官网 http://flume.apache.org/FlumeUserGuide.html Flume Ch ...
- Flume Source官网剖析(博主推荐)
不多说,直接上干货! 一切来源于flume官网 http://flume.apache.org/FlumeUserGuide.html Flume Sources Avro Source Thrift ...
- 1.2 Use Cases中 Website Activity Tracking官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Website Activity Tracking 网站活动追踪 The origi ...
- Flume Interceptors官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) Flume Channel Selectors官网剖析(博主推荐) Flume ...
- Event Serializers官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) Flume Channel Selectors官网剖析(博主推荐) Flume ...
- Flume Sink Processors官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) Flume Channel Selectors官网剖析(博主推荐) Flume ...
- Flume Sinks官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) Flume Channel Selectors官网剖析(博主推荐) 一切来源于f ...
- 怎样取消老毛桃软件赞助商---只需在输入框中输入老毛桃官网网址“laomaotao.org”
来源:www.laomaotao.org 时间:2015-01-29 在众多网友和赞助商的支持下,迄今为止,老毛桃u盘启动盘制作工具已经推出了多个版本.如果有用户希望取消显示老毛桃软件中的赞助商,那不 ...
随机推荐
- 如何使用通用pe工具箱破解开机密码
下载最新版的通用pe工具箱将u盘制作成启动盘,接着重启连续按热键进入到bios系统下,设置u盘为第一启动,保存重启. 1.这时候会进入通用pe工具箱的选择界面,我们选择第八个“运行Windows登陆密 ...
- android学习笔记二、Activity深入学习
一.创建和使用: 1.Activity是android的四大组件之一,需要继承Activity并在清单文件中进行声明才能使用.没有声明则报错. 2.启动Activity是通过Intent,有两种方式: ...
- JWT 使用介绍
转载收藏于 http://www.cnblogs.com/zjutzz/p/5790180.html JWT是啥? JWT就是一个字符串,经过加密处理与校验处理的字符串,形式为: A.B.C A由JW ...
- 在使用FireFox浏览器时,经常打开新标签,页面总是不断自动刷新,解决办法
可以用如下方法尝试(逐个尝试,看看哪个管用): 1.地址栏输入 about:support,右上角有个翻新Firefox,点击,等待浏览器重启,即可. 2.点击:工具-附加组件,把“火狐主页和标签管理 ...
- jQuery中四种事件监听的区别
原文链接:点我 我们知道jquery提供了四种事件监听方式,分别是bind.live.delegate.on,下面就分别对这四种事件监听方式分析. 已知有4个列表元素: 列表元素1 列表元素2 列表元 ...
- caioj 1065 动态规划入门(一维一边推3:合唱队形)
就是最长上升子序列,但是要用n^2的算法. #include<cstdio> #include<algorithm> #define REP(i, a, b) for(int ...
- visualvm监控tomcat
https://my.oschina.net/weidedong/blog/787203
- BZOJ——1012: [JSOI2008]最大数maxnumber || 洛谷—— P1198 [JSOI2008]最大数
http://www.lydsy.com/JudgeOnline/problem.php?id=1012|| https://www.luogu.org/problem/show?pid=1198 T ...
- mysql查一张表有哪些索引
可以用这个命令: show index from table_name; 得到输出: +------------------+------------+------------+----------- ...
- Thinkphp5图片上传正常,音频和视频上传失败的原因及解决
Thinkphp5图片上传正常,音频和视频上传失败的原因及解决 一.总结 一句话总结:php中默认限制了上传文件的大小为2M,查找错误的时候百度,且根据错误提示来查找错误. 我的实际问题是: 我的表单 ...