Hadoop MapReduce编程 API入门系列之网页流量版本1(二十二)
不多说,直接上代码。
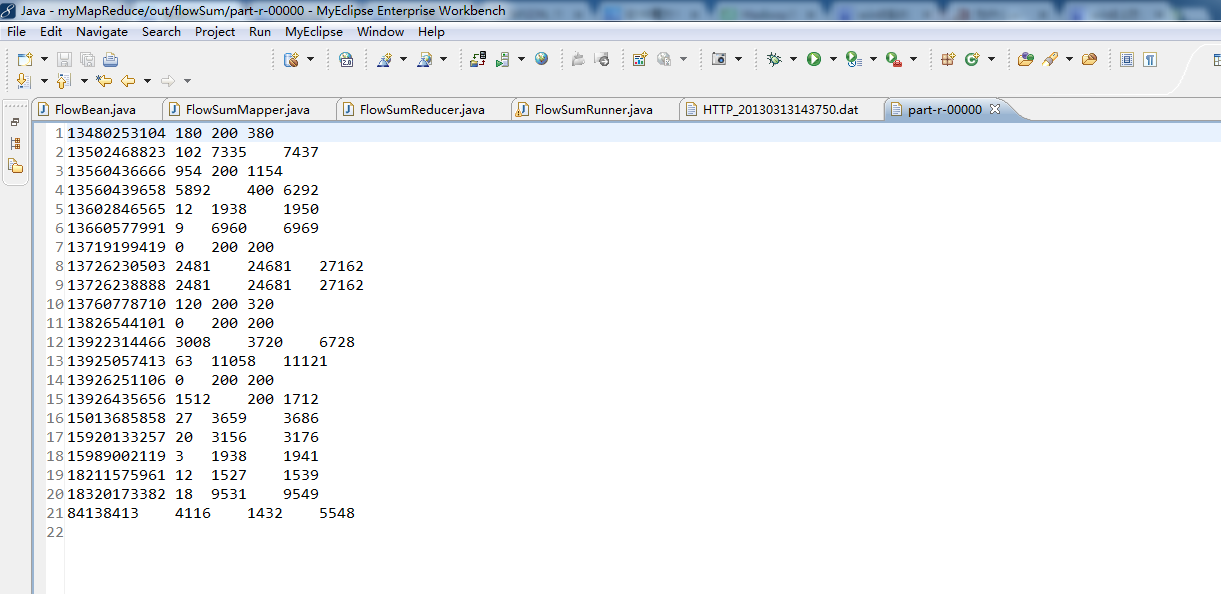
对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件。







代码
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean>{
private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow;
//在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean(){}
//为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getS_flow() {
return s_flow;
}
public void setS_flow(long s_flow) {
this.s_flow = s_flow;
}
//将对象数据序列化到流中
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow);
}
//从数据流中反序列出对象的数据
//从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong();
}
@Override
public String toString() {
return "" + up_flow + "\t" +d_flow + "\t" + s_flow;
}
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* FlowBean 是我们自定义的一种数据类型,要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制
* 就必须实现hadoop相应的序列化接口
*
*
*/
public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
//拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿一行数据
String line = value.toString();
//切分成各个字段
String[] fields = StringUtils.split(line, "\t");
//拿到我们需要的字段
String phoneNB = fields[1];
long u_flow = Long.parseLong(fields[7]);
long d_flow = Long.parseLong(fields[8]);
//封装数据为kv并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
//框架每传递一组数据<1387788654,{flowbean,flowbean,flowbean,flowbean.....}>调用一次我们的reduce方法
//reduce中的业务逻辑就是遍历values,然后进行累加求和再输出
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
long up_flow_counter = 0;
long d_flow_counter = 0;
for(FlowBean bean : values){
up_flow_counter += bean.getUp_flow();
d_flow_counter += bean.getD_flow();
}
context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter));
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import zhouls.bigdata.myMapReduce.Anagram.Anagram;
//这是job描述和提交类的规范写法
public class FlowSumRunner extends Configured implements Tool{
public int run(String[] arg0) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumRunner.class);
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
//集群路径
// String[] args0 = { "hdfs://HadoopMaster:9000/flowSum/HTTP_20130313143750.dat",
// "hdfs://HadoopMaster:9000/out/flowSum"};
//本地路径
String[] args0 = { "./data/flowSum/HTTP_20130313143750.dat",
"./out/flowSum/"};
int ec = ToolRunner.run( new Configuration(), new FlowSumRunner(), args0);
System. exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之网页流量版本1(二十二)的更多相关文章
- Hadoop MapReduce编程 API入门系列之网页流量版本1(二十一)
不多说,直接上代码. 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件. 代码 package zhouls.bigdata.myMapReduce.areapartition; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
随机推荐
- 三维重建面试13X:一些算法试题-今日头条AI-Lab
被人牵着鼻子走,到了地方还墨明棋妙地吃一顿砖头.今日头条AI-Lab,其实我一直发现,最擅长的还是点云图像处理,且只是点云处理. 一.C++题目 New 与Malloc的区别: ...
- node mysql es6/es7改造
本文js代码采取了ES6/ES7的写法,而不是commonJs的写法.支持一波JS的新语法.node版本的mysql驱动,通过npm i mysql安装.官网地址:https://github.com ...
- es6-set-map数据结构
Set的用法 set的key一定是字符串 { let list=new Set(); list.add(5);//向set中增加值要用add() list.add(6); console.log('s ...
- 关于DataGridViewComboBoxColumn的二三事
近日开发一个基于WinForm的工具,用到了DataGridViewComboBoxColumn. 关于数据: DataGridView的数据源是代码生成的DataTable DataGridView ...
- Clocksource tsc unstable
内核在启动过程中会根据既定的优先级选择时钟源.优先级的排序根据时钟的精度与访问速度. 其中CPU中的TSC寄存器是精度最高(与CPU最高主频等同),访问速度最快(只需一条指令,一个时钟周期)的时钟源, ...
- 51nod1185 威佐夫游戏 V2【博弈论】
有2堆石子.A B两个人轮流拿,A先拿.每次可以从一堆中取任意个或从2堆中取相同数量的石子,但不可不取.拿到最后1颗石子的人获胜.假设A B都非常聪明,拿石子的过程中不会出现失误.给出2堆石子的数量, ...
- java中的replaceAll方法注意事项
replaceAll和replace方法参数是不同的,replace的两个参数都是代表字符串,replaceAll的第一个参数是正则表达式 replaceAll中需要注意的特殊字符: \ == \\\ ...
- Centos 修改主机名称
Centos 配置主机名称: 1.首先查询一下当前的主机名称 [root@localhost~]# hostnamectl status Static hostname: ****** //永久主机名 ...
- Unity 利用FFmpeg实现录屏、直播推流、音频视频格式转换、剪裁等功能
目录 一.FFmpeg简介. 二.FFmpeg常用参数及命令. 三.FFmpeg在Unity 3D中的使用. 1.FFmpeg 录屏. 2.FFmpeg 推流. 3.FFmpeg 其他功能简述. 一. ...
- JavaSE 学习笔记之面向对象(三)
面向对象 特点: 1:将复杂的事情简单化. 2:面向对象将以前的过程中的执行者,变成了指挥者. 3:面向对象这种思想是符合现在人们思考习惯的一种思想. 过程和对象在我们的程序中是如何体现的呢?过程 ...