Hadoop MapReduce编程 API入门系列之网页流量版本1(二十二)
不多说,直接上代码。
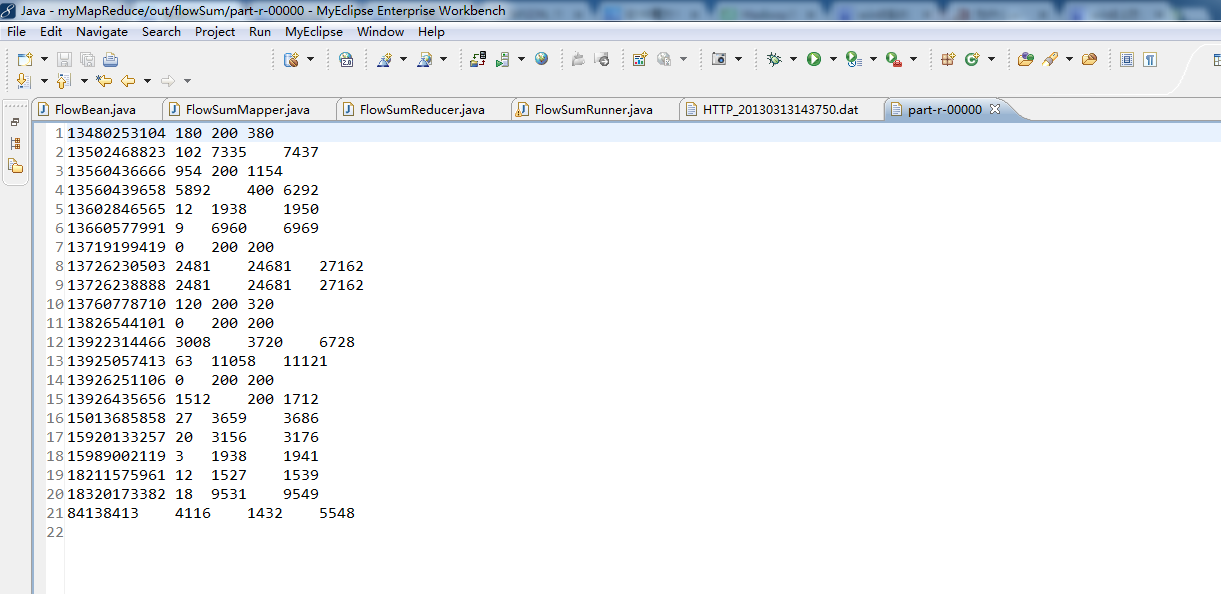
对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件。







代码
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean>{
private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow;
//在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean(){}
//为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
}
public String getPhoneNB() {
return phoneNB;
}
public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
}
public long getUp_flow() {
return up_flow;
}
public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
}
public long getD_flow() {
return d_flow;
}
public void setD_flow(long d_flow) {
this.d_flow = d_flow;
}
public long getS_flow() {
return s_flow;
}
public void setS_flow(long s_flow) {
this.s_flow = s_flow;
}
//将对象数据序列化到流中
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow);
}
//从数据流中反序列出对象的数据
//从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong();
}
@Override
public String toString() {
return "" + up_flow + "\t" +d_flow + "\t" + s_flow;
}
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* FlowBean 是我们自定义的一种数据类型,要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制
* 就必须实现hadoop相应的序列化接口
*
*
*/
public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
//拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿一行数据
String line = value.toString();
//切分成各个字段
String[] fields = StringUtils.split(line, "\t");
//拿到我们需要的字段
String phoneNB = fields[1];
long u_flow = Long.parseLong(fields[7]);
long d_flow = Long.parseLong(fields[8]);
//封装数据为kv并输出
context.write(new Text(phoneNB), new FlowBean(phoneNB,u_flow,d_flow));
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
//框架每传递一组数据<1387788654,{flowbean,flowbean,flowbean,flowbean.....}>调用一次我们的reduce方法
//reduce中的业务逻辑就是遍历values,然后进行累加求和再输出
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
long up_flow_counter = 0;
long d_flow_counter = 0;
for(FlowBean bean : values){
up_flow_counter += bean.getUp_flow();
d_flow_counter += bean.getD_flow();
}
context.write(key, new FlowBean(key.toString(), up_flow_counter, d_flow_counter));
}
}
package zhouls.bigdata.myMapReduce.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.OutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import zhouls.bigdata.myMapReduce.Anagram.Anagram;
//这是job描述和提交类的规范写法
public class FlowSumRunner extends Configured implements Tool{
public int run(String[] arg0) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowSumRunner.class);
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
//集群路径
// String[] args0 = { "hdfs://HadoopMaster:9000/flowSum/HTTP_20130313143750.dat",
// "hdfs://HadoopMaster:9000/out/flowSum"};
//本地路径
String[] args0 = { "./data/flowSum/HTTP_20130313143750.dat",
"./out/flowSum/"};
int ec = ToolRunner.run( new Configuration(), new FlowSumRunner(), args0);
System. exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之网页流量版本1(二十二)的更多相关文章
- Hadoop MapReduce编程 API入门系列之网页流量版本1(二十一)
不多说,直接上代码. 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件. 代码 package zhouls.bigdata.myMapReduce.areapartition; i ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
随机推荐
- 用VS Code Debug Python
- c#如何用代码开启cmd指定命令(如:运行一个手机adb shell命令)
else if (this.Mode == TravelMode.AutoRecodeMode) { DateTime StartDate = DateTime.Now; string args = ...
- 初识cocos creator的一些问题
本文的cocos creator版本为v1.9.01.color赋值cc.Label组件并没有颜色相关的属性,但是Node有color的属性. //如果4个参数,在ios下有问题let rgb = [ ...
- MySQL+Keepalived实现主主高可用方案
Mysql主主高可用方案 master配置 [root@master ~]# yum -y install keepalived [root@master ~]# vim /etc/keepalive ...
- anaconda安装的TensorFlow版本没有model这个模块
一.采用git bash来安装,确认已经安装了git 二.手动找到TensorFlow的模块文件夹地址,若不知道,输入以下两行代码: import tensorflow as tf tf.__path ...
- PKU 1019 Number Sequence(模拟,思维)
题目 以下思路参考自discuss:http://poj.org/showmessage?message_id=176353 /*我的思路: 1.将长串数分成一个个部分,每个部分是从1到x的无重复的数 ...
- [MySQL优化案例]系列 — RAND()优化
众所周知,在MySQL中,如果直接 ORDER BY RAND() 的话,效率非常差,因为会多次执行.事实上,如果等值查询也是用 RAND() 的话也如此,我们先来看看下面这几个SQL的不同执行计划和 ...
- zabbix监控AIX DB2数据库
记一次工作中使用zabbix监控aix db2数据库的经历. 记忆要点: 1.使用自定义perl脚本: 2.由于zabbix用户权限的原因,无法调用db2用户获取数据库的数据,所以在zabbix配置文 ...
- ldap 基本名词解释(3)
名词解释 Objectclass LDAP对象类,是LDAP内置的数据模型.每种objectClass有自己的数据结构,比如我们有一种叫“电话薄”的objectClass,肯定会内置很多属性(attr ...
- Python-Pandas数据处理