Flume的安装,配置及使用
1,上传jar包
2,解压
3,改名
4,更改配置文件
将template文件重镜像
root@Ubuntu-1:/usr/local/apache-flume/conf# cat flume-env.sh.template >flume-env.sh
在flume-env.sh文件中更改JAVA_HOME地址:
export JAVA_HOME=/usr/local/jdk1.8.0_91 //132和135中均是/usr/local/jdk1.7.0_79,不要混淆了
检查Flume是否安装成功
flume-ng version
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f
成功
4, 使用
flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
flume的一些核心概念:
- Agent 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
- Client 生产数据,运行在一个独立的线程。
- Source 从Client收集数据,传递给Channel。
- Sink 从Channel收集数据,运行在一个独立线程。
- Channel 连接 sources 和 sinks ,这个有点像一个队列。
- Events 可以是日志记录、 avro 对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
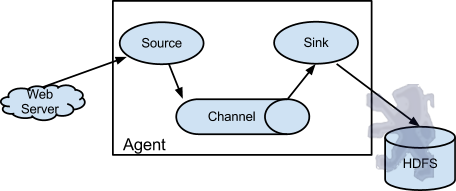
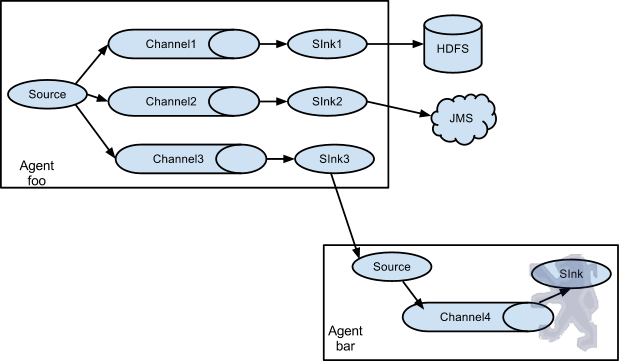
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes
创建conf文件,命名example.conf
内容:
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume:
root@Ubuntu-:/usr/local/apache-flume#bin/flume -ng --conf conf/ --conf-file conf/example.conf --name a1 -Dflume.monitoring.type=http -Dflume.monitoring port= -Dflume.root.logger=INFO,console &
另外打开一个shell窗口,输入
telnet 0.0.0.0
如果要关闭telnet窗口,用CTRL+] 命令,然后quit退出
------avro 将本地的文件传到flume
首先在131的conf文件下创建avro_source文件
内容如下:
agent1.channels = ch1
agent1.sources = avro-source1
agent1.sinks = log-sink1 # 定义channel
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity =
agent1.channels.ch1.transactionCapacity = # 定义source
agent1.sources.avro-source1.channels = ch1
agent1.sources.avro-source1.type = avro
agent1.sources.avro-source1.bind = 0.0.0.0
agent1.sources.avro-source1.port = # 定义sink
agent1.sinks.log-sink1.channel = ch1
agent1.sinks.log-sink1.type = logger
在131中启动flume进程:
bin/flume-ng agent --conf conf/ --conf-file conf/avro_source.conf --name agent1 -Dflume.root.logger=INFO,console &
在132中,我将131的flume文件拷到了132中,并在132中创建一个avro.log文件,其中有一些数据,在132中执行
bin/flume -ng avro-client --host 192.168.22.131 --port --filename /usr/local/apache-flume/logs/avro.log
这样便将132的本地文件中的数据打到了131中
----------------------------------------------------------------------------------------------------------------------------------q
切记:!!我131中的JDK后来改成了1.8,但是132中一直是1.7版本的,所以不要混淆了
Flume的安装,配置及使用的更多相关文章
- Flume的安装配置
flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本.HDF ...
- Flume 组件安装配置
下载和解压 Flume 实验环境可能需要回至第四,五,六章(hadoop和hive),否则后面传输数据可能报错(猜测)! 可 以 从 官 网 下 载 Flume 组 件 安 装 包 , 下 载 地 址 ...
- Flume的安装与配置
Flume的安装与配置 一. 资源下载 资源地址:http://flume.apache.org/download.html 程序地址:http://apache.fayea.com/fl ...
- 01 Flume系列(一)安装配置
01 Flume系列(一)安装配置 Flume(http://flume.apache.org/) is a distributed, reliable, and available service ...
- 具体图解 Flume介绍、安装配置
写在前面一: 本文总结"Hadoop生态系统"中的当中一员--Apache Flume 写在前面二: 所用软件说明: 一.什么是Apache Flume 官网:Flume is a ...
- Linux安装配置Flume
概述 Apache Flume是一个分布式,可靠且可用的系统,用于高效地收集,汇总和将来自多个不同源的大量日志数据移动到集中式数据存储.Apache Flume的使用不仅限于日志数据聚合.由于数据源是 ...
- Flume负载均衡配置
flume负载均衡配置 集群DNS配置如下: hadoop-maser 192.168.177.162 machine-0192.168.177.158 machine-1191.168.177.16 ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Flume 概述+环境配置+监听Hive日志信息并写入到hdfs
Flume介绍Flume是Apache基金会组织的一个提供的高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供 ...
随机推荐
- XStream轻松转换xml和java对象
首先引入所需的jar: xstream-1.4.9.xpp3_min-1.1.4c.dom4j-1.6.1, 或用maven管理jar包时在pom.xml中添加: <!-- https://mv ...
- jq 一个强悍的json格式化查看工具
本文来自网易云社区 作者:娄超 在web 2.0时代json这种直观.灵活.高效数据格式基本已经成为一种标准格式,从各种web api,到配置文件,甚至现在连mysql都开始支持json作为数据类型. ...
- ABP框架设置默认语言
在Global.asax文件中设置 private readonly IAbpWebLocalizationConfiguration _webLocalizationConfiguration; p ...
- 项目总结(二)->一些常用的工具浅谈
程序员是否应该沉迷于一个编程的世界,为了磨砺自己的编程技能而两耳不闻窗外事,一心只为写代码:还是说要做到各有涉猎,全而不精.关于这点每个人心中都有一套自己的工作体系和方法体系. 我一直认为,程序员你首 ...
- 「日常训练」Common Subexpression Elimination(UVa-12219)
今天做的题目就是抱佛脚2333 懂的都懂. 这条题目干了好几天,最后还是参考别人的代码敲出来了,但是自己独立思考了两天多,还是有收获的. 思路分析 做这条题我是先按照之前的那条题目(The SetSt ...
- Qt 绘制汽车仪表 指针旋转锯齿问题
在前面几篇中出现的问题 http://blog.csdn.net/z609932088/article/details/53946245 这个是在QWidget下绘制的,出现了指针有锯齿的问题 后面开 ...
- jmeter接口测试--获取token
Jmeter进行接口测试-提取token 项目一般都需要进行登陆才能进行后续的操作,登陆有时发送的请求会带有token,因此, 需要使用后置处理器中的正则表达式提取token,然后用BeanShell ...
- 树莓派3_win10下使用"远程桌面连接"与树莓派通信(使用VNC实现连接后)
-----------------------------------------------------------学无止境------------------------------------- ...
- 【转】ASP.NET Core WebApi使用Swagger生成api说明文档看这篇就够了
原文链接:https://www.cnblogs.com/yilezhu/p/9241261.html 引言 在使用asp.net core 进行api开发完成后,书写api说明文档对于程序员来说想必 ...
- react实现网站换肤功能
一.目标 提供几种主题色给用户选择,然后根据用户的选择改变应用的主题色: 二.实现原理 1.准备不同主题色的样式文件: 2.将用户的选择记录在本地缓存中: 3.每次进入应用时,读取缓存 ...