【APUE】Chapter3 File I/O
这章主要讲了几类unbuffered I/O函数的用法和设计思路。
3.2 File Descriptors
fd本质上是非负整数,当我们执行open或create的时候,kernel向进程返回一个fd。
unix系统中有几个特殊的fd:
0:standard input
1:standard output
2:standard error
这几个带有特殊含义的整数都有对应的可读性强的符号表示:STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO
具体的定义都包含在unistd.h头文件中:

3.3 open & openat Functions
int open(const char *path, int oflag, ...)
返回值为file descriptor
其中oflag中包含各种选项的组合;并要求“只读、只写、读写、搜索、执行”这五类选项必须有且只有一个。
open函数还有一个特性:通过open或者openat返回的file descriptor一定保证是可用的最小的descriptor。写一个小栗子如下:
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h> int main(void)
{
int val1 = open("test_fd1",O_CREAT);
printf("fd:%d\n",val1);
int val2 = open("test_fd2",O_CREAT);
printf("fd:%d\n",val2);
exit();
}
编译运行后如下:
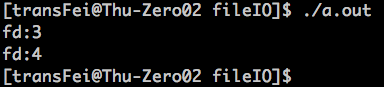
由于0,1,2都有特殊的含义,所以后开的两个file descriptor为3、4。
书上还提到了文件名长度的问题:如果是比较老的一些系统,文件名的长度超过了14,则系统可能把超过14个长度的部分截断了。
3.4 create Function
3.5 close Function
关闭file deescriptor,一旦被close了,那么Process中各种加在这个文件上的锁也就被release了。
3.6 lseek Function
与文件偏移量有关。
off_t lseek(int fd, off_t offset, int whence)
如果成功返回new file offset,如果失败则返回-1
具体执行什么操作需要根据whence参数来确定:
SEEK_SET:重置file的偏移量为参数中offset的值
SEEK_CUR:设置file的偏移量为当前偏移量+offset的值,这里offset可正可负
SEEK_END:设置file的偏移量为当前文件的size+offset的值,这里offset依然可正可负
如果要判断文件的当前偏移量,lseek(fd, 0, SEEK_CUR)即可。
lseek还可以判断当前的file是否能够被seeking(比如pipe FIFO或socket就不能够)代码如下:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h> int main()
{
if (lseek(STDIN_FILENO,,SEEK_CUR)==-) {
printf("cannot seek\n");
}
else {
printf("seek OK\n");
}
exit();
}
执行结果如下:

从文件来的file descriptor就可以seek;从pipie来的file descriptor就不能够seek。
上述的代码用lseek是否返回负1来判断是否成功,那么是否判断lseek是否为负数就可以知道是否成功了呢?
书上说这样做的是不安全的,因为有些文件偏移量是允许为负数的。
这里有一个问题,如果lseek操作后,文件的偏移量超过了文件的size怎么办?这种情况也是允许的,如果偏移量超过了文件的size,那么执行write操作就会将文件的size扩展,并且中间没有执行写操作的部分被灌以空白字符代替。例子如下:
#include "apue.h"
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h> char buf1[] = "abcdefghij";
char buf2[] = "ABCDEFGHIJ"; int main()
{
int fd;
fd = creat("file.hole", FILE_MODE);
write(fd, buf1, );
lseek(fd, , SEEK_SET); /*offset now = 16384*/
write(fd, buf2, ); /*offset now = 16394*/
exit();
}
运行结果如下:

文件大小是16394,文件的size被扩展了。
既然文件能够随着lseek而自动扩充size,那么这种扩充是不是无限的?并不是无限的。
书上说大多数操作系统,提供了两种方式操作file offsets:一种是32 bits offsets,另一种是64 bits offsets。
2^32 = 4GB ,我猜这也就是为什么比较老的文件系统最大单个文件只能支持4GB的原因了
2^64 = 非常大的GB
但是,即使系统提供了32 & 64两种文件偏移量接口,但是最终能够支持多大的单体文件,还需要结合底层文件系统。
3.7 read Function
ssize_t read(int fd, void *buf, size_t nbytes)
read的操作从文件当前的offset执行,read返回前文件的offset会增加,增加的值就是读入的bytes数;返回的是读入的bytes数。
一般来说,read读入的bytes数就是nbytes;但有如下几种情况实际读入的bytes是要小于nbytes的:
(1)如果是regular file,并且文件已经读到头了
(2)read from terminal device
(3)read from a network
(4)read from pipe of FIFO
(5)interrupted by a signal and a partial amount of data has already been read
3.8 write Function
3.9 I/O Efficiency
书上列了这么一段程序:
#include "apue.h" #define BUFFSIZE 4096 int
main(void)
{
int n;
char buf[BUFFSIZE]; while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > )
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error"); if (n < )
err_sys("read error"); exit();
}
上述的代码主要测试BUFFSIZE的大小与读写的效率,主要利用Linux Shell的测试的效率。
准备了一个504M的文本文件,如下:

用如下命令测试不同BUFFERSIZE下的读写时间:
time -p ./a.out < ./loadlog_tsinghua.txt > o
先经过标准输入读入txt文件,再经过标准输出写入文件o中。
测试BUFFSIZE为不同的值:
524288
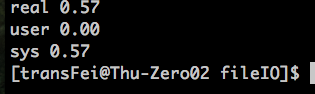
8192

4096
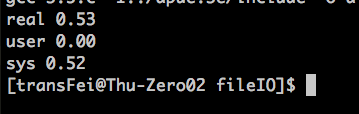
2048

1024
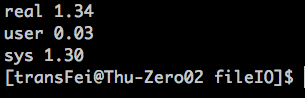
32
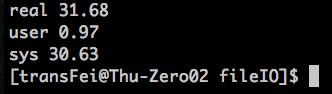
通过上述的比较,选择一个合适的buffer size是可以提高读写效率的。
最优的读写速度集中在4096这个buffer size左右,这个与测试的linux环境系统的block size有关系。
3.10 File Sharing
这个部分主要针对这样一个问题:不同的process可能对同一个文件进程写或者读操作;假设上述操作都是可行的,那么背后的机制大概是什么样的。
书上举了一个一般性的文件共享结构(可能与实际的不完全相同,但是可以帮助理解原理)
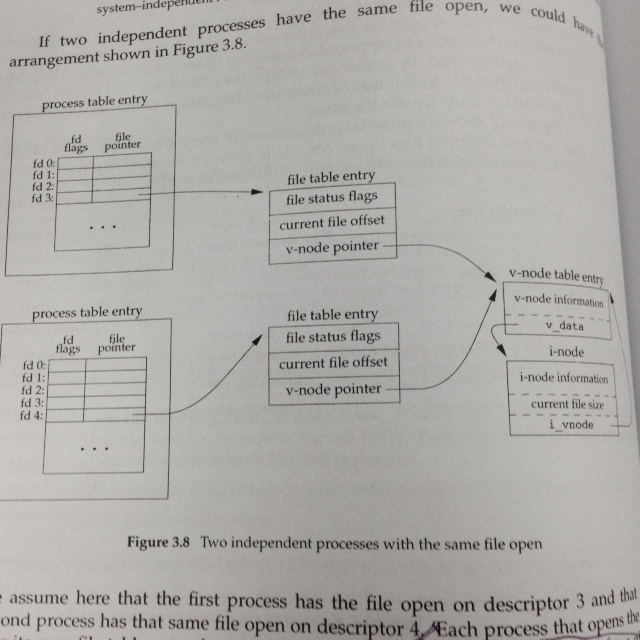
(1)每个进程都有一个process table entry,里面的内容都是file descriptos
(2)每个file descriptor中包含两部分内容:
a. fd flags:文件操作方式
b. file pointer:指向一个file table entry
(3)每个file table entry中包含如下的内容:
a. file status flags:指的是read, write, append, sync, nonblocking等
b. 当前的文件offset
c. 指向v-node table entry的指针
通过上面的结构分析:一个文件只能有一个v-node table entry;但是不同的file descritpor指向同一个v-node table entry。这样就实现了文件在不同进程中的共享。
通过上述的结构,重新分析之前提到的几个读写操作函数:
(1)执行了write操作后,current file offset增加的数量就是写入的数量
(2)如果文件以O_APPEND的flag被打开,执行了write的时候,current file offset先从i-node中获取当前文件的size,然后再执行write操作,这样就保证了一定是append的
(3)lseek的操作只修改了file table entry中的current file offset,并不会产生I/O操作
除此之外,还有一个问题需要注意:可以有多个file descriptor指向同一个file table entry的(详情见dup函数);因此也带来一个问题,process table entry中的file flags和file table entry中的file status flags的影响面是不同的:
(1)file flags影响的只是单个进程中的单个file descriptor
(2)file status flags影响的是所有连到这个file table entry的进程的fd
如何对file descriptor flags和file status flags都进行有效的操作呢?这就里就有一个管家级的函数fcntl,后面会提到。
3.11 Atomic Operations
原子操作这个概念之前就见过了,书上给出了更好的定义:指的是包含好几步的operation,要么一起执行完了,要么都不执行,不存在只执行了部分步骤的过程。
这部分只给出了简单的例子,多个process对同一个文件执行写操作,那么就容易产生不同步的现象。
或者两个进程都要对同一个文件执行append的操作:之前说过了append必然要经过lseek的过程,这里就可能存在不同步。
后续4.15和14.3章节会给出更具体的例子。
3.12 dup and dup2 Functions
int dup(int fd)
这个函数的作用是:复制已有的file descriptor。
函数的返回值,还是lowest-numbered available file descriptor。
那么,如果需要指定返回的file descriptor的值怎么办呢?还有另一个类似功能的函数:int dup2(int fd, int fd2)
其中fd2是希望得到的的file descriptor值,分如下几种情况:
(1)如果fd2已经打开了,那么先关上,再返回fd2;此时fd2就与fd指向同一个fie entry table
(2)如果fd与fd2相等,则返回的就是fd2
(3)否则fd2的FD_CLOEXEC fle descriptor flag被清空了
总的来说,最后达到的效果如下图所示:
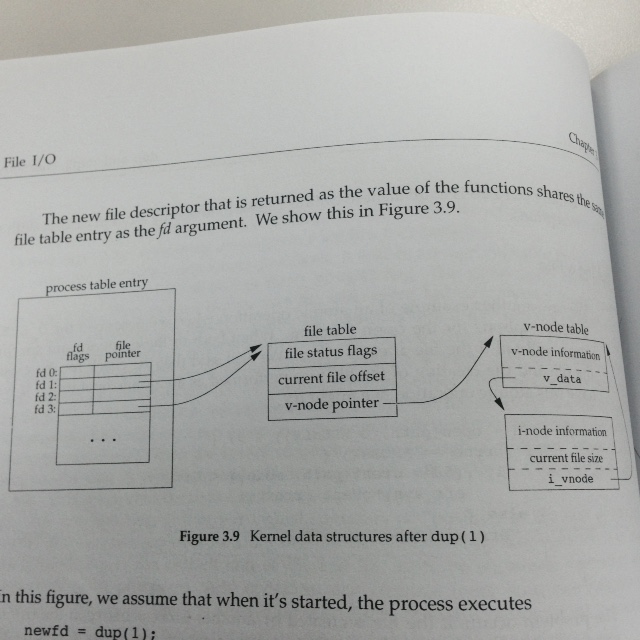
这种情况属于同一个process中对同一个文件产生了不同的file descriptor。
3.13 sync, fsync, and fdatasync Functions
这里先介绍UNIX system的文件系统的一种delay-write的机制:在执行写操作的时候,一般先把内容写到buffer中,再queue到队列中,最后在某个时候把内容写入到disk中。
上面描述的内容的核心就是:这里执行完write操作,并不是等着内容真的写到disk上才返回的;如果需要强写同步的环境,则需要考虑delay-write的影响。为了更好的理解这一部分的几个函数,需要对unix系统io操作的概貌有一个简略的了解。
在网上找了一个有全貌的blog(http://blog.csdn.net/ybxuwei/article/details/22727565)

int sync(void) :
这是一个类似全局update催促函数,把kernel's blocks buffer(内核缓冲区)flush,但是不等待write完成了再回来。
int fsync(void) :
只针对single file,fsync把kernel's block buffer内容flush,并且必须等着内容写入后才返回,严格写同步。
int fdatasync(void):
跟fsync功能类似,只不过只等着文件数据部分更新,不等着文件属性信息更新完。
3.14 fcntl Function
int fcntl(int fd, int cmd, ... );
这是个比较综合的函数,主要操作与file descriptor相关的内容。
cmd表示命令的格式,由各种宏定义符号表示,比如F_GETFL表示就是返回file descriptor对应的file status flags的值(这里需要注意,file descriptor有个指针指向file table entry, file status flags是属于file table entry里的值;具体见上面的关系图,就可以搞清楚了)
示例代码如下:
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h> int main(int argc, char *argv[])
{
int val;
val = fcntl(atoi(argv[]), F_GETFL, ); /*F_GETFL返回file status flags*/
switch (val & O_ACCMODE)
{
case O_RDONLY:
printf("read only");
break;
case O_WRONLY:
printf("write only");
break;
case O_RDWR:
printf("read write");
break;
default:
printf("error\n");
}
if (val & O_APPEND) {
printf(", append");
}
if (val & O_NONBLOCK) {
printf(", nonblcking");
}
if (val & O_SYNC) {
printf(", synchronous writes");
}
putchar('\n');
exit();
}
代码执行结果如下:
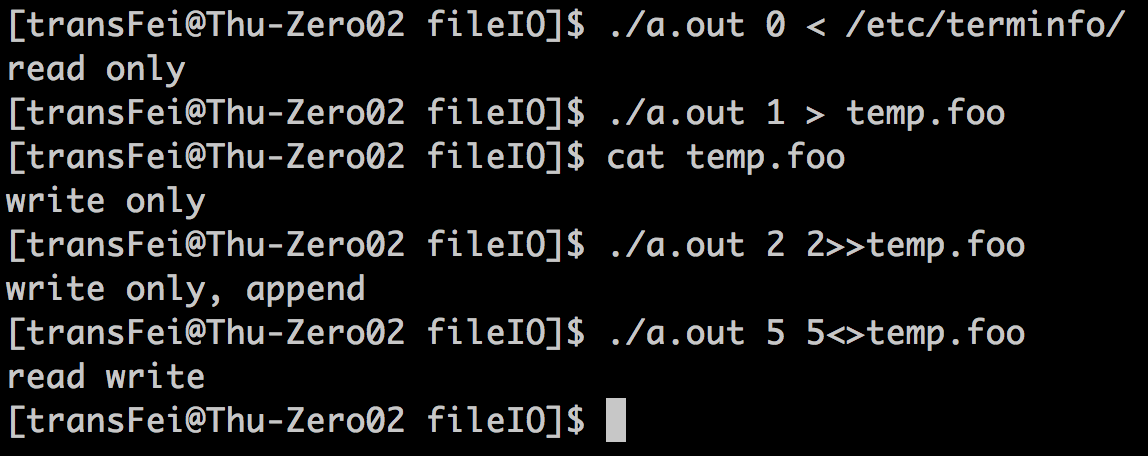
上面的例子体验了一下fcntl操作file descriptor的效果。
书上在这一部分还对delay-write的机制进行了讨论,如果用同步机制fsync会造成什么影响。
修改3.5.c的代码如下(主要功能还是从STDIN读再从STDOUT写,测试读写时间):
#include "apue.h"
#include <unistd.h>
#include <stdlib.h>
#include <errno.h>
#include <fcntl.h> #define BUFFSIZE 524288 void set_fl(int fd, int flags)
{
int val;
if ((val=fcntl(fd, F_GETFL,))<) {
err_sys("fcntl F_GETFL error");
}
val |= flags;
if (fcntl(fd, F_GETFL, val)<) {
err_sys("fcntl F_GETFL error");
}
} int main(int argc, char *argv[])
{
/*set_fl(STDOUT_FILENO, O_SYNC);*/
int n;
char buf[BUFFSIZE]; while ((n=read(STDIN_FILENO, buf, BUFFSIZE))>) {
write(STDOUT_FILENO, buf, n);
fsync(STDOUT_FILENO);
}
if (n<) {
err_sys("read error");
}
}
这部分代码主要增加了write同步的功能,有两种实现方法:
(1)利用fcntl函数设置O_SYNC的flags
(2)更直接一些,直接在每次执行write紧跟着调用fsync(fd)
另外还有一个因素是BUFFSIZE取多少的问题,我们下面一个个分类讨论。
1. 测试O_SYNC是否有用?
这个不上图了,经过测试,把O_SYNC设置上了,并没有对读写速度造成影响。
2. 测试fsync是否会对执行速度造成影响?
首先将BUFFSIZE设为4096,执行的时间太长了,没等到执行完,截图如下:

我们做实验的文件大小是504M而每次写的buffer是0.004M,这样需要等待的次数是巨大的。最起码在我实验的系统上是等不起这样的同步的。
如果我们只等数据呢?把fdatasync(fd)呢?效果还是然并卵,所以这样的方式真的是不科学的。
下面再把BUFFSIZE的数值改到比较大的524,288,结果如下:

最起码说明,如果BUFFSIZE比较大的时候,因为同步等待的次数少了(504M的文件大小0.524M的buffer已经可以比4096可以接受的多了)
看书看到这里,大概了解了为什么要有delay-write的机制,还有之前提到的缓存机制。
这一章开头的说的read() write()是unbuffered I/O并不是完全真的不带缓存,直接往disk上干:而是说在用户层没有缓存;这二者在kernel层还是设有缓存的。比如,kernel的缓存是100byte,每次write写的是10byte,则把kernel的缓存写了10次满了之后,才真的输出到disk上。如果在用户层增加一个缓存层,50bytes为buffer size,则系统层调用两次write就可以执行真正的I/O操作了,减少了调用调用wrtie()次数。
对于这个问题,还需要后面的章节继续加深理解;
目前搜到了这篇文章,讲的比较透彻(http://www.360doc.com/content/11/0521/11/5455634_118306098.shtml)
【APUE】Chapter3 File I/O的更多相关文章
- 【APUE】Chapter4 File and Directories
4.1 Introduction unix的文件.目录都被当成文件来看待(vi也可以编辑目录):我猜这样把一起内容都当成文件的原因是便于统一管理权限这类的内容 4.2 stat, fstat, fst ...
- 【APUE】Chapter10 Signals
Signal主要分两大部分: A. 什么是Signal,有哪些Signal,都是干什么使的. B. 列举了非常多不正确(不可靠)的处理Signal的方式,以及怎么样设计来避免这些错误出现. 10.2 ...
- 【python】类file文件处理
[flush方法] 通常由于缓冲,write不将数据写入文件,而是写入内存的缓冲区,需要使用flush写入文件,并清空缓冲区 文件的flush方法的作用是强制清空缓存写入文件.默认每行flush一下? ...
- 【APUE】Chapter16 Network IPC: Sockets & makefile写法学习
16.1 Introduction Chapter15讲的是同一个machine之间不同进程的通信,这一章内容是不同machine之间通过network通信,切入点是socket. 16.2 Sock ...
- 【APUE】Chapter5 Standard I/O Library
5.1 Introduction 这章介绍的standard I/O都是ISOC标准的.用这些standard I/O可以不用考虑一些buffer allocation.I/O optimal-siz ...
- 【APUE】Chapter17 Advanced IPC & sign extension & 结构体内存对齐
17.1 Introduction 这一章主要讲了UNIX Domain Sockets这样的进程间通讯方式,并列举了具体的几个例子. 17.2 UNIX Domain Sockets 这是一种特殊s ...
- 【APUE】Chapter15 Interprocess Communication
15.1 Introduction 这部分太多概念我不了解.只看懂了最后一段,进程间通信(IPC)内容被组织成了三个部分: (1)classical IPC : pipes, FIFOs, messa ...
- 【APUE】Chapter14 Advanced I/O
14.1 Introduction 这一章介绍的内容主要有nonblocking I/O, record locking, I/O multiplexing, asynchronous I/O, th ...
- 【APUE】Chapter1 UNIX System Overview
这章内容就是“provides a whirlwind tour of the UNIX System from a programmer's perspective”. 其实在看这章内容的时候,已经 ...
随机推荐
- 二分图最大权值匹配 KM算法 模板
KM算法详解+模板 大佬讲的太好了!!!太好了!!! 转载自:http://www.cnblogs.com/wenruo/p/5264235.html KM算法用来求二分图最大权完美匹配. 本文配合该 ...
- ms17_010利用复现(32位)
准备阶段: 1,原版windows7:cn_windows_7_enterprise_x86_dvd_x15-70737.iso 2,kali系统, 虚拟机 3,用于32位机的攻击模块:Eterna ...
- 2018.9.28 典型for循环特殊理解及其二维数组的理解
如果for里面换成了函数结果会是怎么样呢?下面就来介绍一下 package praDemo; public class Test { public static boolean foo(char c) ...
- Jquery Mobile 常用参数
data-role 属性值: data-role参数表: page 页面容器,其内部的mobile元素将会继承这个容器上所设置的属性 header 页面标题容器,这个容器内部 ...
- 让IIS支持无后缀名访问
IIS中添加对Mime类型 . application/octet-stream
- LeetCode12.整数转罗马数字 JavaScript
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 写做 II ,即为两个并 ...
- SQL on&where&having
on.where.having这三个都可以加条件的子句中,on是最先执行,where次之,having最后.有时候如果这先后顺序不影响中间结果的话,那最终结果是相同的.但因为on是先把不符合条件的记录 ...
- Swift_控制流
Swift_控制流 点击查看源码 for-in 循环 //for-in 循环 fileprivate func testForIn() { //直接循环提取内部数据 //[1,5] for index ...
- 【模板】概率dp
有n个投资事件,和一个成功概率最低接受值rate.每个投资的价值是c[i],成功概率是p[i](浮点数). 在保证成功概率≥rate的情况下,使价值最大化. #include<bits/stdc ...
- 【例题收藏】◇例题·6◇ 电压机制(voltage)
◆例题·6◆ 电压机制 周六日常模拟赛……已经不知道该说什么了(感觉做不出来的都是好题) ▷ 题目 (终于不用自己翻译英文题了╮(╯-╰)╭) [问题描述] 科学家在“无限神机”(Infinity M ...