Spark学习之Spark Streaming
一、简介
许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用、训练机器学习模型的应用,还有自动检测异常的应用。Spark Streaming 是 Spark 为这些应用而设计的模型。它允许用户使用一套和批处理非常接近的 API 来编写流式计算应用,这样就可以大量重用批处理应用的技术甚至代码。
和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
和批处理程序不同,Spark Streaming 应用需要进行额外配置来保证 24/7 不间断工作。Spark Streaming 的检查点(checkpointing)机制,也就是把数据存储到可靠文件系统(比如 HDFS)上的机制,这也是 Spark Streaming 用来实现不间断工作的主要方式。
二、一个简单的例子
我们会从一台服务器的 9999 端口上实时输入数据,并在控制台打印出来。
首先,你得有一个nc软件,因为我是在window下运行程序的,但是在Linux系统里面就不需要,Linux里面有内置的nc命令。

nc软件的用法:
开一个命令行窗口(这里要切换到nc软件的路径下):
服务端:nc –lp 9999
//客户端:nc localhost 9999
nc软件启动成功的界面:
然后就是一个简单的Spark Streaming的代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Duration
import org.apache.spark.streaming.Seconds object Test {
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("test").setMaster("local[4]")
// 从SparkConf创建StreamingContex并指定4秒钟的批处理大小
// 用来指定多长时间处理一次新数据的批次间隔(batch interval)作为输入
val ssc = new StreamingContext(conf,Seconds(4))
// 连接到本地机器9999端口
val lines = ssc.socketTextStream("localhost", 9999)
lines.print() // 启动流式计算环境StreamingContext并等待它"完成"
ssc.start()
// 等待作业完成
ssc.awaitTermination() }
}
连接成功的界面:
然后我在刚才的界面输入"Hello world",然后就会在控制台界面打印出来。

三、架构与抽象
Spark Streaming 使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming 从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在 500 毫秒到几秒之间,由应用开发者配置。每个输入批次都形成一个 RDD,以 Spark 作业的方式处理并生成其他的 RDD。处理的结果可以以批处理的方式传给外部系统。


四、检查点机制
Spark Streaming 对 DStream 提供的容错性与 Spark 为 RDD 所提供的容错性一致:只要输入数据还在,它就可以使用 RDD 谱系重算出任意状态(比如重新执行处理输入数据的操作)。默认情况下,收到的数据分别存在于两个节点上,这样 Spark 可以容忍一个工作节点的故障。不过,如果只用谱系图来恢复的话,重算有可能会花很长时间,因为需要处理从程序启动以来的所有数据。因此,Spark Streaming 也提供了检查点机制,可以把状态阶段性地存储到可靠文件系统中(例如 HDFS 或者 S3)。一般来说,你需要每处理 5-10 个批次的数据就保存一次。在恢复数据时,Spark Streaming 只需要回溯到上一个检查点即可。
如果流计算应用中的驱动器程序崩溃了,还可以重启驱动器程序并让驱动器程序从检查点恢复,这样 Spark Streaming 就可以读取之前运行的程序处理数据的进度,并从那里继续。
ssc.checkpoint("hdfs://...")
五、转化操作
DStream 的转化操作可以分为无状态(stateless)和有状态(stateful)两种。
• 在无状态转化操作中,每个批次的处理不依赖于之前批次的数据。常见的RDD转化操作,例如 map() 、 filter() 、 reduceByKey() 等,都是无状态转化操作,无状态转化操作是分别应用到每个 RDD 上的。
• 相对地,有状态转化操作需要使用之前批次的数据或者是中间结果来计算当前批次的数据。有状态转化操作包括基于滑动窗口的转化操作和追踪状态变化的转化操作。

DStream 的有状态转化操作是跨时间区间跟踪数据的操作;也就是说,一些先前批次的数据也被用来在新的批次中计算结果。主要的两种类型是滑动窗口和 updateStateByKey() ,前者以一个时间阶段为滑动窗口进行操作,后者则用来跟踪每个键的状态变化(例如构建一个代表用户会话的对象)。有状态转化操作需要在你的 StreamingContext 中打开检查点机制来确保容错性。
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果,就应该把滑动步长设置为 20 秒。
对 DStream 可以用的最简单窗口操作是 window() ,它返回一个新的 DStream 来表示所请求的窗口操作的结果数据。换句话说, window() 生成的 DStream 中的每个 RDD 会包含多个批次中的数据,可以对这些数据进行 count() 、 transform() 等操作。
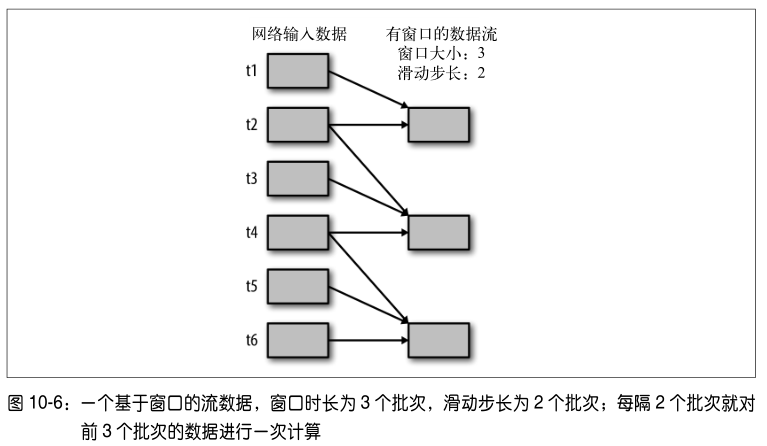
lines.window(windowDuration, slideDuration)
lines.reduceByWindow(reduceFunc, windowDuration, slideDuration)
有时,我们需要在 DStream 中跨批次维护状态(例如跟踪用户访问网站的会话)。针对这种情况, updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态)对。例如,在网络服务器日志中,事件可能是对网站的访问,此时键是用户的 ID。使用updateStateByKey() 可以跟踪每个用户最近访问的 10 个页面。这个列表就是“状态”对象,我们会在每个事件到来时更新这个状态。
六、输出输入操作
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream都没有被执行输出操作,那么这些 DStream 就都不会被求值。如果StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
在 Scala 中将 DStream 保存为文本文件
ipAddressRequestCount.saveAsTextFiles("outputDir", "txt")
因为 Spark 支持从任意 Hadoop 兼容的文件系统中读取数据,所以 Spark Streaming 也就支持从任意 Hadoop 兼容的文件系统目录中的文件创建数据流。
val line = ssc.textFileStream("directory")
这篇博文主要来自《Spark快速大数据分析》这本书里面的第十章,内容有删减,还有本书的一些代码的实验结果。
Spark学习之Spark Streaming的更多相关文章
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- Spark学习一:Spark概述
1.1 什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. 一站式管理大数据的所有场景(批处理,流处理,sql) spark不涉及到数据的存储,只 ...
- Spark学习之Spark安装
Spark安装 spark运行环境 spark是Scala写的,运行在jvm上,运行环境为java7+ 如果使用Python的API ,需要使用Python2.6+或者Python3.4+ Spark ...
- Spark学习(一) Spark初识
一.官网介绍 1.什么是Spark 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于A ...
- Spark学习之Spark调优与调试(二)
下面来看看更复杂的情况,比如,当调度器进行流水线执行(pipelining),或把多个 RDD 合并到一个步骤中时.当RDD 不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行.上一 ...
- Spark学习之Spark调优与调试(一)
一.使用SparkConf配置Spark 对 Spark 进行性能调优,通常就是修改 Spark 应用的运行时配置选项.Spark 中最主要的配置机制是通过 SparkConf 类对 Spark 进行 ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- Spark学习笔记--Spark在Windows下的环境搭建(转)
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
随机推荐
- Docker 三剑客之 Docker Swarm(基于 overlay 组网通信)
相关文章:Docker 三剑客之 Docker Swarm 这一篇主要是对 Docker Swarm 的完善,增加基于 overlay 组网通信,以便 Docker 容器可以跨主机访问. 不同主机间的 ...
- SpringBoot框架Scheduled注入参数说明
注解 @Scheduled(cron = "0/5 * * * * ?") @Scheduled(fixedDelay = 1000 * 7,initialDelay=1000*1 ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- CRM客户关系管理系统(九)
第九章.filter_horizontal优化和kingadmin删除功能 9.1.filter_horizontal优化 (1)添加Choose ALL 和Remove ALL table_obj_ ...
- 洛谷 P1054 解题报告
P1054 等价表达式 题目描述 明明进了中学之后,学到了代数表达式.有一天,他碰到一个很麻烦的选择题.这个题目的题干中首先给出了一个代数表达式,然后列出了若干选项,每个选项也是一个代数表达式,题目的 ...
- mondrian 4.7 源码部署
mondrian是一个开源的数据分析工程, 网上有关mondrian3.X的源码部署比较多, 有关4.X的部署较少. 目前官方推荐使用的时mondrian3.7的修订版, 可以再github上下载到最 ...
- Cookie与 Session使用详解
Cookie概念 在浏览某些 网站 时,这些网站会把 一些数据存在 客户端 , 用于使用网站 等跟踪用户,实现用户自定义 功能. 是否设置过期时间: 如果不设置 过期时间,则表示这个 Cookie生命 ...
- http响应结构分析
HTTP响应由三个部分组成: 1.状态码(Status Code): 描述了响应的状态.可以用来检查是否成功的完成了请求.请求失败的情况下,状态码可用来找出失败的原因.如果Servlet没有返回状态码 ...
- Linux内存使用情况以及内存泄露分析之工具与方法
<Linux C/C++ Memory Leak Detection Tool> 1. 内存使用情况分析 1.1 系统总内存分析 通过cat /proc/meminfo,可用的物理内存=M ...
- 在Linux上使用PGP签名验证文件完整性
文件在下载及存储过程中可能由于传输错误.硬件故障.文件系统错误等网络.硬件和软件方面的原因导致文件损坏,也可能在传输过程中受到攻击(如"中间人攻击")导致下载的文件被篡改或者下载到 ...