Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考
主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过于复杂,先完成一个小目标
环境:
python 3.6
主要问题:
1. 在爬取美团黄山酒店第一页后,顺利拿到想要的信息,但在点击第二页后,chrome中检查信息能够看见想要的信息,但是查看源代码却没有,思考后,应该是Ajax动态获取的,然后查找办法,最终通过selenium模拟浏览器,然后进行爬取
2. 标签查找,通过chrome进行分析整体网站标签信息后,对某一个标签的class未清楚认识,导致错误认识,消耗比较长的调试时间
代码如下:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import xlwt url = 'http://hotel.meituan.com/huangshan/' #获取酒店分页信息,返回最大页码
def get_page_num(url):
html = requests.get(url).text
soup = BeautifulSoup(html,'lxml')
page_info = soup.find_all('li',class_='page-link') #获取酒店首页的页面导航条信息
page_num = page_info[-1].find('a').get_text() #获取酒店页面的总页数
return int(page_num) #返回酒店页面的总页数 #获取所有酒店详细信息,包含酒店名称,链接,地址,评分,消费人数,价格,上次预定时间
def get_hotel_info(url):
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36') #设置userAgent,可以从浏览器中找到,用于反爬虫禁止IP
browser = webdriver.PhantomJS("/Users/chenglv/phantomjs-2.1.1-macosx/bin/phantomjs", desired_capabilities=dcap) #指定phantomjs程序路径
browser.get(url)
hotel_info = {}
hotel_id = ['酒店名','网址','酒店地址','评价','消费人数','价格','上次预约时间']
col_num = 1
page_num = 1 book = xlwt.Workbook(encoding='utf-8',style_compression=0) #创建excel文件
sheet = book.add_sheet('hotel_info',cell_overwrite_ok=True) #创建excel sheet表单 for i in range(len(hotel_id)): #写入表单第一行,即列名称
sheet.write(0,i,hotel_id[i]) #excel中写入第一行列名 while(page_num < get_page_num(url)+1): #获取一个页面的所有酒店信息
for item in browser.find_elements_by_class_name('info-wrapper'):
hotel_info['name'] = item.find_element_by_class_name('poi-title').text
hotel_info['link'] = item.find_element_by_class_name('poi-title').get_attribute('href')
hotel_info['address'] = item.find_element_by_class_name('poi-address').text.split(' ')[1]
hotel_info['star'] = item.find_element_by_class_name('poi-grade').text
hotel_info['consumers'] = item.find_element_by_class_name('poi-buy-num').text
hotel_info['price'] = item.find_element_by_class_name('poi-price').text
hotel_info['last_order_time'] = item.find_element_by_class_name('last-order-time').text #将当前页面中的酒店信息获取到后,写入excel的行中
for i in range(len(hotel_info.values())):
sheet.write(col_num,i,list(hotel_info.values())[i])
col_num+=1 browser.find_element_by_class_name('paginator').find_element_by_class_name('next').find_element_by_tag_name('a').click() #一个页面写完后,通过点击"下一页"图标至下一页,继续获取
page_num += 1
book.save('hotel_info_huangshan.csv') def main():
get_hotel_info(url) if '__main__' == __name__:
main()
运行后结果如下图:
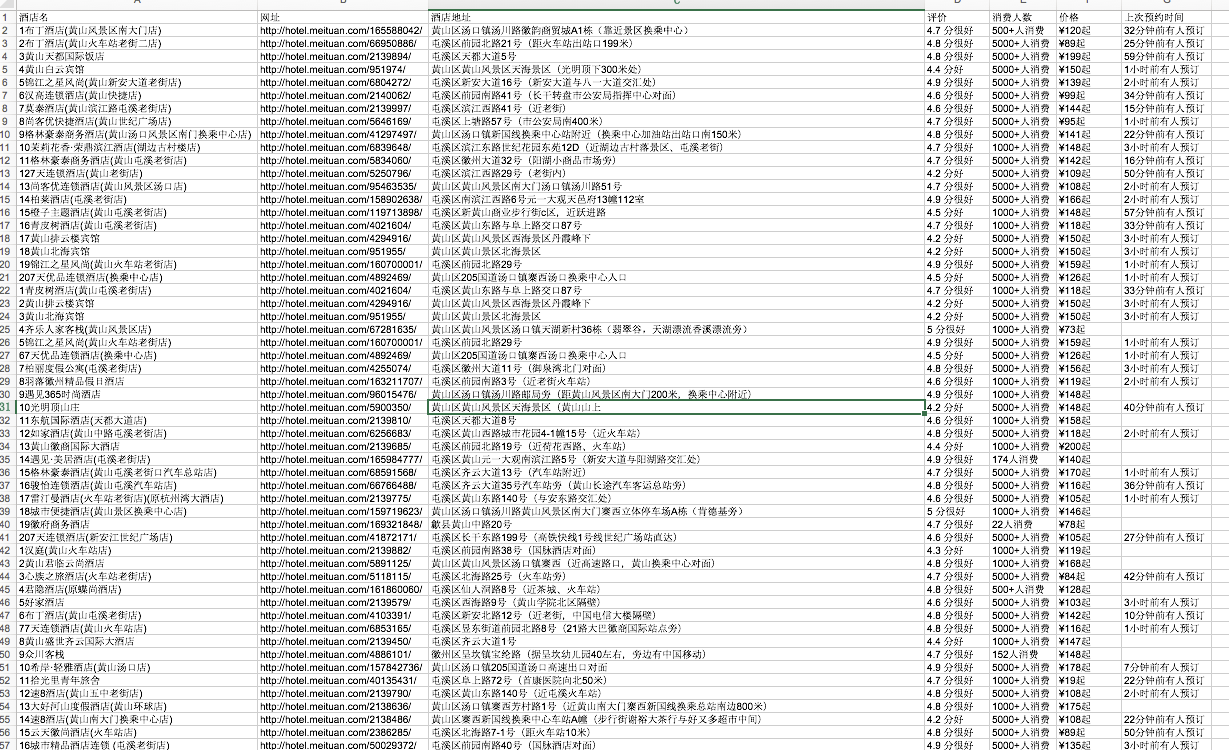
此部分仅因兴趣编写,还有很多未考虑,后期可以进行多层爬取,以及爬取更多的内容。
Python 爬取美团酒店信息的更多相关文章
- python爬取“美团美食”汕头地区的所有店铺信息
一.目的 获取美团美食每个店铺所有的评论信息,并保存到数据库和本地 二.实现步骤 获取所有店铺的poiId 首先观察详情页的url,后面是跟着一串数字的,而这一串数字代表着每个店铺特有的id号,我们称 ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 使用python抓取美团商家信息
抓取美团商家信息 import requests from bs4 import BeautifulSoup import json url = 'http://bj.meituan.com/' ur ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取梦幻西游召唤兽资质信息(不包含变异)
一.分析 1.爬取网站:https://xyq.163.com/chongwu/ 2.获取网页源码: request.get("https://xyq.163.com/chongwu/&qu ...
- python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的 ...
- python爬取网业信息案例
需求:爬取网站上的公司信息 代码如下: import json import os import shutil import requests import re import time reques ...
- python爬取电影网站信息
一.爬取前提1)本地安装了mysql数据库 5.6版本2)安装了Python 2.7 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的html内 ...
随机推荐
- Dubbo粗浅记录
这篇博客只是我自己的学习记录,对各位高手怕是没有什么太大的帮助,望高手不吝赐教. 项目的截图如下: 我们使用的主要就是红框里面的. 这里我主要分析两个xml /DubboTest/src/main/r ...
- Android 官方命令深入分析之Android Debug Bridge(adb)
作者:宋志辉 Android Debug Brideg(adb)是一个多用途的命令行工具.可以与Android虚拟机进行通信或连接真机.它同样提供了访问设备shell的高级命令行操作的权限.它是一个包 ...
- 【shell脚本练习】批量添加用户和设置密码
题目 添加9个用户,user101-user109:密码同用户名: 思路 for循环来添加就好了,用户名和密码都可以拼字符串来完成 user10+数字 要判断是否能添加成功,注意非交互模式下修改用户密 ...
- 【一天一道LeetCode】#79. Word Search
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- Linux 学习笔记_12_Windows与Linux文件共享服务_1.1_--Samba(上)
Samba简介:在UNIX系统中,Samba是通过服务器消息块协议(SMB)在网络上的计算机之间,共享文件和打印服务的软件包. SMB简介:Server Message Block,SMB协议是一种服 ...
- 《java入门第一季》之Arrays类
前面介绍了排序问题(见博客http://blog.csdn.net/qq_32059827/article/details/51362390):二分查找问题(见博客http://blog.csdn.n ...
- AndroidBinder进程间通信系统-android学习之旅(86)
目录 前言及知识准备 Service组件结构 Clinet组件结构 与Binder驱动程序交互 总结 Binder进程间通信实例 问题 本次主要介绍Android平台下Binder进程间通信库.所谓通 ...
- libevent之Reactor模式
通过前边的一篇博文轻量级网络库libevent初探,我们知道libevent实际上是封装了不同操作系统下的/dev/poll.kqueue.event ports.select.poll和epoll事 ...
- windows下程序启动检查,只启动一个实例
问题来源:http://bbs.csdn.net/topics/390998279?page=1#post-398983061 // Only_once.cpp : 定义控制台应用程序的入口点. // ...
- oracle临时表空间 ORA-01652:无法通过16(在表空间XXX中)扩展 temp 字段
今天在查数据的时候报错 ORA-01652:无法通过16(在表空间temp1中)扩展 temp 字段 查看表空间使用明细 SELECT b.tablespace, b.segfile# ...