SQL Server索引视图以(物化视图)及索引视图与查询重写
本文出处:http://www.cnblogs.com/wy123/p/6041122.html
经常听Oracle的同学说起来物化视图,物化视图的作用之一就是可以实现查询重写,听起来有一种高大上的感觉,
SQL Server也有类似于Oracle物化视图的功能,只不过叫做索引视图。
说实话,还是物化视图听起来比较合适,与普通视图比,物化视图就是直接将数据存储起来了
SQL Server中的索引视图也具有查询重写的功能,
所谓的查询重写,就是如果符合条件的数据在索引视图上,并且查询列都包含在在索引视图上,此时可以直接通过查询索引视图来替代基于原始表的查询
依旧惯例,先上代码做一个测试环境
--创建两张表,一张表头,一张明细,仅仅作为DEMO使用
CREATE TABLE HeadTable
(
HeadId INT PRIMARY KEY ,
HeadInfo VARCHAR(50) ,
DataStatus TINYINT ,
CreateDate Datetime
)
GO CREATE TABLE DetailTable
(
HeadId INT ,
DetailId INT identity(1,1) PRIMARY KEY ,
DatailInfo VARCHAR(50)
)
GO --写入数据
DECLARE @i int = 0
WHILE @i<200000
BEGIN
INSERT INTO HeadTable values (@i,NEWID(),RAND()*10,GETDATE()-RAND()*100)
INSERT INTO DetailTable(HeadId,DatailInfo) VALUES (@i,NEWID())
SET @i=@i+1
END
GO
索引视图创建
那么如何创建索引视图呢?语法上跟创建普通视图差别不大,但是不允许出现select *,表名上要加上Scheme,因为这里不是专门说索引视图的,细节就不多说了。
CREATE VIEW V_IndexViewTest WITH SCHEMABINDING
AS
SELECT H.HeadId,H.CreateDate,H.DataStatus,D.DetailId,D.DatailInfo
FROM dbo.HeadTable H INNER JOIN
dbo.DetailTable D ON H.HeadId = D.HeadId
WHERE H.DataStatus = 0
GO
索引视图要求创建的第一个列为唯一聚集索引,所以如下,创建一个唯一的聚集索引
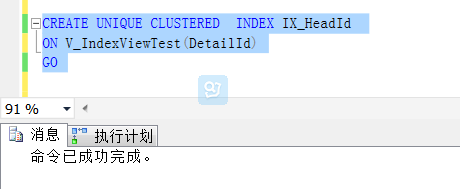
对于其他索引,可以跟在表上创建索引一样
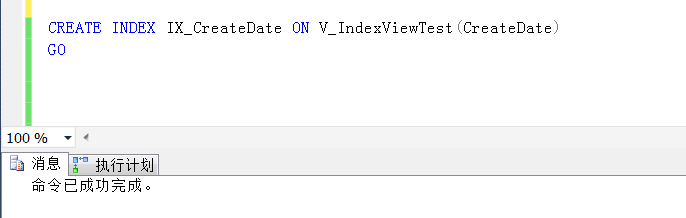
查询重写
上面说了,查询重写就是将基于原始表的查询语句,直接在索引视图上查询实现,那么就来看一下查询重写是什么样子的?
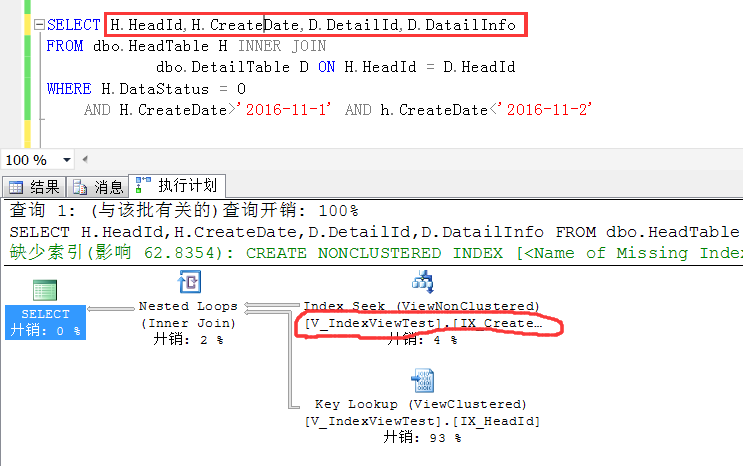
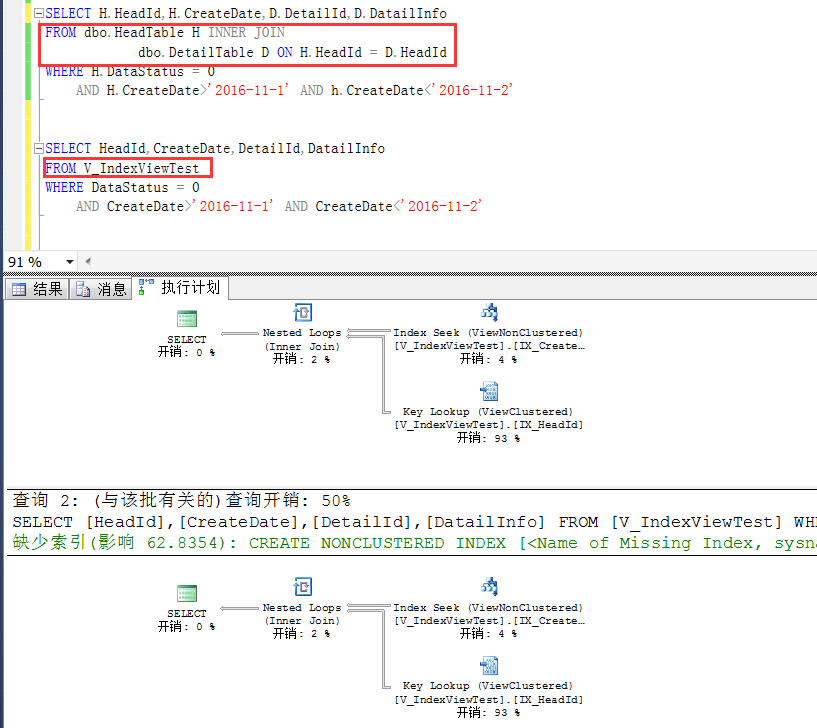
下面来观察这么一个查询,SQL很明显地是基于原始表做的查询,跟普通查询并无二致,
但是观察执行计划就会发现:
这个执行计划走了一个索引查找,首先很清楚,HeadTable上的CreateDate是没有索引的,这里走的索引就是V_IndexViewTest上的CreatDate列上的索引
也就是在索引视图上创建的第二个索引。
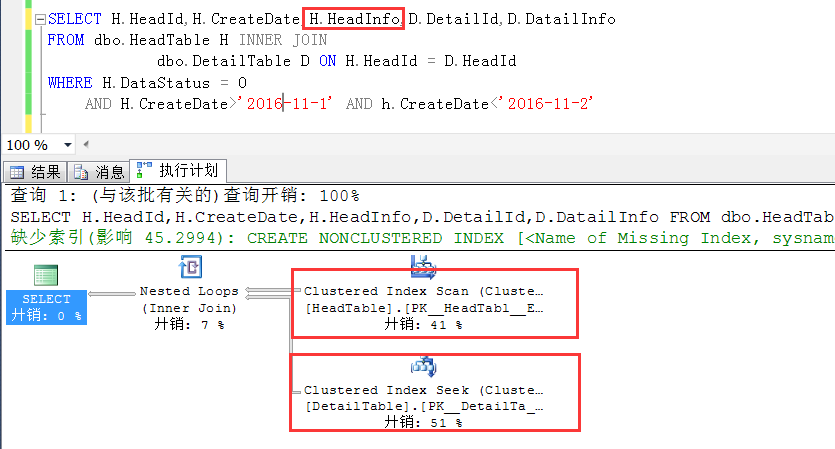
如果,查询语句这么写,如下,在查询条件中增加了一个索引视图中没有的列,此时查询就不会被重写,直接走的是基于原始表的查询,跟普通查询并无二致。
其实原理不难理解,因为视图中并不包含HeadInfo这个列,如果在查询列上加上这个字段,视图中是没有这个字段的,那只能基于原始表做查询了。
为什么查询会被重写
上面我们看到了,对于合适的查询,查询是会被重写的,也就是查询直接基于索引视图来实现,那么为什么会直接基于视图来实现呢?
还是处于性能上的考虑,因为索引视图在创建唯一的聚集索引之后,视图就“固化了”原始表的结果集,
此时的视图与普通视图最大的区别就是,视图中直接存储了数据本身,而非一个查询,
此时的视图中的数据集,相当于基于原表的一个“子集”,因为是子集,这个结果集必然小于原始表,
那么同样的查询字段和查询条件,不但可以减少表与表之间的链接操作,且结果集更小,从这个视图上查询,
同等条件下可以更快地返回结果,所以查询重写也就不难理解了。
此时只要查询字段和查询条件一样,基于原始表的查询和直接查询索引视图是一样的,如下截图
索引视图什么时候更新
上面说了查询重写,如果条件允许,基于原始表的查询会直接从索引视图上来实现。
可能有人会不放心,毕竟数据都是基于物理表做增删改的,而索引视图中的数据又是物理存在的,那就就会有一个担心,基于视图的查询会不会不准确?
毕竟是我好好的一个查询,你默认给我定位到索引视图上,查询结果会跟原始表查询一致吗?
那么就要求证一下,索引视图中的数据是如何更新的。
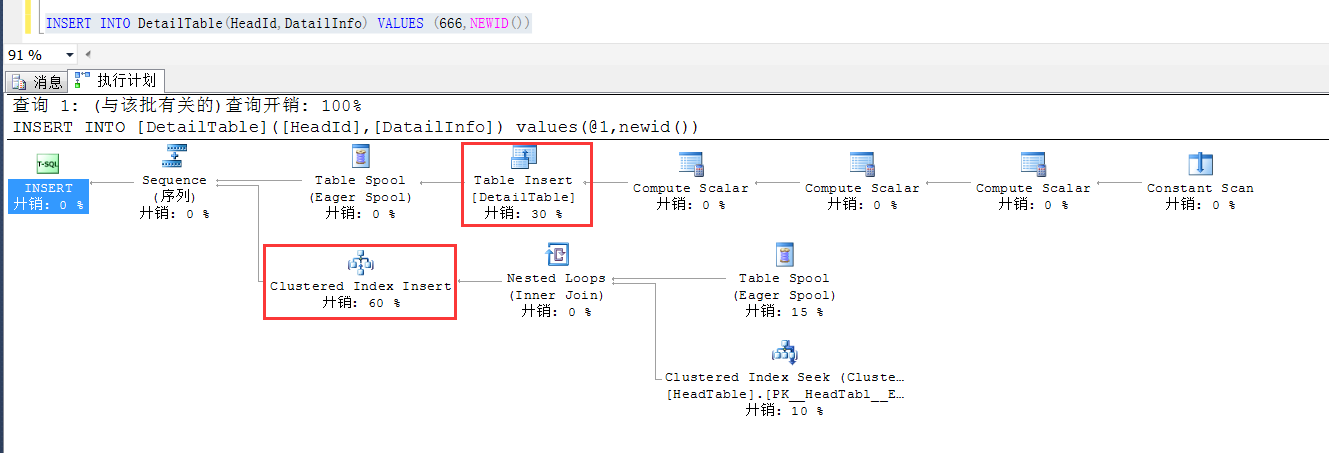
我们做这么一个测试,在基表,也就是DetailTable中查询一条数据,看看到底在执行计划中发生了什么
可以明显地看到,不仅仅是王DetailTable中写入了一条数据,同时,基于索引视图的查询也往索引视图中写入了一条数据,
因此可以放心地使用索引视图而不必担心索引视图中的数据和基表的数据不一致的问题。
但是要注意的就是,此时的写,是写入基表的同事,也写入了索引视图,对写入的影响是肯定有一些的,如果对写入效率要求非常高,就要谨慎一点了。
其实索引视图也是一种冗余写来实现查询效率的提高的。
改变基于视图的查询
上面说了,某些基于视图的查询,是直接定位到视图,从视图中查询结果返回的,如下图
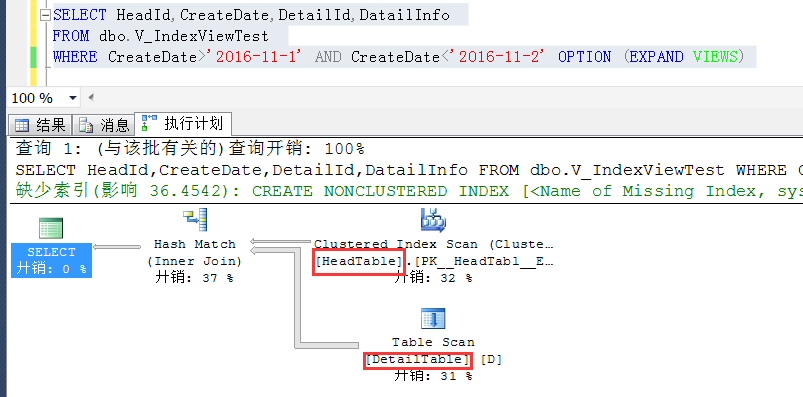
但是如果真的不想从视图中查询,我就是想对比一下原始表和基于视图查询的(效率上的)区别,该怎么办?
这个也好办,可以通过查询提示,将查询来基于原始表实现,也就是展开这个索引视图了
OPTION (EXPAND VIEWS)这个查询提示就是将视图展开,从原始表进行查询,默认情况下是不展开的
如截图,可以强制展开索引视图,从原始表查询
那么效率对比呢?如下截图,粗看起来,这个效率差别还是挺大的,可见,SQL Server默认选择下,载效率上还是有一定的考虑的
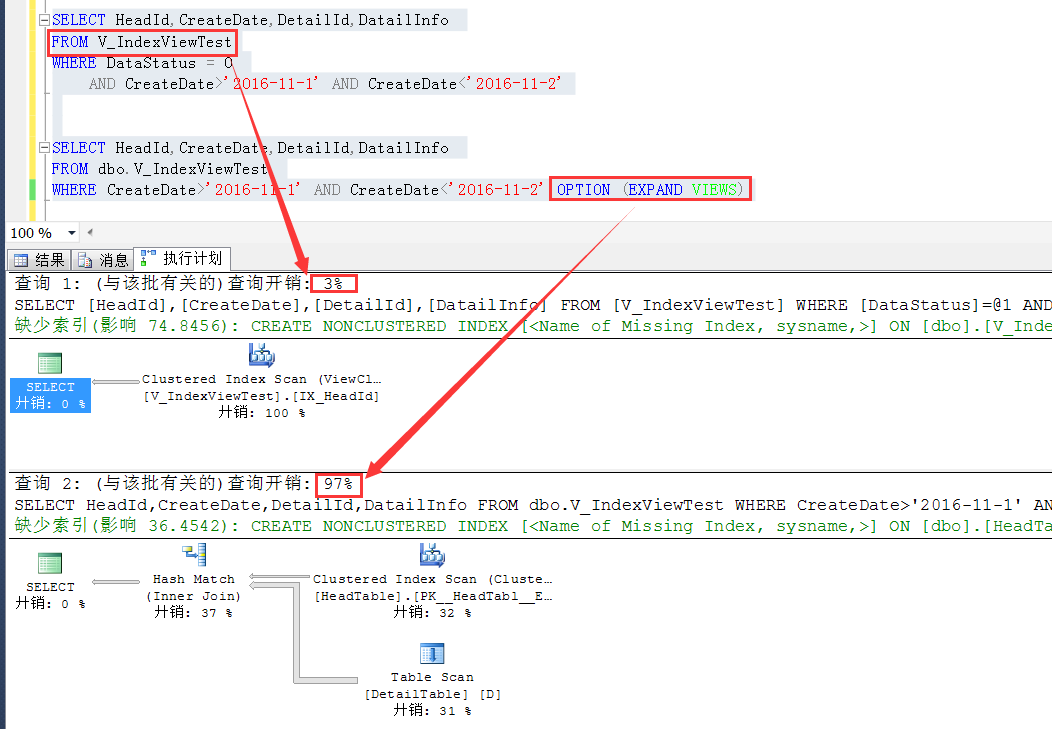
这里从索引视图查询,一是减少了表之间的join,而是索引视图的结果集更小,从中筛选符合条件的数据效率就会更好一些。
所以,默认情况下是会从视图查询来对SQL进行查询重写的。
索引视图的查询提示:with(noexpand) 强制不展开,OPTION (EXPAND VIEWS)强制展开
总结:
本文粗浅地分析了SQL Server 中的索引视图以及索引视图带来的查询重写功能,通过索引视图固化基表的结果集,
可以在一定程度上提高查询效率,尤其是在超级大的多表join的时候,直接将原始结果存为一个索引视图,
通过对索引视图查询来减少表之间的join和IO来提高效率,不失为一种优化选择。
需要注意的是,SQL Server的索引视图限制非常多,具体可以参考链接丛书或者MSND,并不是所有的情况都可以使用索引视图来实现。
本人技术水平还很菜,说的不对还请支出,谢谢。
SQL Server索引视图以(物化视图)及索引视图与查询重写的更多相关文章
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- (转)Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
索引和锁,这两个主题对我们开发工程师来说,非常的重要...只有理解了这两个主题,我们才能写出高质量的sql语句,在之前的博客中,我所说的 索引都是单列索引...当然数据库不可能只认单列索引,还有我这篇 ...
- SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行)
前言 前面几篇我们分析了关于SQL Server关于性能调优的一系列内容,我把它分为两个模块. 第一个模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础运算算法,详细分析了如何查看执行计划. ...
- SQL Server导入导出不丢主键和视图的方法
SQL Server导入导出 SQL Server 导入导出 工具/原料 使用Microsoft SQL Server Management Studio 导入导出数据. 直接使用Microsoft ...
- SQL Server 2005/2008/2012中应用分布式分区视图
自2000版本起,SQL Server企业版中引入分布式分区视图,允许你为分布在不同的SQL 实例的两个或多个水平分区表创建视图. 简要步骤如下:根据Check约束中定义的一组值把大表分割成更小的一些 ...
- SQL Server调优系列进阶篇 - 如何索引调优
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL SERVER 自动生成 MySQL 表结构及索引 的建表SQL
SQL SERVER的表结构及索引转换为MySQL的表结构及索引,其实在很多第三方工具中有提供,比如navicat.sqlyog等,但是,在处理某些数据类型.默认值及索引转换的时候,总有些 ...
- SQL Server性能优化(9)聚集索引的存储结构
一.索引的概念和分类 索引的概念大家都知道,日常开发中我们也会使用常见的聚集索引.非聚集索引.但是除了这两者以外,sqlserver中还提供其他的索引,如: a. 唯一索引:不包含重复键的索引,聚集索 ...
- SQL Server 调优系列进阶篇 - 如何索引调优
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
随机推荐
- 深入浅出Redis-redis底层数据结构(上)
1.概述 相信使用过Redis 的各位同学都很清楚,Redis 是一个基于键值对(key-value)的分布式存储系统,与Memcached类似,却优于Memcached的一个高性能的key-valu ...
- 如何一步一步用DDD设计一个电商网站(二)—— 项目架构
阅读目录 前言 六边形架构 终于开始建项目了 DDD中的3个臭皮匠 CQRS(Command Query Responsibility Segregation) 结语 一.前言 上一篇我们讲了DDD的 ...
- Centos——安装JDK
写在前面: Just mark! 创建linux虚拟机的时候经常要安装JDK,配置环境变量,却又经常忘记,这里记录一下. 环境:Centos-6.8-x86_64-minimal JDK :jdk-7 ...
- LeetCode: 3Sum
Given an array S of n integers, are there elements a, b, c in S such that a + b + c = 0? Find all un ...
- 千呼万唤始出来,微软Power BI简体中文版官网终于上线了,中文文档也全了。。
前几个月时间,研究微软Power BI技术,由于没有任何文档和资料,只能在英文官网瞎折腾,同时也发布了英文文档的相关文章:系列文章,刚好上周把文章发布完,结果简体中文版上线了.哈哈,心里有苦啊,早知道 ...
- 分布式系列文章——从ACID到CAP/BASE
事务 事务的定义: 事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元(Unit),狭义上的事务特指数据库事务. 事务的作用: 当多个应用程序并发访问 ...
- Lambda
Lambda Lambda 表达式是一种可用于创建委托或表达式目录树类型的匿名函数. 通过使用 lambda 表达式,可作为参数传递或作为函数调用值返回的本地函数. Lambda 表达式对于编写 LI ...
- css3圆形百分比进度条的实现原理
原文地址:css3圆形百分比进度条的实现原理 今天早上起来在查看jquery插件机制的时候,一不小心点进了css3圆形百分比进度条的相关文章,于是一发不可收拾,开始折腾了... 关于圆形圈的实现,想必 ...
- Div Vertical Menu ver5
这个小功能,如果是算此次,已经是第5次修改了.可以从这里看到前4次:V1, http://www.cnblogs.com/insus/archive/2011/10/17/2215637.html V ...
- 移动应用App测试与质量管理一
测试工程师 基于Html的WebApp测试, 现在一些移动App混Html5 HTML5性能测试 兼容性 整理后的脑图 测试招聘 弱化大量技术考察 看重看问题的高度 看重潜力 测试经验 质量管理 专项 ...