hanlp中文自然语言处理的几种分词方法
自然语言处理在大数据以及近年来大火的人工智能方面都有着非同寻常的意义。那么,什么是自然语言处理呢?在没有接触到大数据这方面的时候,也只是以前在学习计算机方面知识时听说过自然语言处理。书本上对于自然语言处理的定义或者是描述太多专业化。换一个通俗的说法,自然语言处理就是把我们人类的语言通过一些方式或者技术翻译成机器可以读懂的语言。
人类的语言太多,计算机技术起源于外国,所以一直以来自然语言处理基本都是围绕英语的。中文自然语言处理当然就是将我们的中文翻译成机器可以识别读懂的指令。中文的博大精深相信每一个人都是非常清楚,也正是这种博大精深的特性,在将中文翻译成机器指令时难度还是相当大的!至少在很长一段时间里中文自然语言的处理都面临这样的问题。
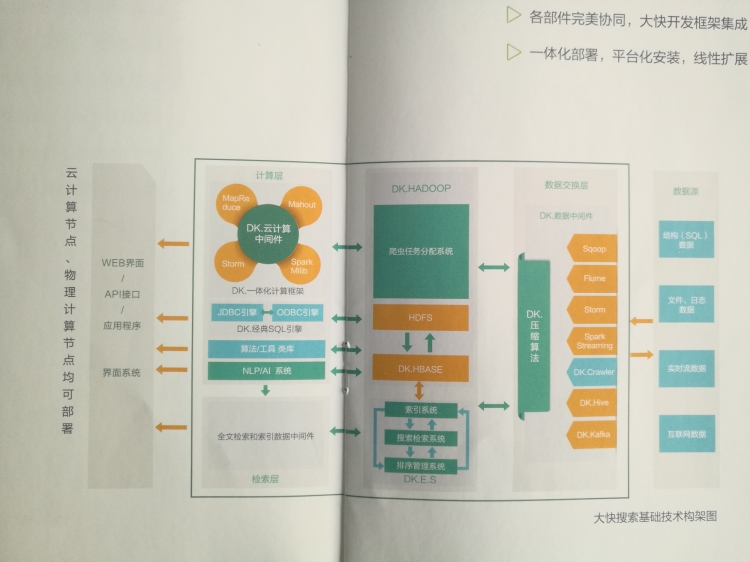
Hanlp中文自然语言处理相信很多从事程序开发的朋友都应该知道或者是比较熟悉的。Hanlp中文自然语言处理是大快搜索在主持开发的,是大快DKhadoop大数据一体化开发框架中的重要组成部分。下面就hanlp中文自然语言处理分词方法做简单介绍。
Hanlp中文自然语言处理中的分词方法有标准分词、NLP分词、索引分词、N-最短路径分词、CRF分词以及极速词典分词等。下面就这几种分词方法进行说明。
标准分词:

Hanlp中有一系列“开箱即用”的静态分词器,以Tokenizer结尾。HanLP.segment其实是对StandardTokenizer.segment的包装
NLP分词:
- List<Term> termList = NLPTokenizer.segment("中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程");
- System.out.println(termList);
NLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
索引分词:

索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
N-最短路劲分词
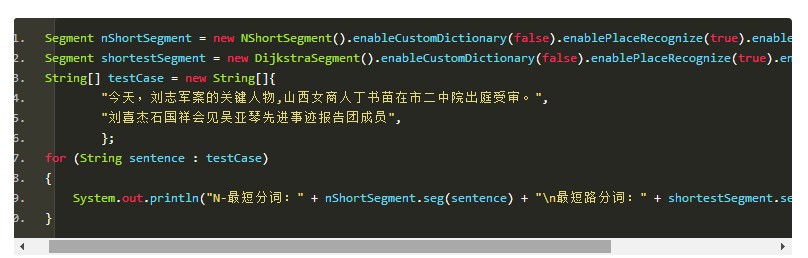
N最短路分词器NShortSegment比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强。
一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。
CRF分词:

CRF对新词有很好的识别能力,但是无法利用自定义词典。
极速词典分词:
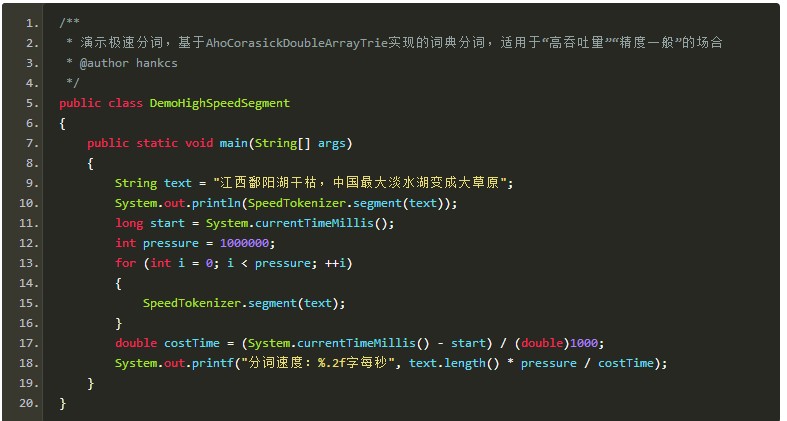
极速分词是词典最长分词,速度极其快,精度一般。
在i7上跑出了2000万字每秒的速度。
上述信息整编的并不是很全面,以后在做补充!
hanlp中文自然语言处理的几种分词方法的更多相关文章
- 【HanLP】HanLP中文自然语言处理工具实例演练
HanLP中文自然语言处理工具实例演练 作者:白宁超 2016年11月25日13:45:13 摘要:HanLP是hankcs个人完成一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环 ...
- Hanlp中文自然语言处理入门介绍
自然语言处理定义: 自然语言处理是一门计算机科学.人工智能以及语言学的交叉学科.虽然语言只是人工智能的一部分(人工智能还包括计算机视觉等),但它是非常独特的一部分.这个星球上有许多生物拥有超过人类的视 ...
- Python BeautifulSoup中文乱码问题的2种解决方法
解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输出的总是乱码,找了好久找到解决办法,下面分享给大家首先是代码 from bs4 import Beautif ...
- HanLP《自然语言处理入门》笔记--3.二元语法与中文分词
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 3. 二元语法与中文分词 上一章中我们实现了块儿不准的词典分词,词典分词无法消歧. ...
- HanLP《自然语言处理入门》笔记--2.词典分词
2. 词典分词 中文分词:指的是将一段文本拆分为一系列单词的过程,这些单词顺序拼接后等于原文本. 中文分词算法大致分为基于词典规则与基于机器学习这两大派. 2.1 什么是词 在基于词典的中文分词中,词 ...
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 中文自然语言处理工具HanLP源码包的下载使用记录
中文自然语言处理工具HanLP源码包的下载使用记录 这篇文章主要分享的是hanlp自然语言处理源码的下载,数据集的下载,以及将让源代码中的demo能够跑通.Hanlp安装包的下载以及安装其实之前就已经 ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
随机推荐
- 使用路径arc
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> < ...
- POJ 1847 Floyd_wshall算法
前面用dijstra写过了.但是捏.数据很小.也可以用Floyd来写. 注意题目里给出的是有向的权值. 附代码:#include<stdio.h>#include<string.h& ...
- css 页面定位position
position的四个属性值 relative absolute fixed static 参看实例 <div id="parent"> <div id='su ...
- js弹窗那些事
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- Taffy自动化测试框架Web开发,Python Flask实践详解
1. 前言 最近为Taffy自动化测试框架写了个页面,主要实现了用例管理.执行,测试报告查看管理.发送邮件及配置等功能. 本页面适用所有基于taffy/nose框架编写的自动化测试脚本,或基于un ...
- POJ 3579 median 二分搜索,中位数 难度:3
Median Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 3866 Accepted: 1130 Descriptio ...
- ADO SQL delete 日期条件参数
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- 关于Predynastic Egypt
游戏界面(资源增加工人,工人产生资源) 解锁建筑(花费资源增加某一地区产出) 神灵祭祀(献祭资源获得临时buff,如减少建筑时间,一定回合内减少入侵几率,增加粮食产出,减少消耗资源等) 解锁科技(增加 ...
- websevice之三要素
SOAP(Simple Object Access Protocol).WSDL(WebServicesDescriptionLanguage).UDDI(UniversalDescriptionDi ...
- springboot跨域请求
首页 所有文章 资讯 Web 架构 基础技术 书籍 教程 Java小组 工具资源 SpringBoot | 番外:使用小技巧合集 2018/09/17 | 分类: 基础技术 | 0 条评论 | 标 ...