hanlp中文自然语言处理的几种分词方法
自然语言处理在大数据以及近年来大火的人工智能方面都有着非同寻常的意义。那么,什么是自然语言处理呢?在没有接触到大数据这方面的时候,也只是以前在学习计算机方面知识时听说过自然语言处理。书本上对于自然语言处理的定义或者是描述太多专业化。换一个通俗的说法,自然语言处理就是把我们人类的语言通过一些方式或者技术翻译成机器可以读懂的语言。
人类的语言太多,计算机技术起源于外国,所以一直以来自然语言处理基本都是围绕英语的。中文自然语言处理当然就是将我们的中文翻译成机器可以识别读懂的指令。中文的博大精深相信每一个人都是非常清楚,也正是这种博大精深的特性,在将中文翻译成机器指令时难度还是相当大的!至少在很长一段时间里中文自然语言的处理都面临这样的问题。
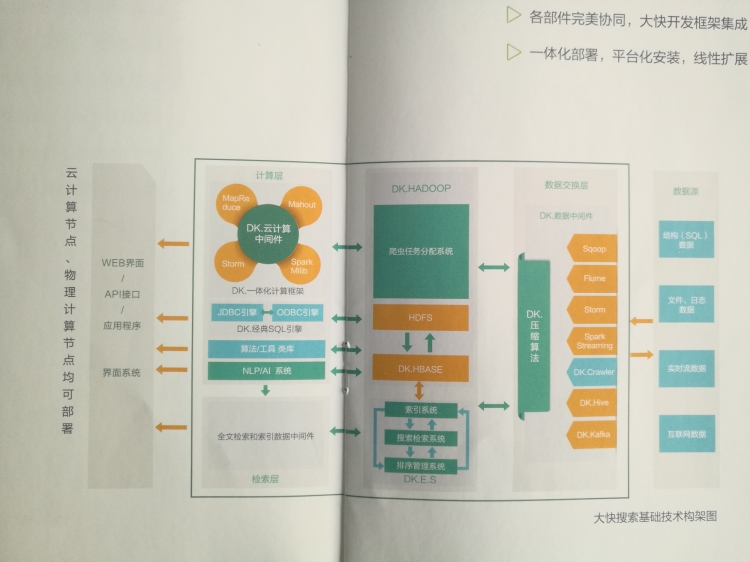
Hanlp中文自然语言处理相信很多从事程序开发的朋友都应该知道或者是比较熟悉的。Hanlp中文自然语言处理是大快搜索在主持开发的,是大快DKhadoop大数据一体化开发框架中的重要组成部分。下面就hanlp中文自然语言处理分词方法做简单介绍。
Hanlp中文自然语言处理中的分词方法有标准分词、NLP分词、索引分词、N-最短路径分词、CRF分词以及极速词典分词等。下面就这几种分词方法进行说明。
标准分词:

Hanlp中有一系列“开箱即用”的静态分词器,以Tokenizer结尾。HanLP.segment其实是对StandardTokenizer.segment的包装
NLP分词:
- List<Term> termList = NLPTokenizer.segment("中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程");
- System.out.println(termList);
NLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
索引分词:

索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
N-最短路劲分词
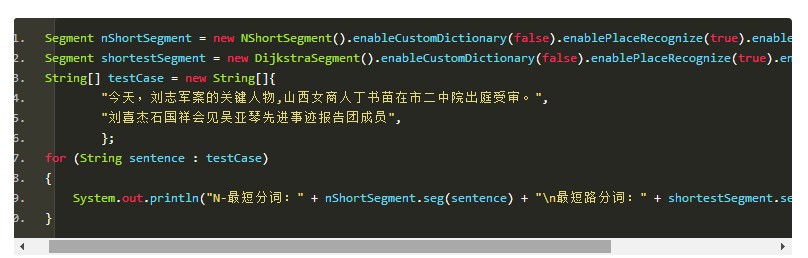
N最短路分词器NShortSegment比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强。
一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。
CRF分词:

CRF对新词有很好的识别能力,但是无法利用自定义词典。
极速词典分词:
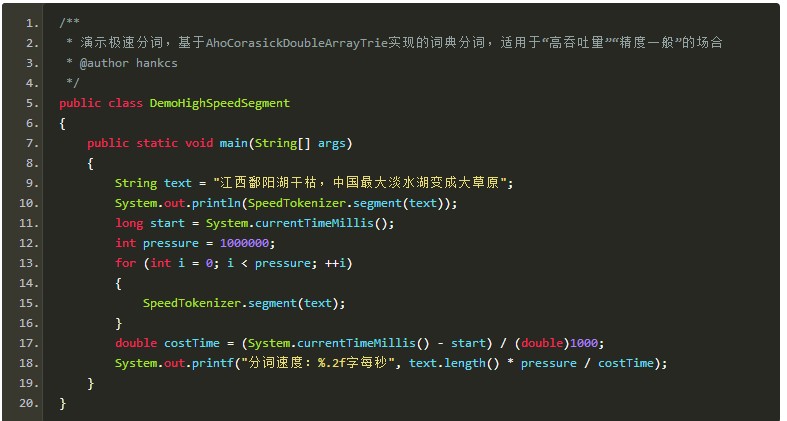
极速分词是词典最长分词,速度极其快,精度一般。
在i7上跑出了2000万字每秒的速度。
上述信息整编的并不是很全面,以后在做补充!
hanlp中文自然语言处理的几种分词方法的更多相关文章
- 【HanLP】HanLP中文自然语言处理工具实例演练
HanLP中文自然语言处理工具实例演练 作者:白宁超 2016年11月25日13:45:13 摘要:HanLP是hankcs个人完成一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环 ...
- Hanlp中文自然语言处理入门介绍
自然语言处理定义: 自然语言处理是一门计算机科学.人工智能以及语言学的交叉学科.虽然语言只是人工智能的一部分(人工智能还包括计算机视觉等),但它是非常独特的一部分.这个星球上有许多生物拥有超过人类的视 ...
- Python BeautifulSoup中文乱码问题的2种解决方法
解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输出的总是乱码,找了好久找到解决办法,下面分享给大家首先是代码 from bs4 import Beautif ...
- HanLP《自然语言处理入门》笔记--3.二元语法与中文分词
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 3. 二元语法与中文分词 上一章中我们实现了块儿不准的词典分词,词典分词无法消歧. ...
- HanLP《自然语言处理入门》笔记--2.词典分词
2. 词典分词 中文分词:指的是将一段文本拆分为一系列单词的过程,这些单词顺序拼接后等于原文本. 中文分词算法大致分为基于词典规则与基于机器学习这两大派. 2.1 什么是词 在基于词典的中文分词中,词 ...
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 中文自然语言处理工具HanLP源码包的下载使用记录
中文自然语言处理工具HanLP源码包的下载使用记录 这篇文章主要分享的是hanlp自然语言处理源码的下载,数据集的下载,以及将让源代码中的demo能够跑通.Hanlp安装包的下载以及安装其实之前就已经 ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
随机推荐
- iOS UI-三种简单的动画设置
一.首尾式动画 代码示例: // beginAnimations表示此后的代码要“参与到”动画中 [UIView beginAnimations:nil context:nil]; //设置动画时长 ...
- postgresql相关开源软件及架构简介
1.PgBouncerPG数据库的一个轻量级连接池工具,功能及特点如下:1)缓存后端PG数据库的连接,当前端应用请求时,分配连接池中的连接给应用,从而充分利用了系统资源.2)允许应用创建比连接池更多的 ...
- != 比 & 的优先级高
#define ACQU_OPTION_WEIXIN 8 int options = 7; int a = options & ACQU_OPTION_WEIXIN ; 则a 的结果应该是 ...
- mysql主从搭建之诡异事件
今天在搭建主从后出现了主库system账号丢失INSERT权限的情况,记录如下 主库: system账号权限同root权限,并且mysql库已经删除 从库: mysql库存在,无system账号 主从 ...
- 递归算法,如何把list中父子类对象递归成树
以前写代码for循环写的多,递归除了在大学学习以外,真没怎么用过! 最近项目中使用到了关于族谱排列的问题,就是怎么把数据库里的多个子父类people对象,在界面中用树的结构展示出来 假设数据库中peo ...
- spring核心容器
容器:用来包装或装载物品的储存器 web服务器与jsp.servlet的关系: 从程序文件存放的位置 程序文件要放到web服务器上 从程序执行的方式 程序的从初始化到消亡都是web服务器管理的 从以 ...
- Crystal Report Error: Either the Crystal Reports registy key permission are insufficient or the Crystal Reports runtime is not installed correctly
在64位 Windows 7中水晶报表的错误: Crystal Report Error: Either the Crystal Reports registy key permission are ...
- DevExpress ASPxComboBox lost selected item after postback
<dx:ASPxComboBox ID="cbxSname" ClientInstanceName="cbxSname" Font-Names=" ...
- Eclipse中复制项目重命名后重新发布,项目名在地址栏仍然是原来的项目名”的问题
转载自: http://www.cnblogs.com/chenxueling/p/5474717.html 将20170331-JavaEE-SSH项目复制一份,重命名为20170407-JavaE ...
- CMS垃圾回收
最近在学习JVM和GC调优,今天总结下CMS的一些特点和要点,让我们先简单的看下整个堆年轻代和年老代的垃圾收集器组合(以下配合java8完美支持,其他版本可能稍有不同),其中标红线的则是我们今天要着重 ...