Shuffle机制

一个map task处理一个切片Split,切片是一个范围的数据,和blocksize大小没有必然关系。
1.每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2.写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
3.等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
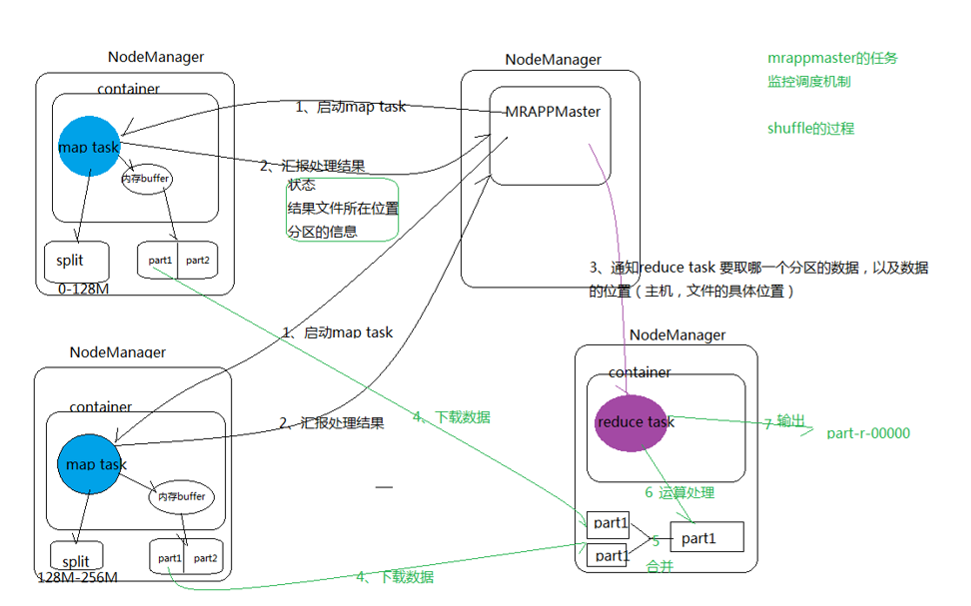
1.Reducer通过Http方式得到输出文件的分区。
2.YarnChild为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
3.排序阶段合并map输出。然后走Reduce阶段。


MapReduce的详细过程如图:

MRAppMaster的任务监控调度机制以及Shuffle的过程如图:
最后,将MapReduce的整个处理流程进行一下总结:
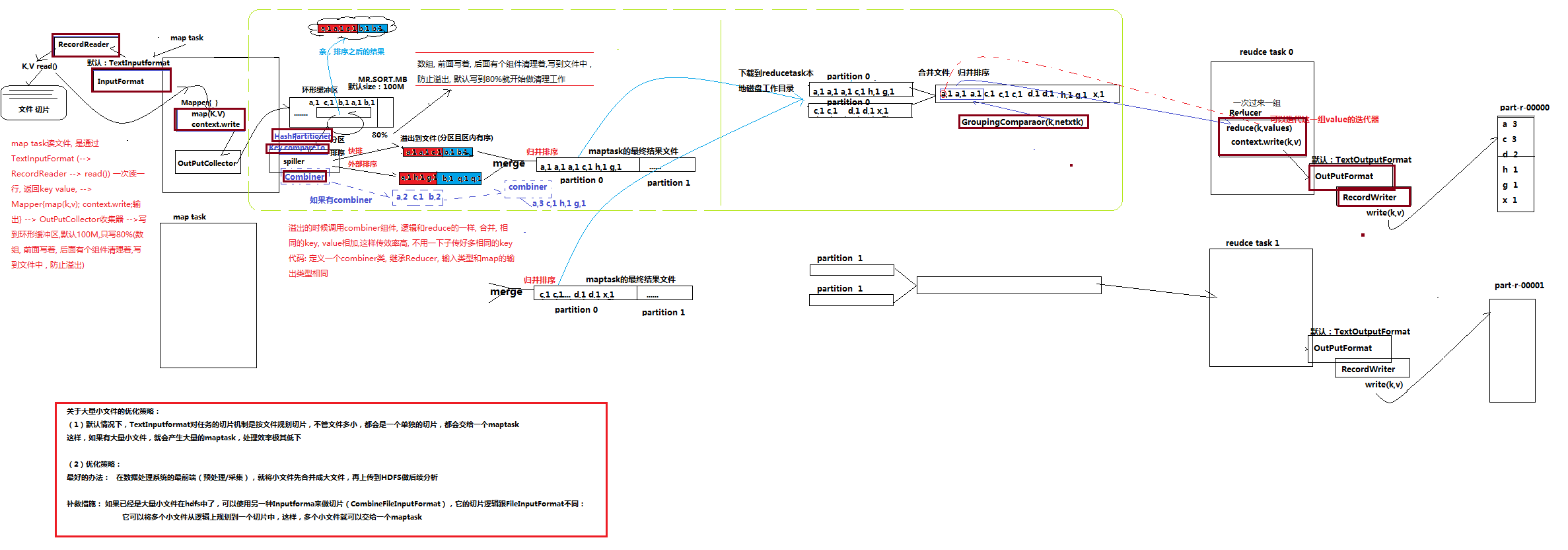
1、 maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
2、 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3、 多个溢出文件会被合并成大的溢出文件
4、 在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、 reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、 reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7、 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M。
对应的部分代码的写法:
// 设置Combiner,Combiner的写法和Reducer完全一样,所以可以直接调用Reducer的类(最好别写)
job.setCombiner(FlowSumAreaReducer.class); //如果不设置InputFormat,它默认使用的是TextInputFormat
//如果有大量小文件,不管文件多小都会形成一个文件切片,由于一个切片对应一个MapTask,因此会造成好多MapTask
//CombineTextInputFormat可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个MapTask
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
Shuffle机制的更多相关文章
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Shuffle 机制
1. 概述 Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle. 2. Partition 分区 需求:要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按照手 ...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- 3 weekend110的shuffle机制 + mr程序的组件全貌
前面,讲到了hadoop的序列化机制,mr程序开发,自定义排序,自定义分组. 有多少个reduce的并发任务数可以控制,但有多少个map的并发任务数还没 缓存,分组,排序,转发,这些都是mr的shuf ...
随机推荐
- Web用户控件开发--星型评分控件
本文中分享一个实现简单,使用方便的星型评分控件. 一:贴几张测试图片先: 二.星型评分控件的实现: RatingBar.ascx: <%@ Control Language="C#&q ...
- [转]使用Runtime.getRuntime().exec()方法的几个陷阱
Process 子类的一个实例,该实例可用来控制进程并获得相关信息.Process 类提供了执行从进程输入.执行输出到进程.等待进程完成.检查进程的退出状态以及销毁(杀掉)进程的方法. 创建进程的方法 ...
- 要想有什么样的成就就要有什么样的眼光-SNF快速开发平台
1.普通人的圈子,谈论的是闲事,赚的是 工资,想的是明天. 2.生意人的圈子,谈论的是项目,赚的是 利润,想的是下一年. 3.事业人的圈子,谈论的是机会,赚的是 财富,想到的是未来和保障. 4.智慧人 ...
- Node.js使用rabbitMQ(一)
目前使用的开发环境主要还是win,所以也只是介绍在win下的rabbitMQ的使用. 一.安装rabbitMQ(Installing on Windows) 关于安装地址,参见:Installing ...
- opencv之haar特征+AdaBoos分类器算法流程(三)
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/ ...
- ASP.NET MVC做的微信WEBAPP中调用微信JSSDK扫一扫
今天做一个项目,是在微信上用的,微信WEB APP,里面用到了调用手机摄像头扫一扫二维码的功能,记得以前某个项目里写有的,但是找不到之前那个项目源码了,想复制粘贴也复制不了了,只好对着微信的那个开发文 ...
- .net4.5使用async和await异步编程实例
关于异步编程的简单理解: 在.NET4.5中新增了异步编程的新特性async和await,使得异步编程更为简单.通过特性可以将这项复杂的工作交给编译器来完成了.之前传统的方式来实现异步编程较为复杂,这 ...
- C#整数三种强制类型转换int、Convert.ToInt32()、int.Parse()、string到object 的区别
1.int适合简单数据类型之间的转换,C#的默认整型是int32(不支持bool型); 2.int.Parse(string sParameter)是个构造函数,参数类型只支持string类型; 3. ...
- DIOCP3-DIOCP1升级到DIOCP3
DIOCP3兼容DIOCP1的,有些属性做了修改 DIOCP3, uIOCPConsole没有了, uMemPool没有了 1.DIOCP1,代码: DIOCP3中去掉TIOCPContextFa ...
- audio音乐播放
1.audio标签 <audio @play="ready" @error="error" ref="audio" :src=&quo ...