scrapy 原理,结构,基本命令,item,spider,selector简述
原理,结构,基本命令,item,spider,selector简述
原理
(1)结构
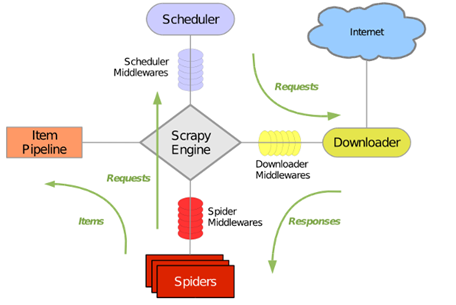

(2)运行流程

实操
(1) scrapy命令:
注意先把python安装目录的scripts文件夹添加到环境变量
查看帮助
scrapy
scrapy <command> -h
创建项目
scrapy startproject 项目名
创建爬虫
scrapy genspider [-t template] <name> <domain>
运行爬虫
运行一个爬虫的基本命令:
scrapy crawl 爬虫名
-a 给spider的构造器传参数
-o表示写入文件,-t 表示以json格式输出
scrapy crawl test -o test.json -t json
查看可用爬虫
scrapy list
快捷爬取(不需要创建爬虫项目,爬取结果直接回送到命令行)
scrapy fetch <url>

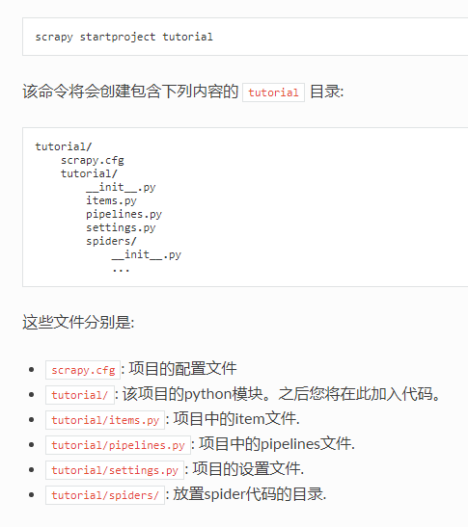
(2)项目结构功能
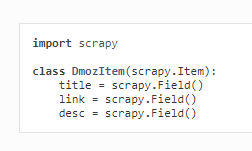
(3)item.py定义数据model
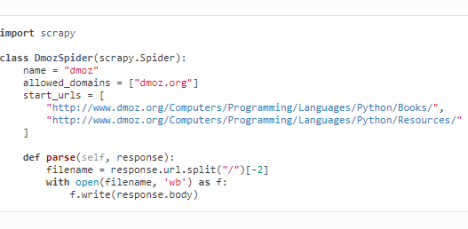
(4)spiders文件夹中的爬虫文件
name爬虫名,唯一
allowed_domains域名
start_urls起始url
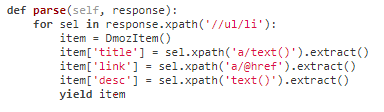
parse函数——处理爬取到的response的函数
基本格式:
parse函数使用selector的格式:
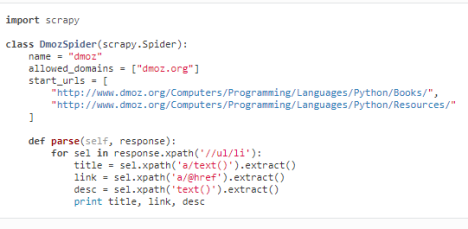
parse函数使用selector并通过生成器返回多个结果:
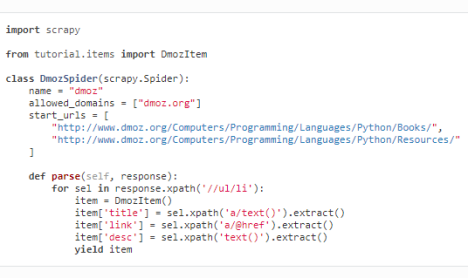
(5)selector
四种格式(即spider文件parse函数中response对象的四个可用方法)

response.xpath()
response.css()
response.extract()
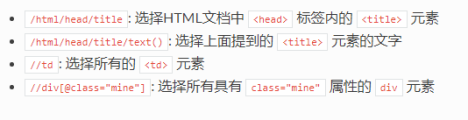
举例:response.xpath()使用
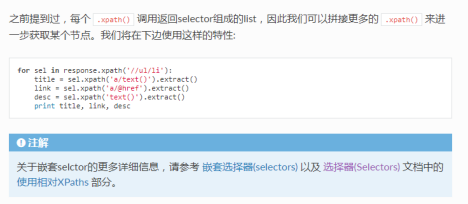
selector的嵌套
(6)保存爬取结果的方式之一:Feed Exports
scrapy 原理,结构,基本命令,item,spider,selector简述的更多相关文章
- 第五篇 scrapy安装及目录结构,启动spider项目
实际上安装scrapy框架时,需要安装很多依赖包,因此建议用pip安装,这里我就直接使用pycharm的安装功能直接搜索scrapy安装好了. 然后进入虚拟环境创建一个scrapy工程: (third ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Scrapy 原理
Scrapy 原理 一.原理 scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列程序中. 二.工作流程 Scrapy Engi ...
- Scrapy(六):Spider
总结自:Spiders - Scrapy 2.5.0 documentation Spider 1.综述 ①在回调函数Parse及其他自写的回调函数中,必须返回Item对象.Request对象.或前两 ...
- python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别: 库可以直接拿来就用, 框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令: 创建一个 项目 : cd 到需 ...
- scrapy框架系列 (3) Item Pipline
item pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
- scrapy框架中多个spider,tiems,pipelines的使用及运行方法
用scrapy只创建一个项目,创建多个spider,每个spider指定items,pipelines.启动爬虫时只写一个启动脚本就可以全部同时启动. 本文代码已上传至github,链接在文未. 一, ...
- Scrapy 对不同的Item进行分开存储
在Piperlines里面进行对象的判断, def process_item(self, item, spider): if item.__class__ == BaseItem : #savexxx ...
- scrapy 知乎关键字爬虫spider代码
以下是spider部分的代码.爬知乎是需要登录的,建议使用cookie就可以了,如果需要爬的数量预计不多,请不要使用过大的线程数量,否则会过快的被封杀,需要等十几个小时账号才能重新使用,比起损失的这十 ...
随机推荐
- C语言第十一回合:预处理命令的集中营
C语言第十一回合:预处理命令的集中营 [学习目标] 1. 宏定义 2. 文件包括"处理 3. 条件编译 预处理命令:能够改进程序设计的 ...
- 利用C#的指针编写都一个简单链表
using System; namespace UnsafeTest { unsafe struct link { public int x; public link* next; } class P ...
- ListView嵌套GridView使用详解及注意事项
ListView嵌套GridView即ListView的每个Item中都包含一个GridView:需要注意的是由于ListView和GridView都是可滑动的控件. 所以需要自定义GridView, ...
- mybatis3 sqlsession
1.mybatis3中的通过openSession()方法打开的sqlsession,它的事务默认是关闭的,所以进行数据库完成操作之后,要记得commit(),也可以添加openSession(boo ...
- oracle,mysql分页
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-/ ...
- TCP/IP详解读书笔记:概述
分层 分层是一种很通用的架构模式.通过分层,可以把一个系统分解成多个层,每个层专注于各自的功能,并提供接口给上面的层调用.上面的层不需要了解调用层的详细实现,只依赖于其接口,这就给维护带来了很大的好处 ...
- dirname(__FILE__) 的使用总结 1(转)
dirname(__FILE__) php中定义了一个很有用的常数,即 __file__ 这个内定常数是当前php程序的就是完整路径(路径+文件名). 即使这个文件被其他文件引用(include或re ...
- Scala学习笔记(一)编程基础
强烈推荐参考该课程:http://www.runoob.com/scala/scala-tutorial.html 1. Scala概述 1.1. 什么是Scala Scala是一种多范式的编程 ...
- Create a new Docker Machine with the Hyper-V driver
docker-machine就是docker工具集中提供的用来管理容器化主机的工具,用来管理运行在不同环境的主机,包括:本地虚拟机,远程虚拟机,公有云中的虚拟机都可以通过一个命令统一进行管理. 01. ...
- [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:600)
Could not fetch URL https://pypi.python.org/simple/six/: There was a problem confirming the ssl cert ...