第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图:

item位于原理图的最左边
item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误。
1、创建item
在创建item时需要继承scrapy.Item类,并且定义scrapy.Field字段。由于我们在上一节Scrapy爬虫框架之项目创建spider文件数据爬取当中提取了id、url、title、thumb四个字段。所以我们在item.py文件当中需要创建者四个字段。
# -*- coding: utf-8 -*-
# item.py import scrapy class Bole_mode(scrapy.Item):
id = scrapy.Field() # id
url = scrapy.Field() # 图片链接
title = scrapy.Field() # 标题
thumb = scrapy.Field() # 缩略图
2、spider使用item
之前说过item文件是报存爬取数据的容器,所以我们在上一节当中爬取下来的数据需要使用item进行暂存。
在进行使用之前需要对这个item进行实例化 item = Bole_mode()。
代码如下
# BLZXSPider.py import scrapy
import json
import sys sys.path.append(r'D:\spider\bole\item.py')
from bole.items import Bole_mode class BoleSpider(scrapy.Spider):
name = 'boleSpider' def start_requests(self):
url = "https://image.so.com/zj?ch=photography&sn={}&listtype=new&temp=1"
page = self.settings.get("MAX_PAGE")
for i in range(int(page)+1):
yield scrapy.Request(url=url.format(i*30)) def parse(self,response):
photo_list = json.loads(response.text)
item = Bole_mode()
for image in photo_list.get("list"):
item["id"] = image["id"]
item["url"] = image["qhimg_url"]
item["title"] = image["group_title"]
item["thumb"] = image["qhimg_thumb_url"]
yield item
运行结果如下,可以看到每个url都已经请求成功。
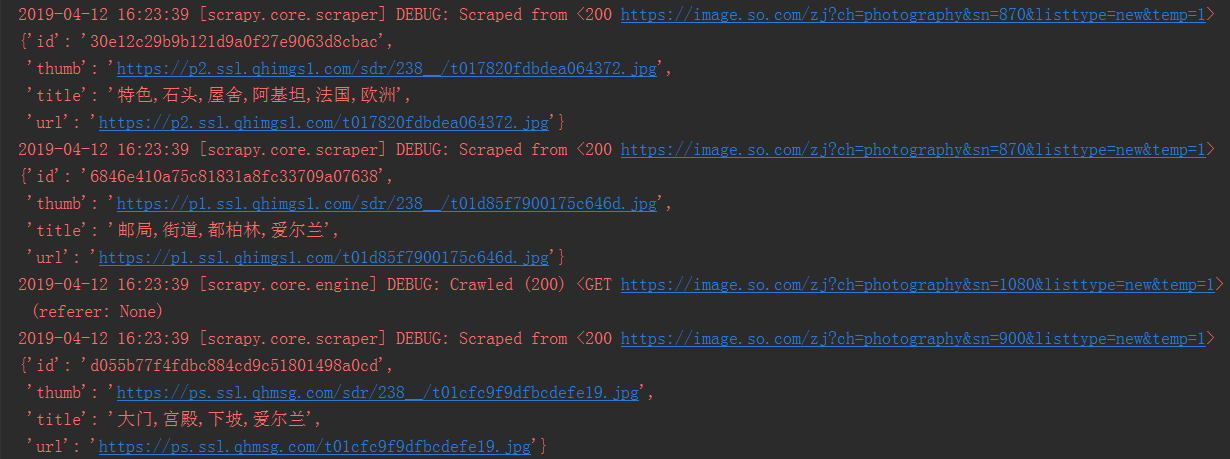
第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item的更多相关文章
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- Scrapy爬虫框架学习
一.Scrapy框架简介 1. 下载页面 2. 解析 3. 并发 4. 深度 二.安装 linux下安装 pip3 install scrapy windows下安装 a.pip3 install w ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
随机推荐
- springboot(四)拦截器和全局异常捕捉
github代码:https://github.com/showkawa/springBoot_2017/tree/master/spb-demo/spb-brian-query-service 全部 ...
- NOI2018D2T1 屠龙勇士
安利一下松松松的OJ: 传送门 Description: 有N条巨龙, 对于每个龙含有\(a_i\)的生命, 你有N + M把砍刀, 其中M把是直接给你的, N把是杀死对应的巨龙才能获得的, 每把 ...
- [COCI2010]HRPA
Description N个石子,A和B轮流取,A先.每个人每次最少取一个,最多不超过上一个人的个数的2倍. 取到最后一个石子的人胜出,如果A要有必胜策略,第一次他至少要取多少个. Input 第一行 ...
- Netflix正式开源其API网关Zuul 2--转
微信公众号:聊聊架构 5 月 21 日,Netflix 在其官方博客上宣布正式开源微服务网关组件 Zuul 2.Netflix 公司是微服务界的楷模,他们有大规模生产级微服务的成功应用案例,也开源了相 ...
- android开发学习——关于activity 和 fragment在toolbar上设置menu菜单
在做一个项目,用的是Android Studio 系统的抽屉源码,但是随着页面的跳转,toolbar的title需要改变,toolbar上的menu菜单也需要改变,在网上找了好久,也尝试了很多,推荐给 ...
- Oracle中的表空间
表空间是什么? Oracle数据库包含逻辑结构和物理结构. 数据库的物理结构是指构成数据库的一组操作系统文件. 数据库的逻辑结构是指描述数据组织方式的一组逻辑概念及它们之间的关系. 表空间是数据库数据 ...
- ASP.NET MVC数据库初始化
public class DBInitializer:DropCreateDatabaseAlways<BookDBContext> { protected override void S ...
- ASP.NET Core MVC使用MessagePack配合前端fetch交换数据
1.安装Nuget包 - WebApiContrib.Core.Formatter.MessagePack https://www.nuget.org/packages/WebApiContrib.C ...
- svn 使用手册
版本控制器:SVN 1 开发中的实际问题 1.1 小明负责的模块就要完成了,就在即将Release之前的一瞬间,电脑突然蓝屏,硬盘光荣牺牲!几个月来的努力付之东流——需求之一:备份! 1.2 这个项目 ...
- VUE 全选
<div id="vue_det"> <p>全选:</p> <input type="checkbox" id=&qu ...