Java内存区域和对象的创建
文章绝大部分内存摘抄自《深入理解Java虚拟机》,结合了小部分个人理解如果有什么错误,还望指出,如果涉及到侵权,联系博主,立马删除,再次感谢《深入理解Java虚拟机》的作者-周志明,博文仅用于本人记录自己阅读该书时的一些要点。
Java内存区域:
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。如下图所示:
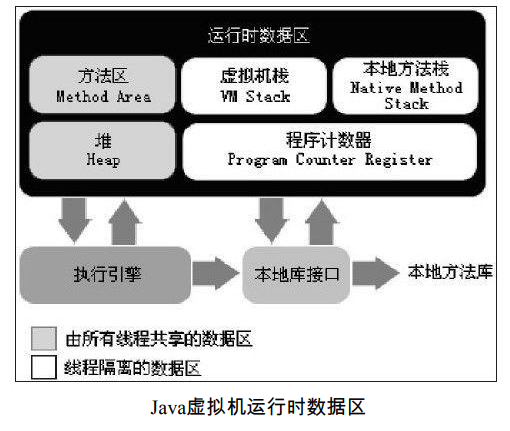
各个区域的作用:
程序计数器(Program Counter Register):是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能 会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需 要依赖这个计数器来完成。 由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的, 在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线 程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
Java虚拟机栈(Java Virtual Machine Stacks):虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口 等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
个局部变量空间(Slot),其余的数据 类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
本地方法栈(Native Method Stack):与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚 拟机使用到的Native方法服务。
Java堆(Java Heap):对于大多数应用来说,Java堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
方法区(Method Area):与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规 范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应 该是与Java堆区分开来。
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版 本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不 要求常量一定只有编译期才能产生,也就是并非预置入Class文件中常量池的内容才能进入方 法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较 多的便是String类的intern()方法。
直接内存:直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规 范中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError 异常出现,所以我们放到这里一起讲解。 在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓 冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储 在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著 提高性能,因为避免了在Java堆和Native堆中来回复制数据。
对象的探究:
对象的创建:
①加载:虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
②验证:验证类数据信息是否符合JVM规范,是否是一个有效的字节码文件,验证内容涵盖了类数据信息的格式验证、语义分析、操作验证等。
③准备:在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把 一块确定大小的内存从Java堆中划分出来。并为其设置一个初始值(由于还没有产生对象,实例变量不在此操作范围内)
④解析:解析是将常量池中的符号引用转化为直接引用的过程。
⑤初始化:初始化算是类加载过程的最后一个阶段,在这个阶段在是真正的开始有java代码主导。将一个类中所有被static关键字标识的代码统一执行一遍,如果执行的是静态变量,那么就会使用用户指定的值覆盖之前在准备阶段设置的初始值;如果执行的是static代码块,那么在初始化阶段,JVM就会执行static代码块中定义的所有操作。
对象的内存布局:
对象在内存中存储的布局可以分为3块区域:对象头(Header)、 实例数据(Instance Data)和对齐填充(Padding)。
对象头:由Mark Word(记录的信息如下图所示)和类型指针(即对象指向它的类元数据的指针,虚拟机通过这个指 针来确定这个对象是哪个类的实例)组成。

实例数据:对象真正存储的有效信息,也是在程序代码中所定义的各种类 型的字段内容。
对齐填充:对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。
对象的访问定位:
使用对象时Java程序需要通过栈上的reference数据来操作堆上的具体对象。
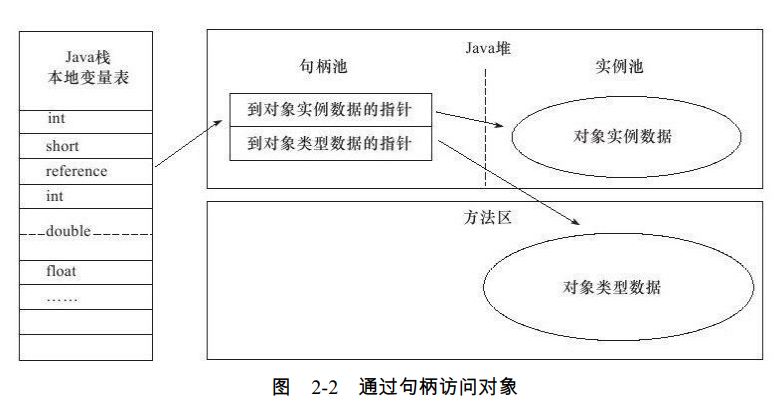
目前主流的访问方式有使用句柄和直接指针两种。
如果使用句柄访问的话,那么Java堆中将会划分出一块内存来作为句柄池,reference中 存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信 息,如图2-2所示。
如果使用直接指针访问,那么Java堆对象的布局中就必须考虑如何放置访问类型数据的 相关信息,而reference中存储的直接就是对象地址,如图2-3所示。 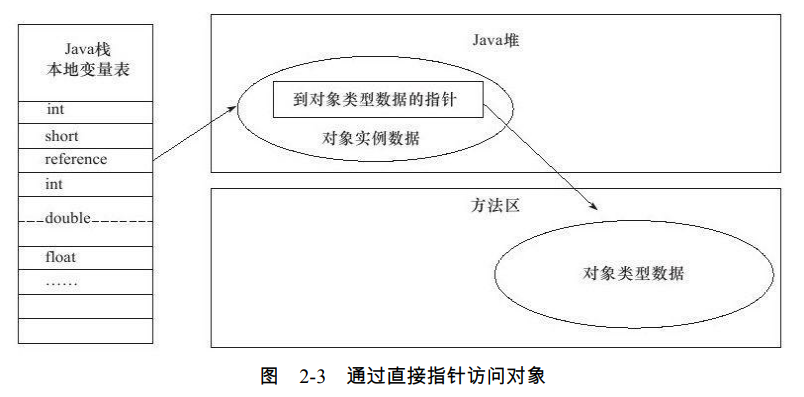
这两种对象访问方式各有优势,使用句柄来访问的最大好处就是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中 的实例数据指针,而reference本身不需要修改。
使用直接指针访问方式的最大好处就是速度更快,它节省了一次指针定位的时间开销, 由于对象的访问在Java中非常频繁,因此这类开销积少成多后也是一项非常可观的执行成 本。就本书讨论的主要虚拟机Sun HotSpot而言,它是使用第二种方式进行对象访问的,但从 整个软件开发的范围来看,各种语言和框架使用句柄来访问的情况也十分常见。
关于类加载器的理解: https://blog.csdn.net/chang_ge/article/details/80262115
个人觉得这个博主写的挺好的,就不重复造轮子了.引用一下他的
Java内存区域和对象的创建的更多相关文章
- Java内存区域与对象创建过程
一.java内存区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有的区域则 ...
- Java虚拟机2:Java内存区域及对象
几个计算机的概念 为以后写文章考虑,也为巩固自己的知识和一些基本概念,这里要理清楚几个计算机中的概念. 1.计算机存储单位 从小到大依次为位Bit.字节Byte.千字节KB.兆M.千兆GB.TB,相邻 ...
- 深入java----java内存区域及对象的创建
看完深入理解jvm之后自己再用图的方式进行一遍梳理,用以加深理解. 第一部分,首先对整体java运行时内存区域有一个整体框架式的了解. 运行时内存区域的划分如上图所示,那么接下里看看一个对象的创建又怎 ...
- Java 5大内存区域和对象的创建过程
1.Java运行时数据区 方法区,堆线程共享.虚拟机栈,本地方法栈和程序计数器线程私有. 2.程序计数器(PC计数器) 占用较小的一块内存空间,当执行Java方法时记录正在执行的虚拟机字节码指令地址, ...
- JVM系列一(Java内存区域和对象创建).
一.JVM 内存区域 堆 - Heap 线程共享,JVM中最大的一块内存,此内存的唯一目的就是存放对象实例,Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称为"GC堆"( ...
- java内存区域和对象的产生
一直被java中内存组成弄的头晕眼花,这里总结下都有哪些,先上图片 程序计数器 小块内存,线程执行字节码的信号指示器,以此获取下一条需要执行的字节码指令,分支,循环,跳转,异常处理,线程恢复都要依赖他 ...
- 【转】Java内存管理:深入Java内存区域
转自:http://www.cnblogs.com/gw811/archive/2012/10/18/2730117.html 本文引用自:深入理解Java虚拟机的第2章内容 Java与C++之间有一 ...
- Java 内存区域和GC机制分析
目录 Java垃圾回收概况 Java内存区域 Java对象的访问方式 Java内存分配机制 Java GC机制 垃圾收集器 Java垃圾回收概况 Java GC(Garbage Collection, ...
- Java 内存区域和GC机制
目录 Java垃圾回收概况 Java内存区域 Java对象的访问方式 Java内存分配机制 Java GC机制 垃圾收集器 Java垃圾回收概况 Java GC(Garbage Collection, ...
随机推荐
- [ActionScript 3.0] 如何控制加载swf动画的播放与暂停
此方法适用于用as 1.0或者as2.0以及as3.0编译的swf,因为as1.0和as2.0编译的swf是AVM1Movie类型,因此需要通过类ForcibleLoader.as将其转换为versi ...
- secureCRT颜色方案设置
按照如下设置后vim编辑会有如下颜色提示
- CentOS6.9 ARM虚拟机扩容系统磁盘
由于扩容磁盘的操作非同小可,一旦哪一步出现问题,就会导致分区损坏,数据丢失等一系列严重的问题,因此建议:在进行虚拟机分区扩容之前,一定要备份重要数据文件,并且先在测试机上验证以下步骤,再应用于您的生产 ...
- Python3之collections模块
简介 collections是Python内建的一个集合模块,提供了许多有用的集合类. namedtuple namedtuple 是一个函数,它用来创建一个自定义的元组对象,并且规定了元组元素的个数 ...
- python 常用模块大全
1.getpass 模块 一般用于获取用户输入的密码 import getpass pwd = getpass.getpass('input your pass') print(pwd) print ...
- [CoffeeScript]使用Yield功能
CoffeeScript 1.9 开始提供了类似ES6的yield关键字. 自己结合co和bluebird做了个试验. co -- http://npmjs.org/package/co -- fo ...
- tomcat增加运行内存
内容为: set JAVA_OPTS=%JAVA_OPTS% -server -Xms2048m -Xmx2048m -XX:PermSize=212M -XX:MaxPermSize=512m 在m ...
- mongoDB使用小记
1.简介: MongoDB是由c++语言编写的,基于分布式文件存储的开源数据库系统.MongoDB将数据存储为一个文档,数据结构有键-值对,类似于JSON对象. MongoDB其中的一些概念如下: M ...
- 再探php
1. 如何打开一个php文件? 启动本地服务器和MySQL, 然后将php文件放在xampp -> htdocs 目录下(可以是子目录.孙子目录 ......),打开浏览器,在浏览器中输入 l ...
- Delphi对话框初始地址InitialDir
我的电脑:SaveDialog1.InitialDir := '::{20D04FE0-3AEA-1069-A2D8-08002B30309D}';// My Computer {20D04FE0-3 ...