seq2seq模型案例分析
1 seq2seq模型简介
seq2seq 模型是一种基于【 Encoder-Decoder】(编码器-解码器)框架的神经网络模型,广泛应用于自然语言翻译、人机对话等领域。目前,【seq2seq+attention】(注意力机制)已被学者拓展到各个领域。seq2seq于2014年被提出,注意力机制于2015年被提出,两者于2017年进入疯狂融合和拓展阶段。
1.1 seq2seq原理
通常,编码器和解码器可以是一层或多层 RNN、LSTM、GRU 等神经网络。为方便讲述原理,本文以 RNN 为例。seq2seq模型的输入和输出长度可以不一样。如图,Encoder 通过编码输入序列获得语义编码 C,Decoder 通过解码 C 获得输出序列。
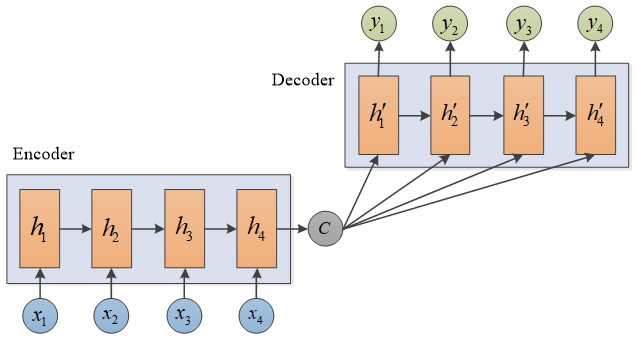 seq2seq网络结构图
seq2seq网络结构图
Encoder
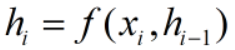
Decoder
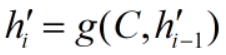
说明:xi、hi、C、h'i 都是列向量
1.2 seq2seq+attention原理
普通的 seq2seq 模型中,Decoder 每步的输入都是相同的语义编码 C,没有针对性的学习,导致解码效果不佳。添加注意力机制后,使得每步输入的语义编码不一样,捕获的信息更有针对性,解码效果更佳。
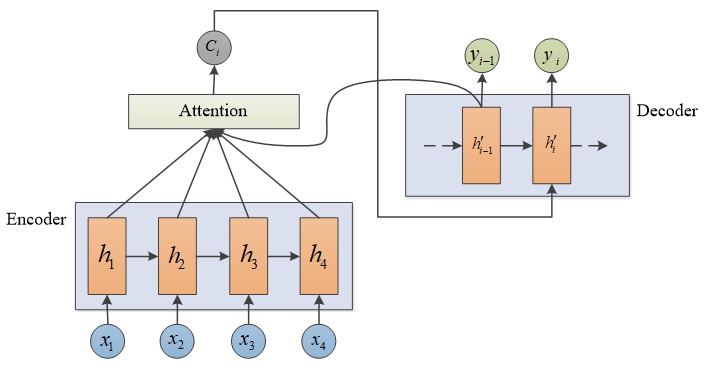 seq2seq+attention网络结构图
seq2seq+attention网络结构图
Encoder
Decoder
(1)标准 attention
其中 ,v、W、U 都是待学习参数,v 为列向量,W、U 为矩阵
(2)attention 扩展
扩展的 attention 机制有3种方法,如下。其中,v、W 都是待学习参数,v 为列向量,W为矩阵。相较于标准的 attention,待学习的参数明显减少了些。
说明:xi、hi、Ci、h'i、wi 、ei 都是列向量,h 是矩阵
2 安装seq2seq
- 下载【GitHub - farizrahman4u/recurrentshop: Framework for building complex recurrent neural networks with Keras】
,解压,通过cmd进入文件,输入 python setup.py install - 下载【GitHub - farizrahman4u/seq2seq: Sequence to Sequence Learning with Keras】
,解压,通过cmd进入文件,输入 python setup.py install 重启编译器
若下载比较慢,可以先通过【**`\**[码云](https://gitee.com/)\**`**】导入,再在码云上下载,如下:
本文以MNIST手写数字分类为例,讲解 seq2seq 模型和 AtttionSeq2seq 模型的实现。关于MNIST数据集的说明,见使用TensorFlow实现MNIST数据集分类。
笔者工作空间如下:

代码资源见-->seq2seq模型和基于注意力机制的seq2seq模型
3 SimpleSeq2Seq
SimpleSeq2Seq(input_length, input_dim, hidden_dim, output_length, output_dim, depth=1)
- input_length:输入序列长度
- input_dim:输入序列维度
- output_length:输出序列长度
- output_dim:输出序列维度
- depth:Encoder 和 Decoder 的深度,取值可以为整数或元组。如 depth=3,表示 Encoder 和 Decoder 都有 3 层;depth=(3, 4) 表示 Encoder 有3层和 Decoder 有4层
SimpleSeq2Seq.py
from tensorflow.examples.tutorials.mnist import input_data
from seq2seq.models import SimpleSeq2Seq
from keras.models import Sequential
from keras.layers import Dense,Flatten
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#SimpleSeq2Seq模型
def seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
seq=SimpleSeq2Seq(input_dim=28,hidden_dim=32,output_length=10,output_dim=10)
model.add(seq)
model.add(Flatten()) #扁平化
model.add(Dense(10,activation='softmax'))
#查看网络结构
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=25,verbose=2,validation_data=(valid_x,valid_y))
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y)
网络各层输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model_14 (Model) (None, 10, 10) 10368
_________________________________________________________________
flatten_1 (Flatten) (None, 100) 0
_________________________________________________________________
dense_23 (Dense) (None, 10) 1010
=================================================================
Total params: 11,378
Trainable params: 11,378
Non-trainable params: 0
网络训练结果:
Epoch 23/25
- 17s - loss: 0.1521 - acc: 0.9563 - val_loss: 0.1400 - val_acc: 0.9598
Epoch 24/25
- 17s - loss: 0.1545 - acc: 0.9553 - val_loss: 0.1541 - val_acc: 0.9536
Epoch 25/25
- 17s - loss: 0.1414 - acc: 0.9594 - val_loss: 0.1357 - val_acc: 0.9624
test_loss: 0.14208583533763885 - test_acc: 0.9567999958992004
4 AttentionSeq2Seq
AttentionSeq2Seq(input_length, input_dim, hidden_dim, output_length, output_dim, depth=1)
- input_length:输入序列长度
- input_dim:输入序列维度
- output_length:输出序列长度
- output_dim:输出序列维度
- depth:Encoder 和 Decoder 的深度,取值可以为整数或元组。如 depth=3,表示 Encoder 和 Decoder 都有 3 层;depth=(3, 4) 表示 Encoder 有3层和 Decoder 有4层
AttentionSeq2Seq.py
from tensorflow.examples.tutorials.mnist import input_data
from seq2seq.models import AttentionSeq2Seq
from keras.models import Sequential
from keras.layers import Dense,Flatten
#载入数据
def read_data(path):
mnist=input_data.read_data_sets(path,one_hot=True)
train_x,train_y=mnist.train.images.reshape(-1,28,28),mnist.train.labels,
valid_x,valid_y=mnist.validation.images.reshape(-1,28,28),mnist.validation.labels,
test_x,test_y=mnist.test.images.reshape(-1,28,28),mnist.test.labels
return train_x,train_y,valid_x,valid_y,test_x,test_y
#AttentionSeq2Seq模型
def seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y):
#创建模型
model=Sequential()
seq=AttentionSeq2Seq(input_length=28,input_dim=28,hidden_dim=32,output_length=10,output_dim=10)
model.add(seq)
model.add(Flatten()) #扁平化
model.add(Dense(10,activation='softmax'))
#查看网络结构
model.summary()
#编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#训练模型
model.fit(train_x,train_y,batch_size=500,nb_epoch=25,verbose=2,validation_data=(valid_x,valid_y))
#评估模型
pre=model.evaluate(test_x,test_y,batch_size=500,verbose=2)
print('test_loss:',pre[0],'- test_acc:',pre[1])
train_x,train_y,valid_x,valid_y,test_x,test_y=read_data('MNIST_data')
seq2Seq(train_x,train_y,valid_x,valid_y,test_x,test_y)
网络各层输出尺寸:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model_102 (Model) (None, 10, 10) 24459
_________________________________________________________________
flatten_6 (Flatten) (None, 100) 0
_________________________________________________________________
dense_176 (Dense) (None, 10) 1010
=================================================================
Total params: 25,469
Trainable params: 25,469
Non-trainable params: 0
网络训练结果:
Epoch 23/25
- 36s - loss: 0.0533 - acc: 0.9835 - val_loss: 0.0719 - val_acc: 0.9794
Epoch 24/25
- 37s - loss: 0.0511 - acc: 0.9843 - val_loss: 0.0689 - val_acc: 0.9800
Epoch 25/25
- 37s - loss: 0.0473 - acc: 0.9860 - val_loss: 0.0700 - val_acc: 0.9802
test_loss: 0.06055343023035675 - test_acc: 0.9825000047683716
SimpleSeq2Seq 模型和 AttentionSeq2Seq 模型的预测精度分别为 0.9568、0.9825,说明添加注意力机制后,预测精度有了明显的提示。
声明:本文转自seq2seq模型案例分析
seq2seq模型案例分析的更多相关文章
- css笔记18:盒子模型案例分析示范
- 《大型网站技术架构:核心原理与案例分析》【PDF】下载
<大型网站技术架构:核心原理与案例分析>[PDF]下载链接: https://u253469.pipipan.com/fs/253469-230062557 内容简介 本书通过梳理大型网站 ...
- [转] 图解Seq2Seq模型、RNN结构、Encoder-Decoder模型 到 Attention
from : https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/ 一.Seq2Seq 模型 1. 简介 Sequence-to ...
- 用深度学习LSTM炒股:对冲基金案例分析
英伟达昨天一边发布“全球最大的GPU”,一边经历股价跳水20多美元,到今天发稿时间也没恢复过来.无数同学在后台问文摘菌,要不要抄一波底嘞? 今天用深度学习的序列模型预测股价已经取得了不错的效果,尤其是 ...
- 3.2_k-近邻算法案例分析
k-近邻算法案例分析 本案例使用最著名的”鸢尾“数据集,该数据集曾经被Fisher用在经典论文中,目前作为教科书般的数据样本预存在Scikit-learn的工具包中. 读入Iris数据集细节资 ...
- AI-Info-Micron-Insight:案例分析:美光使用数据和人工智能来发现、倾听和感觉
ylbtech-AI-Info-Micron-Insight:案例分析:美光使用数据和人工智能来发现.倾听和感觉 1.返回顶部 1. 案例分析:美光使用数据和人工智能来发现.倾听和感觉 内存芯片制造商 ...
- SOA架构设计和相关案例分析
一.SOA概念 1.定义: SOA,是一个组件模型,面向服务的体系架构,它将应用程序的不同服务通过这些服务之间定义良好的接口和契约联系起来,不涉及底层编程接口和通讯模型.服务层是SOA的基础,可以直接 ...
- 深度学习的seq2seq模型——本质是LSTM,训练过程是使得所有样本的p(y1,...,yT‘|x1,...,xT)概率之和最大
from:https://baijiahao.baidu.com/s?id=1584177164196579663&wfr=spider&for=pc seq2seq模型是以编码(En ...
- SOA架构设计的案例分析
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来.接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台. ...
- Python核心技术与实战——十|面向对象的案例分析
今天通过面向对象来对照一个案例分析一下,主要模拟敏捷开发过程中的迭代开发流程,巩固面向对象的程序设计思想. 我们从一个最简单的搜索做起,一步步的对其进行优化,首先我们要知道一个搜索引擎的构造:搜索器. ...
随机推荐
- ONVIF网络摄像头(IPC)客户端开发—ONVIF介绍
1.前言: 网上已经有很多关于ONVIF开发的资料,这里概括介绍一下ONVIF协议以及介绍一下我自己在开发ONVIF网络摄像头的一些流程和经验,做个开发记录和经验总结,以备将来查看,也可供他人参考 ...
- scikit-learn.datasets 机器学习库
scikit-learn是一个用于Python的机器学习库,提供了大量用于数据挖掘和数据分析的工具.以下是对这些函数和方法的简要描述: clear_data_home: 清除数据集目录的内容. dum ...
- [转帖]MySQL如何进行索引重建操作?
MySQL如何进行索引重建操作? - 潇湘隐者 - 博客园 (cnblogs.com) 在MySQL数据库中,没有类似于SQL Server数据库或Oracle数据库中索引重建的语法(ALTER IN ...
- [转帖]堆表&索引组织表
堆表&索引组织表 https://zhuanlan.zhihu.com/p/487271927 15 人赞同了该文章 很多大佬强调学习一定要看"原版英文材料". 比如再 ...
- [转帖]Docker资源(CPU/内存/磁盘IO/GPU)限制与分配指南
https://zhuanlan.zhihu.com/p/417472115 什么是cgroup? cgroups其名称源自控制组群(control groups)的简写,是Linux内核的一个功能, ...
- [转帖]linux中Shell日期转为时间戳的方法
http://www.nndssk.com/xtwt/169617hFPRvq.html shell中获取时间戳的方式为:date -d "$currentTime" +%s $ ...
- ARM下KVM虚拟化的损耗验证--redis
ARM下KVM虚拟化的损耗验证 摘要 看Windows 上面的 Workstation的虚拟机的 网络层的延迟特别高. 突然想之前统计都是直接在本地验证的, 只考虑了虚拟化CPU的性能损耗 没有考虑虚 ...
- gcore的学习
gcore的学习-解决jmap无法生成dump文件的一种方法 背景 周末在跆拳道馆看孩子练跆拳道. 开着笔记本翻到了 扣钉日记 公众号里面的讲解 想着自己也遇到过无法保存dump文件的情况. 所以想学 ...
- zookeeper的Leader选举源码解析
作者:京东物流 梁吉超 zookeeper是一个分布式服务框架,主要解决分布式应用中常见的多种数据问题,例如集群管理,状态同步等.为解决这些问题zookeeper需要Leader选举进行保障数据的强一 ...
- c++基础之变量和基本类型
之前我写过一系列的c/c++ 从汇编上解释它如何实现的博文.从汇编层面上看,确实c/c++的执行过程很清晰,甚至有的地方可以做相关优化.而c++有的地方就只是一个语法糖,或者说并没有转化到汇编中,而是 ...