spark 怎么读写 elasticsearch
参考文章:
- https://www.bmc.com/blogs/spark-elasticsearch-hadoop/
- https://blog.pythian.com/updating-elasticsearch-indexes-spark/
- https://qbox.io/blog/elasticsearch-in-apache-spark-python 这里有 RDD level 的写法,有些操作比如count, aggregation 在 DataFrame/DataSet level 不支持pushdown, 所有需要用到RDD level 的写法
Pre-requisite:
先装上 elasticsearch-hadoop 包
Step-by-Step guide
1. 先在ES创建3个document
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/1 -d '{
"school" : "Clemson"
}'
[mshuai@node1 ~]$ curl -XPUT --header 'Content-Type: application/json' http://your_ip:your_port/school/doc/2 -d '{
"school" : "Harvard"
}'
2. Spark 里面去读,这里是pyspark 代码
reader = spark.read.format("org.elasticsearch.spark.sql").option("es.read.metadata", "true").option("es.nodes.wan.only","true").option("es.port","your_port").option("es.net.ssl","false").option("es.nodes", "your_ip")
df = reader.load("school")
df.show()
输出这个格式的信息
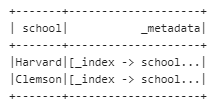
3. 接下来尝试update 一个记录,先得到一个要改的id
hot = df.filter(df["school"] == 'Harvard') \
.select(expr("_metadata._id as id")).withColumn('hot', lit(True))
hot.show()

4. 先来加一列
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.mapping.exclude"]='id'
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
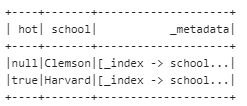
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
看,成功加了 hot 列,满足条件的记录赋了对应的值
5. 又来update已经存在的信息
esconf={}
esconf["es.mapping.id"] = "id"
esconf["es.nodes"] = "your_ip"
esconf["es.port"] = "your_port"
esconf["es.update.script.inline"] = "ctx._source.school = params.school"
esconf["es.update.script.params"] = "school:<SCU>"
esconf["es.write.operation"] = "update"
esconf["es.nodes.discovery"] = "false"
esconf["es.nodes.wan.only"] = "true"
hot.write.format("org.elasticsearch.spark.sql").options(**esconf).mode("append").save("school/doc")
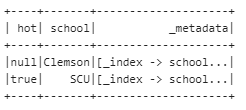
reader.load("school").show()
嗯。。。成功把Harvard改成了川大
另外,怎么upload attachment 到ES呢?可以用这个plugin Ingest Attachment Processor Plugin
END
spark 怎么读写 elasticsearch的更多相关文章
- 如何在spark中读写cassandra数据 ---- 分布式计算框架spark学习之六
由于预处理的数据都存储在cassandra里面,所以想要用spark进行数据分析的话,需要读取cassandra数据,并把分析结果也一并存回到cassandra:因此需要研究一下spark如何读写ca ...
- 【原创】大叔经验分享(26)hive通过外部表读写elasticsearch数据
hive通过外部表读写elasticsearch数据,和读写hbase数据差不多,差别是需要下载elasticsearch-hadoop-hive-6.6.2.jar,然后使用其中的EsStorage ...
- spark DataFrame 读写和保存数据
一.读写Parquet(DataFrame) Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源.前面的介绍中,我们已经涉及到了JSON.文本格式 ...
- spark block读写流程分析
之前分析了spark任务提交以及计算的流程,本文将分析在计算过程中数据的读写过程.我们知道:spark抽象出了RDD,在物理上RDD通常由多个Partition组成,一个partition对应一个bl ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...
- kafka spark steam 写入elasticsearch的部分问题
应用版本 elasticsearch 5.5 spark 2.2.0 hadoop 2.7 依赖包版本 docker cp /Users/cclient/.ivy2/cache/org.elastic ...
- Spark SQL读写方法
一.DataFrame:有列名的RDD 首先,我们知道SparkSQL的目的是用sql语句去操作RDD,和Hive类似.SparkSQL的核心结构是DataFrame,如果我们知道RDD里面的字段,也 ...
- Spark如何读写hive
原文引自:http://blog.csdn.net/zongzhiyuan/article/details/78076842 hive数据表建立可以在hive上建立,或者使用hiveContext.s ...
- spark mysql读写
val data2Mysql2 = (iterator: Iterator[(String, Int)]) => { var conn: Connection = null; var ps: P ...
- spark 集成elasticsearch
pyspark读写elasticsearch依赖elasticsearch-hadoop包,需要首先在这里下载,版本号可以通过自行修改url解决. """ write d ...
随机推荐
- Oracle 日期减年数、两日期相减
-- 日期减年数 SELECT add_months(DEF_DATE,12*USEFUL_LIFE) FROM S_USER --两日期相减 SELECT round(sysdate-PEI.STA ...
- 2 - 【RocketMQ 系列】CentOS 7.6 安装部署RocketMQ
二.开始安装部署RocketMQ 官方网站:https://rocketmq.apache.org/ 各版本要求: 1.版本选取 下载地址: https://github.com/apache/roc ...
- vue高频面试题
来源:B站程序员来了 第一部分:vue基础 1,v-if和v-for的优先级谁更高?同时出现该如何优化性能? 在同级出现的时候,render函数会将v-for和v-if同时渲染在一个名为_l的函数,在 ...
- Java 基于Hutool实现DES加解密
POM.XML配置 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="h ...
- 阅读翻译Mathematics for Machine Learning之2.8 Affine Subspaces
阅读翻译Mathematics for Machine Learning之2.8 Affine Subspaces 关于: 首次发表日期:2024-07-24 Mathematics for Mach ...
- 假期小结3Hadoop学习
学习Hadoop是一个很好的选择,因为它是大数据处理和分析领域最流行的框架之一.Hadoop提供了可靠.可扩展的分布式数据处理能力,适用于处理大规模数据和构建可靠的数据管道. 在学习Hadoop时,以 ...
- 【Spring】使用SpringTest报错 java.lang.NoSuchMethodError
完整报错信息: "C:\Program Files\Java\jdk1.8.0_301\bin\java.exe" -ea -Didea.test.cyclic.buffer.si ...
- Intel因特尔10700k CPU的核显驱动
下载地址: https://www.intel.cn/content/www/cn/zh/download/776137/intel-7th-10th-gen-processor-graphics-w ...
- 举例说明:ChatGPT和百度文心一言的差距
翻译: we employ ten sub-generators against one discriminator 百度的表现: ChatGPT的表现:
- 亲测可用的 Linux(Ubuntu18.04下)可运行的俄罗斯方块游戏的仿真环境—————————可用于强化学习算法的游戏模拟器环境
俄罗斯方块模拟器(tetris 游戏),Python库地址: https://gitee.com/devilmaycry812839668/gym-tetris 在Python3.7环境下亲测可用: ...