Apache Kylin(三)Kylin上手
Kylin 上手
根据Kylin 官方给出的测试数据,我们实际操作一下 Kylin。
1. 导入 Hive 数据
首先创建一个project,在界面左上角有个“Add Project” 按钮,这里我们创建的Project名为tuto。
进入Model 界面,从 Hive 中导入两张表:kylin_sales和 kylin_cal_dt
导入完成后可以在左边看到表的定义:
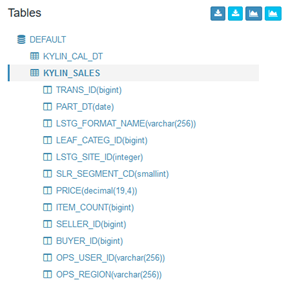
同时 Kylin 会在后台触发一个 MapReduce 任务,计算此表中每个列的基数。一般在隔几分钟后再刷新页面,就可以看到基数信息,如:
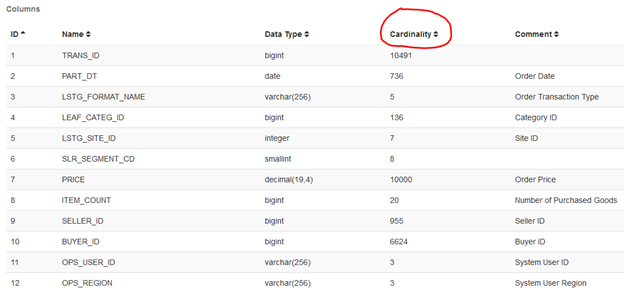
需要注意的是,这里 Kylin 对基数采用的是HyperLogLog的近似算法,与精确值略有误差。例如对TRANS_ID 的基数估计为 10491,而若是我们在Hive 中获取 TRANS_ID 的distinct count:
select count(distinct trans_id) from kylin_sales;
> 10000
可以看到计算的结果与kylin计算出的基数稍有误差,不过一般这种近似值作为参考值是足够的。
2. 创建数据模型
2.1. 选择事实表与维度表
数据模型(Data Model)是Cube 的基础,主要根据分析需求进行设计。有了数据模型后,定义Cube的时候就可以直接从此模型定义的表和列中进行选择了,省去了重复指定连接(JOIN)条件的步骤。基于一个数据模型可以创建多个Cube,方便减少用户的重复性工作。
在 Kylin web 界面的 Model 页面,创建一个新Model(也就是数据模型)。必须选择一个事实表,以及(可选)添加一个维度表。
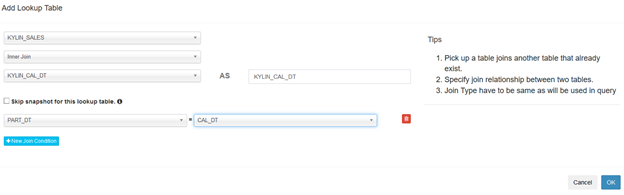
这里snapshot是指是否将维度表以快照(snapshot)的形式存储到内存中以供查询。当维度表小于300MB时,推荐启用维度表以快照形式存储,以简化Cube计算和提高系统整体效率。当维度表超过 300MB 时,则建议关闭维度表快照,以提升Cube构建的稳定性与查询的性能。
对于join key,也支持多组key。
2.2. 选择维度和度量
选择维度和度量的列,这里只是选择一个范围,并不代表这些列将来一定要用作 Cube 的维度或度量。可以把所有可能会用到的列都选进来,后续创建 Cube 的时候,将只能从这些列中进行选择。
选择维度列时,维度可以来自事实表或维度表,例如:

选择度量时,度量只能来自事实表或不加载进内存的维度表,如:
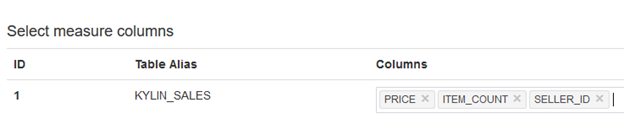
最后一步,是为模型补充分割时间列信息和过滤条件。如果此模型中的事实表记录是按时间增长的,那么可以指定一个日期/时间列作为模型的分割时间列,从而可以让Cube按此列做增量构建。
过滤(Filter)条件是指,如果想把一些记录忽略掉,那么这里可以设置一个过滤条件。Apache Kylin 在向 Hive 请求源数据的时候,会带上此过滤条件,如下所示,会只保留price 大于 0 的记录:
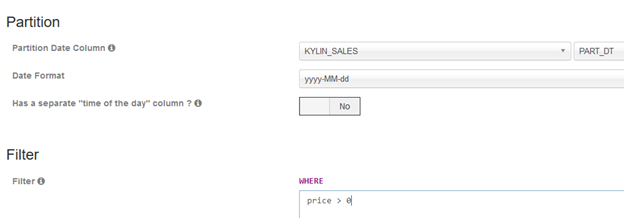
点击 Save 后,即可保存此 Model。
3. 创建 Cube
3.1. Cube Info
从左上角创建按钮新创建一个 Cube,并选择之前创建的Model:

3.2. Dimensions
然后添加Cube的维度:

3.3. Measures
接着是添加度量,Kylin支持的度量有SUM、MIN、MAX、COUNT、COUNT_DISTINCT、TOP_N、EXTENDED_COLUMN、PERCENTILE等。默认会创建一个Count(1) 度量。
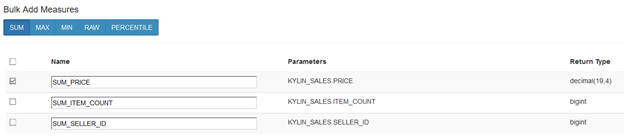
可以通过Bulk Add Measure 按钮批量添加度量。目前对于批量添加度量,Kylin仅支持SUM、MIN、MAX等简单函数。只需要选择度量类型,然后再选择需要计算的列即可:
如果需要添加复杂度量,点击“+Measure”按钮添加即可,如:

添加完后的结果为:

3.4. Refresh Setting
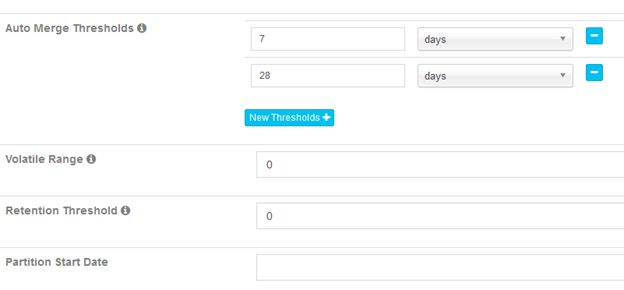
接下来是关于Cube数据刷新的设置,这里可以设置自动合并的阈值、自动合并触发时保留的阈值、数据保留的最小时间、以及第一个Segment的起点时间(如果Cube有分割时间列):
3.5. Advanced Setting
在此页面可以设置维度聚合组和Rowkey属性。
默认Kylin会把所有维度放在同一个聚合组(Aggregation Group,也称维度组)中,如果维度数较多(如 > 15),建议用户根据查询的习惯和模式,点击New Aggregation Group+ 命令,将维度分布到多个聚合组中。通过使用多个聚合组,可以大大降低Cube中Cuboid数量。
举个例子,一个Cube有(M+N)个维度,如果把这些维度都放置在一个组里,那么默认会有2(M+N) 个Cuboid;如果把这些维度分为两个不相交的聚合组,第一个组有M个维度,第二个组有N个维度,那么Cuboid的总数量将减少至2M + 2N ,会极大减少Cuboid的数量。
在单个聚合组中,可以对维度设置一些高级属性,如Mandatory Dimensions、Hierarchy Dimensions、Joint Dimensions 等。这几种属性都是为了优化Cube的计算而设计:
- Mandatory Dimensions(强制维度):指的是那些总是会出现在Where条件或Group By 语句里的维度。在指定某个维度为Mandatory Dimensions 后,Kylin可以不予计算那些不包含此维度的Cuboid,从而减少计算量
- Hierarchy Dimensions(层级维度):指一组有层级关系的维度,如“国家”、“省”、“市”。这里“国家“是最高级别的维度,”省“、”市“依次是次要级别。用户为按高级别维度进行查询,也会按低级别维度进行查询。但当查询低级别维度时,往往会带上高级别维度的条件,而不会孤立地查询低维度的数据。例如,用户会使用”国家“作为条件进行查询,也会使用”国家“+”省“+”市“的条件进行查询。通过指定层级维度,Kylin可以略过不满足此模式的Cuboid
- Joint Dimensions(联合维度):将多个维度视作为一个维度,在进行组合计算的时候,它们要们一起出现,要们均不出现。通常适用于以下几种情况:
- 总是一起查询的维度
- 彼此之间有一定映射关系,如USER_ID 和 EMAIL
- 基数很低的维度,如性别、布尔类型的属性
在此步骤中,web 界面里自动选择了要添加的维度到此聚合组中。然后用户可以根据模型特征和查询模式,设置高级维度属性。Hierarchy Dimension 和 Joint Dimension 可以设置多组,但是要主要的是,一个维度出现在某个属性中后,将不能再设置为另一种属性。但是一个维度是可以同时出现在多个聚合组中的。
添加完后的聚合组为:
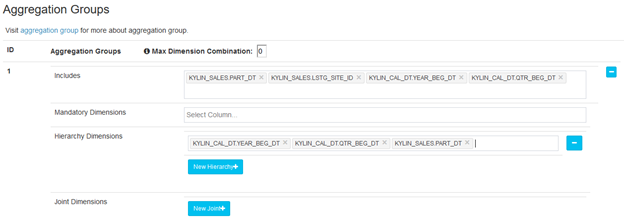
Kylin中,会将Cube的构建结果以Key-Value的形式存储到HBase中。而HBase是单行键索引,所以在存储时,但是Kylin又需要按照多个维度来对度量进行检索。所以在存储到HBase中时,Kylin会将多个维度拼接组成Rowkey。在HBase中的存储结构如下:
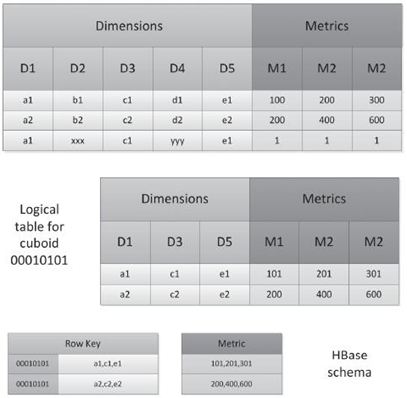
可以看到Dimensions 是rowkey,Metrics是value。由于同一维度中的数值长短不一,如国家名,短的如“中国”,长的如“巴布亚新几内亚”,因此将多个不同列的值进行拼接的时候,要么添加分隔符,要么通过某种编码使各个列所占的宽固定。Kylin为了能够在HBase上高效地进行存储和检索,会使用第二种方式对维度值进行编码。维度编码的优势有:
- 压缩信息存储空间;
- 提高扫描效率,减少解析开销。
对于各个维度在rowkey中的顺序,也会对查询的性能产生比较明显的影响。在这里用户可以根据查询的模式和习惯,通过拖拽的方式调整各个维度在Rowkey上的顺序:

一般原则是:将过滤频率高的列放置在过滤频率低的列之前,将基数高的列放在基数低的列之前。这样做的好处是:充分利用过滤条件来缩小在HBase中扫描的范围,从而提高查询的效率。
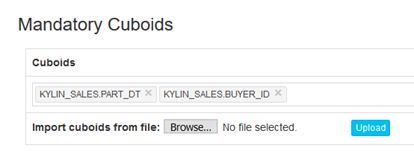
在构建Cube时,可以通过维度组合白名单(Mandatory Cuboids)确保想要构建的Cuboid能被成功构建:
Kylin支持对于复杂的COUNT DISTINCT度量进行字典构建,以保证查询性能。目前提供两种字典格式:Global Dictionary 和 Segment Dictionary。如下所示:
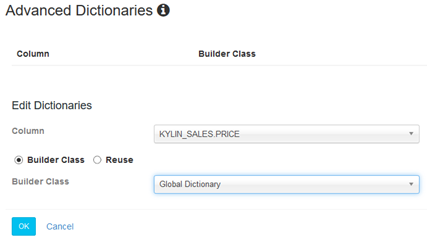
其中,Global Dictionary 可以将一个非Integer的值转为Integer值,以便bitmap进行去重,如果要计算的COUNT DISTINCT的列本身已经是Integer类型,那就不需要定义Global Dictionary。并且Global Dictionary会被所有segment共享,因此支持跨segments做上卷去重操作。
而Segment Dictionary 虽然也是用于精确计算COUNT DISTINCT 的字典,但与Global Dictionary不同的是,它是基于一个segment的值构建的,因此不支持跨segments的汇总计算。如果你的cube 不是分区的,或者能保证你的所有SQL按照partition column 进行group by,那么最好使用Segment Dictionary 而不是 Global Dictionary,这样可以避免单个字典过大的问题。
Kylin 目前支持两种构建Cube 的引擎:Mapreduce 和 Spark。如果你的Cube只有简单度量(如SUM、MIN、MAX),建议使用Spark。如果Cube中有复杂类型度量(如COUNT DISTINCT、TOP_N),建议使用MapReduce。
为了提升构建性能,可以在Advanced Snapshot Table中将维度表设置为全局维度表,同时提供不同的存储类型:

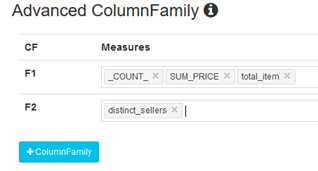
在构建时,可以在Advanced Column Family 中对度量进行分组,如果有超过一个的COUNT DISTINCT或 Top_N 度量,可以将它们放在更多的列簇中,以优化HBase的I/O:
3.6. Configuration Overwrites
在这里可以为 Cube 配置参数。首先Kylin的全局参数在conf/kylin.properties 文件中;如果Cube需要覆盖全局设置的话,需要在此指定。
例如,指定 kylin.hbase.region.cut 的值为 1,则此Cube在存储的时候,Kylin将会按每个HTable Region 存储空间为 1GB 来创建HTable Region。如果用户希望任务从YARN 中获取更多内存,可以设置kylin.engine.mr.config-override.mapreduce.map.memory.mb、kylin.engin.mr.config-override.mapreduce.map.java.opts 等mapreduce 相关参数。如果用户希望Cube的构建任务使用不同的YARN资源队列,可以设置kylin.engine.mr.config-override.mapreduce.job.queuename。这些配置均可以在Cube级别重写。

配置完后保存,Cube 就创建完毕了。
4. 构建Cube
新创建的Cube只有定义,没有计算的数据,状态还是DISABLED,所以不会被查询引擎挑中。为了让Cube有数据,需要对它进行构建。构建有两种:全量与增量。两者构建步骤完全一样,区别在于构建时读取的数据源是全集还是子集。
Cube的构建过程如下,由任务引擎调度执行:
- 创建临时Hive平表(从Hive中读取数据)
- 计算各维度的不同值,并收集各Cuboid的统计数据
- 创建并保存字典
- 保存Cuboid统计信息
- 创建HTable
- 计算Cube(一轮或若干轮计算)
- 将Cube计算结果转为HFile
- 加载HFile到HBase
- 更新Cube元数据
- 垃圾回收
上述步骤中,前5步是为了计算Cube而作的准备工作,如遍历维度值来创建字典,对数据做统计和估算以创建HTable等。第6步是真正的Cube计算,取决于使用的Cube算法,它可能是一轮MapReduce任务,也可能是N(在没有优化的情况下,N可以被视作维度数)轮迭代的MapReduce。
由于Cube运算的中间结果是以SequenceFile的格式存储在HDFS上的,所以为了导入HBase,还需要进行第7步操作,将这些结果转换成HFile。第8步通过HBase BulkLoad 将HFile导入到HBase 集群,这一步完成后,HTable就可以查询到数据。第9步更新Cube的数据,将此构建的Segment状态从“NEW”更新为“READY”,表示已经可供查询。最后一步,清理构建过程中生成的临时文件等垃圾,释放集群资源。
Monitor页面会显示当前项目下进气的构建任务
4.1. 全量构建与增量构建
对数据模型中没有指定分割时间列信息的Cube,Kylin会采用全量构建,即每次都从Hive中读取全部的数据来开始构建。通常适用于以下两种情形:
- 事实表的数据不是按时间增长的
- 事实表的数据比较小或更新频率很低,全量构建不会造成太大的存储空间浪费
进行增量构建的时候,Kylin每次会从Hive中读取一个时间范围内的数据,然后进行计算,并以一个Segment的形式保存。下次构建的时候,自动以上此结束的时间为起点时间,再选择新的终止时间进行构建。经过多次构建后,Cube中会有多个Segment依次按时间顺序进行排列,如Seg-1,Seg-2,…,Seg-N。进行查询的时候,Kylin会查询一个或多个Segment然后做聚合计算,以便返回正确的结果给请求者。
使用增量构建的优势是,每次只需要对新增数据进行计算,避免了对实例数据重复计算。对于数据量很大的Cube,使用增量计算是必须的。
下面是为构建一个Segment的Cube的数据框,需要用户选择时间范围:
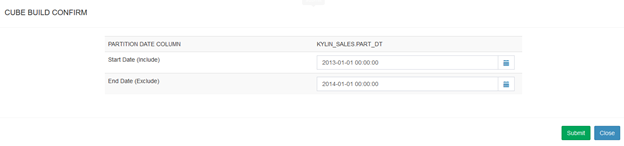
在从Hive中读取源数据的时候,Kylin会带上此条件。构建完毕后,Cube成为Ready状态:

4.2. 历史数据刷新
Cube构建完成后,如果某些历史数据发生了变动,需要针对相应的Segment重新进行计算,这种构建称为刷新。刷新通常只针对增量构建的Cube而言,因为全量构建的Cube只要重新全部构建就可以得到更新;而增量更新的Cube因为有多个Segment,需要先选择刷新的Segment,然后再进行刷新。如下所示:
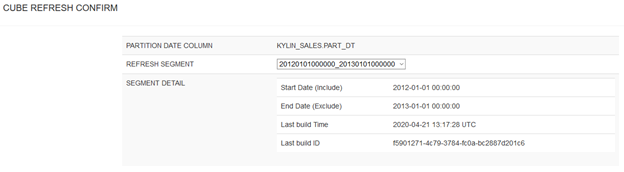
在刷新的同时,Cube仍可以被查询,只是返回的是陈旧数据。在Segment刷新完毕后,新Segment会立即生效,查询开始返回最新的数据。原Segment则成为垃圾,等待回收。
5. 查询
Cube构建好后,即可进行查询。不过只有当查询的模式跟Cube定义相匹配的时候,Kylin才能够使用Cube的数据来完成查询。Group By 的列和 Where 条件里的列,必须是在维度中定义的列,而SQL中的度量,应该跟Cube中定义的度量一致。
例如,我们查询每天的总销售额的结果为:

可以看到耗时仅0.68s,速度非常快。得益于Kylin的预计算,可以大大缩减数据查询的时间。
Apache Kylin(三)Kylin上手的更多相关文章
- [kylin] 部署kylin服务
一.工具准备 zookeeper3.4.6 (hadoop.hbase 管理工具) Hadoop. Hbase1.1.4 Kylin1.5.0-HBase1.1.3 Jdk1.7.80 Hive 二. ...
- Apache的三种工作模式及相关配置
Apache的三种工作模式 作为老牌服务器,Apache仍在不断地发展,就目前来说,它一共有三种稳定的MPM(Multi-Processing Module,多进程处理模块).它们分别是 prefor ...
- 三分钟上手Highcharts简易甘特图
根据业务需求,找到了这个很少使用的图形,话不多说,看看该如何使用.首先要引入支持文件:可根据链接下载. exporting.js:https://img.hcharts.cn/highcharts/m ...
- apache开源项目--kylin
Kylin 是一个开源的分布式的 OLAP 分析引擎,来自 eBay 公司开发,基于 Hadoop 提供 SQL 接口和 OLAP 接口,支持 TB 到 PB 级别的数据量. Kylin 是: 超级快 ...
- 在spring boot中三分钟上手apache顶级分布式链路追踪系统skywalking
原文:https://juejin.im/post/5cd10e81e51d453b560f2d53 skywalking在apache里全票通过成为了apache顶级链路追踪系统 项目地址:gith ...
- Kylin(三): Saiku
Saiku是一个轻量级的OLAP分析引擎,可以方便的扩展.嵌入和配置.Saiku通过REST API连接OLAP系统,利用其友好的界面为用户提供直观的分析数据的方式,它是基于jQuery做的前端界面. ...
- Apache Commons DbUtils 快速上手
原文出处:http://lavasoft.blog.51cto.com/62575/222771 Hibernate太复杂,iBatis不好用,JDBC代码太垃圾,DBUtils在简单与优美之间取得了 ...
- Apache的三种工作模式
Web服务器Apache目前一共有三种稳定的MPM(Multi-Processing Module,多进程处理模块)模式. 它们分别是prefork,worker和event,它们同时也代表这Apac ...
- Apache Shiro(三)-登录认证和权限管理MD5加密
md5 加密 在前面的例子里,用户密码是明文的,这样是有巨大风险的,一旦泄露,就不好了.所以,通常都会采用非对称加密,什么是非对称呢?就是不可逆的,而 md5 就是这样一个算法.如代码所示 123 用 ...
- 学习Apache(三)
对某个目录开启验证登录 <Directory /var/www/html/admin > AllowOverride All Order allow,deny Allow from all ...
随机推荐
- M9K内存使用教程
M9K内存使用教程 M9K内存是Altera内嵌的高密度存储阵列.现代的FPGA基本都包含类似的不同大小的内存. M9K的每个块有8192位(包含校验位实际是9216位).配置灵活.详细了解M9K可参 ...
- 批量解压上传SAP Note
最近在做印度GST相关的东西,需要手动给系统实施上百个SAP Note,十分繁琐. 标准事务代码SNOTE只支持每次上传一个Note,逐个上传大量Note会很麻烦,为此摸索出一个批量解压上传的流程,下 ...
- Linux 备忘
ls 通配符 匹配 ? 一个字符 * >=0个任意字符 [ai] a 或者 i [a-i] a/b/c/d...i [!a] 除了a cat cat -n test #加上行号 cat -b t ...
- 【爬虫数据集】滇西小哥YouTube频道TOP10热门视频的热评数据,共2W条!
目录 一.背景介绍 二.爬取目标 三.结果展示 四.演示视频 五.附完整数据 一.背景介绍 滇西小哥是一位来自中国云南省的视频博主,他在YouTube上拥有超过1000万的订阅者和上亿的观看量.他的视 ...
- centos7实现多网卡多线路
移动线路IP:179.15.5.253 网卡配置内容: TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static DEFROUT ...
- AI 一键生成高清短视频,视频 UP 主们卷起来...
现在短视频越来越火,据统计,2023年全球短视频用户数量已达 10 亿,预计到2027年将突破 24 亿.对于产品展示和用户营销来说,短视频已经成为重要阵地,不管你喜不喜欢它,你都得面对它,学会使用它 ...
- pageoffice6 在线编辑 word 文件时禁止拷贝到外部
有些特殊情况下,希望用户可以在线编辑Word文档,也允许用户拷贝本地电脑或网络上的资料到Word文档中进行编辑,但是不希望用户把在线Word文档中的内容另存到本地或选择并拷贝出去,此时只是禁用另存.禁 ...
- AIRIOT物联网低代码平台如何配置Modbus TCP协议?
AIRIOT物联网低代码平台稳定性超高,支持上百种驱动,各种主流驱动已在大型项目中通过验证,持续稳定运行. AIRIOT物联网低代码平台如何配置Modbus TCP协议?操作如下: AIRIOT与西门 ...
- 开源低代码框架 ReZero API 正式版本发布 ,界面操作直接生成API
一.ReZero简介 ReZero是一款.NET中间件 : 全网唯一界面操作就能生成API , 可以集成到任何.NET6+ API项目,无破坏性,也可让非.NET用户使用exe文件 免费开源:MIT ...
- .NET周刊【5月第3期 2024-05-19】
国内文章 WPF使用Shape实现复杂线条动画 https://www.cnblogs.com/czwy/p/18192720 文章介绍了利用WPF的Shape和动画功能,模仿CSS/SVG实现复杂的 ...