PPO-KL散度近端策略优化玩cartpole游戏
其实KL散度在这个游戏里的作用不大,游戏的action比较简单,不像LM里的action是一个很大的向量,可以直接用surr1,最大化surr1,实验测试确实是这样,而且KL的系数不能给太大,否则惩罚力度太大,action model 和ref model产生的action其实分布的差距并不太大
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pygame
import sys
from collections import deque # 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 2),
nn.Tanh(),
nn.Linear(2, 2), # CartPole的动作空间为2
nn.Softmax(dim=-1)
) def forward(self, x):
return self.fc(x) # 定义值网络
class ValueNetwork(nn.Module):
def __init__(self):
super(ValueNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 2),
nn.Tanh(),
nn.Linear(2, 1)
) def forward(self, x):
return self.fc(x) # 经验回放缓冲区
class RolloutBuffer:
def __init__(self):
self.states = []
self.actions = []
self.rewards = []
self.dones = []
self.log_probs = [] def store(self, state, action, reward, done, log_prob):
self.states.append(state)
self.actions.append(action)
self.rewards.append(reward)
self.dones.append(done)
self.log_probs.append(log_prob) def clear(self):
self.states = []
self.actions = []
self.rewards = []
self.dones = []
self.log_probs = [] def get_batch(self):
return (
torch.tensor(self.states, dtype=torch.float),
torch.tensor(self.actions, dtype=torch.long),
torch.tensor(self.rewards, dtype=torch.float),
torch.tensor(self.dones, dtype=torch.bool),
torch.tensor(self.log_probs, dtype=torch.float)
) # PPO更新函数
def ppo_update(policy_net, value_net, optimizer_policy, optimizer_value, buffer, epochs=100, gamma=0.99, clip_param=0.2):
states, actions, rewards, dones, old_log_probs = buffer.get_batch()
returns = []
advantages = []
G = 0
adv = 0
dones = dones.to(torch.int)
# print(dones)
for reward, done, value in zip(reversed(rewards), reversed(dones), reversed(value_net(states))):
if done:
G = 0
adv = 0
G = reward + gamma * G #蒙特卡洛回溯G值
delta = reward + gamma * value.item() * (1 - done) - value.item() #TD差分
# adv = delta + gamma * 0.95 * adv * (1 - done) #
adv = delta + adv*(1-done)
returns.insert(0, G)
advantages.insert(0, adv) returns = torch.tensor(returns, dtype=torch.float) #价值
advantages = torch.tensor(advantages, dtype=torch.float)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8) #add baseline for _ in range(epochs):
action_probs = policy_net(states)
dist = torch.distributions.Categorical(action_probs)
new_log_probs = dist.log_prob(actions)
ratio = (new_log_probs - old_log_probs).exp() KL = new_log_probs.exp()*(new_log_probs - old_log_probs).mean() #KL散度 p*log(p/p')
#下面三行是核心
surr1 = ratio * advantages PPO1,PPO2 = True,False
# print(surr1,KL*500)
if PPO1 == True:
actor_loss = -(surr1 - KL).mean() if PPO2 == True:
surr2 = torch.clamp(ratio, 1.0 - clip_param, 1.0 + clip_param) * advantages
actor_loss = -torch.min(surr1, surr2).mean() optimizer_policy.zero_grad()
actor_loss.backward()
optimizer_policy.step() value_loss = (returns - value_net(states)).pow(2).mean() optimizer_value.zero_grad()
value_loss.backward()
optimizer_value.step() # 初始化环境和模型
env = gym.make('CartPole-v1')
policy_net = PolicyNetwork()
value_net = ValueNetwork()
optimizer_policy = optim.Adam(policy_net.parameters(), lr=3e-4)
optimizer_value = optim.Adam(value_net.parameters(), lr=1e-3)
buffer = RolloutBuffer() # Pygame初始化
pygame.init()
screen = pygame.display.set_mode((600, 400))
clock = pygame.time.Clock() draw_on = False
# 训练循环
state = env.reset()
for episode in range(10000): # 训练轮次
done = False
state = state[0]
step= 0
while not done:
step+=1
state_tensor = torch.FloatTensor(state).unsqueeze(0)
action_probs = policy_net(state_tensor) #旧policy推理数据
dist = torch.distributions.Categorical(action_probs)
action = dist.sample()
log_prob = dist.log_prob(action) next_state, reward, done, _ ,_ = env.step(action.item())
buffer.store(state, action.item(), reward, done, log_prob) state = next_state # 实时显示
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit() if draw_on:
# 清屏并重新绘制
screen.fill((0, 0, 0))
cart_x = int(state[0] * 100 + 300) # 位置转换为屏幕坐标
pygame.draw.rect(screen, (0, 128, 255), (cart_x, 300, 50, 30))
pygame.draw.line(screen, (255, 0, 0), (cart_x + 25, 300), (cart_x + 25 - int(50 * np.sin(state[2])), 300 - int(50 * np.cos(state[2]))), 5)
pygame.display.flip()
clock.tick(60) if step >2000:
draw_on = True
ppo_update(policy_net, value_net, optimizer_policy, optimizer_value, buffer)
buffer.clear()
state = env.reset()
print(f'Episode {episode} completed , reward: {step}.') # 结束训练
env.close()
pygame.quit()
效果:
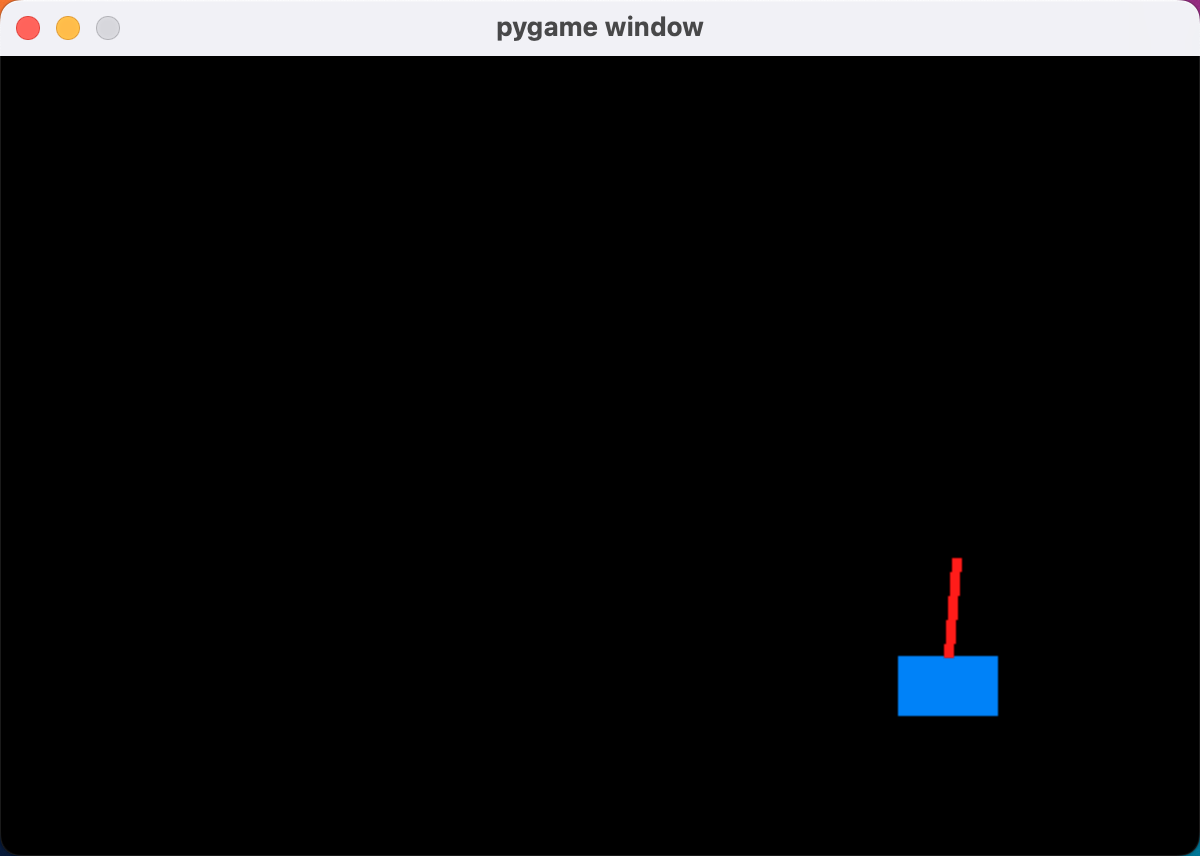
PPO-KL散度近端策略优化玩cartpole游戏的更多相关文章
- TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- DRL 教程 | 如何保持运动小车上的旗杆屹立不倒?TensorFlow利用A3C算法训练智能体玩CartPole游戏
本教程讲解如何使用深度强化学习训练一个可以在 CartPole 游戏中获胜的模型.研究人员使用 tf.keras.OpenAI 训练了一个使用「异步优势动作评价」(Asynchronous Advan ...
- KL散度的理解(GAN网络的优化)
原文地址Count Bayesie 这篇文章是博客Count Bayesie上的文章Kullback-Leibler Divergence Explained 的学习笔记,原文对 KL散度 的概念诠释 ...
- (转)KL散度的理解
KL散度(KL divergence) 全称:Kullback-Leibler Divergence. 用途:比较两个概率分布的接近程度.在统计应用中,我们经常需要用一个简单的,近似的概率分布 f * ...
- PRML读书会第十章 Approximate Inference(近似推断,变分推断,KL散度,平均场, Mean Field )
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:02:04 我们在前面看到,概率推断的核心任务就是计算某分布下的某个函数的期望.或者计算边缘概率分布.条件 ...
- 非负矩阵分解(1):准则函数及KL散度
作者:桂. 时间:2017-04-06 12:29:26 链接:http://www.cnblogs.com/xingshansi/p/6672908.html 声明:欢迎被转载,不过记得注明出处哦 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 机器学习:Kullback-Leibler Divergence (KL 散度)
今天,我们介绍机器学习里非常常用的一个概念,KL 散度,这是一个用来衡量两个概率分布的相似性的一个度量指标.我们知道,现实世界里的任何观察都可以看成表示成信息和数据,一般来说,我们无法获取数据的总体, ...
- 相对熵(KL散度)
https://blog.csdn.net/weixinhum/article/details/85064685 上一篇文章我们简单介绍了信息熵的概念,知道了信息熵可以表达数据的信息量大小,是信息处理 ...
- ELBO 与 KL散度
浅谈KL散度 一.第一种理解 相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information dive ...
随机推荐
- 为什么 L1 正则化能做特征选择而 L2 正则化不能
假设我们的模型只有一个参数 \(w\),损失函数为 \(L(w)\),加入 L1 和 L2 正则化后的损失函数分别记为 \(J_1(w), J_2(w)\): \[\begin{gathered} J ...
- Linux 配置Git
前言:请各大网友尊重本人原创知识分享,谨记本人博客:南国以南i 一.用git --version命令检查是否已经安装 二.下载git源码并解压 wget https://github.com/git/ ...
- 【C#上位机】西门子1200PLC实用定位控制程序案例
1. 引言 新阁教育这篇文章是一篇综合性非常强的文章,从PLC输入输出及步进电机接线开始,到PLC运动控制程序编写,再到后续的ModbusTCP通信协议及上位机编程实现最终控制,涉及知识面比较广,能够 ...
- Linux程序崩溃自启动方法
linux进程挂掉后,可以通过配置 systemd 来自动启动服务 1.创建 systemd 服务文件,例如:huyang.service,需要放置在系统文件夹 /etc/systemd/system ...
- html-testRunner在unittest测试套件中的使用
废话不多说,直接上代码 代码 __author__ = 'huyang:十一的杂文录' import unittest import HtmlTestRunner import sys sys.pat ...
- HarmonyOS元服务开发实践:桌面卡片字典
本文转载分享自华为开发者论坛<HarmonyOS元服务开发实践:桌面卡片字典>,作者:蛟龙腾飞 一.项目说明 1.DEMO创意为卡片字典. 2.不同卡片显示不同内容:微卡.小卡.中卡 ...
- 演示webuploader和cropperjs图片裁剪上传
最近有个项目要在浏览器端裁剪并上传图片.由于缺乏人力,只能我上阵杀敌.通过参考各种文章,最后决定用cropperjs进行图片裁剪,用webuploader上传文件.本文涉及到的知识至少有Java基础. ...
- UE4中HTC Vive 手柄如何抓取物体
想知道 HTC Vive 手柄如何抓取物体? HTC Vive 的手柄有许多功能,在游戏里你可以用手柄射箭,可以用手柄拾取木棍等等,但是这些是如何设置的呢?来看看我们的公开课教程吧. 本期教程为上半部 ...
- 阿里云云原生加速器企业硬之城携手阿里云 Serverless 应用引擎(SAE)打造低代码平台
简介: 作为入选阿里云首期云原生加速器的企业,硬之城此前也获得了阿里云首批产品生态集成认证,通过云原生加速器项目携手阿里云共建更加丰富的云原生产业生态圈,加速云原生落地. 作者 | 陈泽涛(硬之城产品 ...
- Pandas+ SLS SQL:融合灵活性和高性能的数据透视
简介: Pandas是一个十分强大的python数据分析工具,也是各种数据建模的标准工具.Pandas擅长处理数字型数据和时间序列数据.Pandas的第一大优势在于,封装了一些复杂的代码实现过程,只需 ...