神经网络优化篇:理解mini-batch梯度下降法(Understanding mini-batch gradient descent)
理解mini-batch梯度下降法
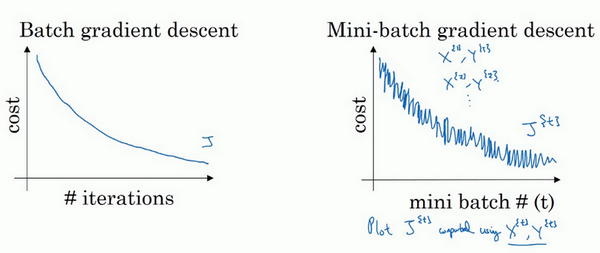
使用batch梯度下降法时,每次迭代都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数\(J\)是迭代次数的一个函数,它应该会随着每次迭代而减少,如果\(J\)在某次迭代中增加了,那肯定出了问题,也许的学习率太大。
使用mini-batch梯度下降法,如果作出成本函数在整个过程中的图,则并不是每次迭代都是下降的,特别是在每次迭代中,要处理的是\(X^{\{t\}}\)和\(Y^{\{ t\}}\),如果要作出成本函数\(J^{\{ t\}}\)的图,而\(J^{\{t\}}\)只和\(X^{\{ t\}}\),\(Y^{\{t\}}\)有关,也就是每次迭代下都在训练不同的样本集或者说训练不同的mini-batch,如果要作出成本函数\(J\)的图,很可能会看到这样的结果,走向朝下,但有更多的噪声,所以如果作出\(J^{\{t\}}\)的图,因为在训练mini-batch梯度下降法时,会经过多代,可能会看到这样的曲线。没有每次迭代都下降是不要紧的,但走势应该向下,噪声产生的原因在于也许\(X^{\{1\}}\)和\(Y^{\{1\}}\)是比较容易计算的mini-batch,因此成本会低一些。不过也许出于偶然,\(X^{\{2\}}\)和\(Y^{\{2\}}\)是比较难运算的mini-batch,或许需要一些残缺的样本,这样一来,成本会更高一些,所以才会出现这些摆动,因为是在运行mini-batch梯度下降法作出成本函数图。
需要决定的变量之一是mini-batch的大小,\(m\)就是训练集的大小,极端情况下,如果mini-batch的大小等于\(m\),其实就是batch梯度下降法,在这种极端情况下,就有了mini-batch \(X^{\{1\}}\)和\(Y^{\{1\}}\),并且该mini-batch等于整个训练集,所以把mini-batch大小设为\(m\)可以得到batch梯度下降法。
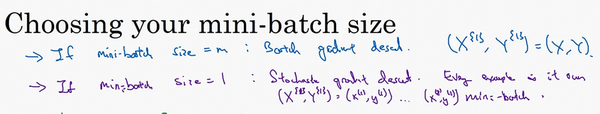
另一个极端情况,假设mini-batch大小为1,就有了新的算法,叫做随机梯度下降法,每个样本都是独立的mini-batch,当看第一个mini-batch,也就是\(X^{\{1\}}\)和\(Y^{\{1\}}\),如果mini-batch大小为1,它就是的第一个训练样本,这就是的第一个训练样本。接着再看第二个mini-batch,也就是第二个训练样本,采取梯度下降步骤,然后是第三个训练样本,以此类推,一次只处理一个。
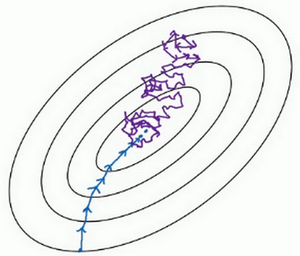
看在两种极端下成本函数的优化情况,如果这是想要最小化的成本函数的轮廓,最小值在那里,batch梯度下降法从某处开始,相对噪声低些,幅度也大一些,可以继续找最小值。
相反,在随机梯度下降法中,从某一点开始,重新选取一个起始点,每次迭代,只对一个样本进行梯度下降,大部分时候向着全局最小值靠近,有时候会远离最小值,因为那个样本恰好给指的方向不对,因此随机梯度下降法是有很多噪声的,平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此。
实际上选择的mini-batch大小在二者之间,大小在1和\(m\)之间,而1太小了,\(m\)太大了,原因在于如果使用batch梯度下降法,mini-batch的大小为\(m\),每个迭代需要处理大量训练样本,该算法的主要弊端在于特别是在训练样本数量巨大的时候,单次迭代耗时太长。如果训练样本不大,batch梯度下降法运行地很好。

相反,如果使用随机梯度下降法,如果只要处理一个样本,那这个方法很好,这样做没有问题,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,会失去所有向量化带给的加速,因为一次性只处理了一个训练样本,这样效率过于低下,所以实践中最好选择不大不小的mini-batch尺寸,实际上学习率达到最快。会发现两个好处,一方面,得到了大量向量化,上个视频中用过的例子中,如果mini-batch大小为1000个样本,就可以对1000个样本向量化,比一次性处理多个样本快得多。另一方面,不需要等待整个训练集被处理完就可以开始进行后续工作,再用一下上个视频的数字,每次训练集允许采取5000个梯度下降步骤,所以实际上一些位于中间的mini-batch大小效果最好。
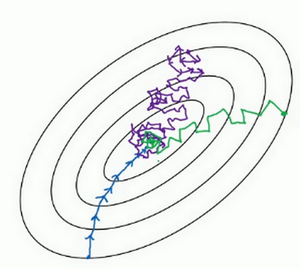
用mini-batch梯度下降法,从这里开始,一次迭代这样做,两次,三次,四次,它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向,它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减少学习率,在下个视频会讲到学习率衰减,也就是如何减小学习率。
如果mini-batch大小既不是1也不是\(m\),应该取中间值,那应该怎么选择呢?其实是有指导原则的。
首先,如果训练集较小,直接使用batch梯度下降法,样本集较小就没必要使用mini-batch梯度下降法,可以快速处理整个训练集,所以使用batch梯度下降法也很好,这里的少是说小于2000个样本,这样比较适合使用batch梯度下降法。不然,样本数目较大的话,一般的mini-batch大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的\(n\)次方,代码会运行地快一些,64就是2的6次方,以此类推,128是2的7次方,256是2的8次方,512是2的9次方。所以经常把mini-batch大小设成2的次方。在上一个视频里,的mini-batch大小设为了1000,建议可以试一下1024,也就是2的10次方。也有mini-batch的大小为1024,不过比较少见,64到512的mini-batch比较常见。
最后需要注意的是在的mini-batch中,要确保\(X^{\{ t\}}\)和\(Y^{\{t\}}\)要符合CPU/GPU内存,取决于的应用方向以及训练集的大小。如果处理的mini-batch和CPU/GPU内存不相符,不管用什么方法处理数据,会注意到算法的表现急转直下变得惨不忍睹,所以希望对一般人们使用的mini-batch大小有一个直观了解。事实上mini-batch大小是另一个重要的变量,需要做一个快速尝试,才能找到能够最有效地减少成本函数的那个,一般会尝试几个不同的值,几个不同的2次方,然后看能否找到一个让梯度下降优化算法最高效的大小。希望这些能够指导如何开始找到这一数值。
学会了如何执行mini-batch梯度下降,令算法运行得更快,特别是在训练样本数目较大的情况下。
神经网络优化篇:理解mini-batch梯度下降法(Understanding mini-batch gradient descent)的更多相关文章
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- Gradient Descent 梯度下降法-R实现
梯度下降法: [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 应用:求线性回归方程的系数 目标:最小化损失 ...
- 梯度下降法Gradient descent(最速下降法Steepest Descent)
最陡下降法(steepest descent method)又称梯度下降法(英语:Gradient descent)是一个一阶最优化算法. 函数值下降最快的方向是什么?沿负梯度方向 d=−gk
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.1_2.2_mini-batch梯度下降法
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 mini-batch gradient descent mini-batch梯度下降法 我们将训练数据组合到一个大的矩阵中 \(X=\b ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- 批量梯度下降(Batch gradient descent) C++
At each step the weight vector is moved in the direction of the greatest rate of decrease of the err ...
- 神经网络优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
1. SGD Batch Gradient Descent 在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
随机推荐
- Mybatisplus3.5.1+shardingsphere-jdbc5.1.1分表
注意使用雪花ID的话,查询ID时候必须使用long类型的ID,不要使用MP自带的默认的Serializable类型.否则会提示分片主键id数据类型和分片算法不匹配Inline sharding alg ...
- 33家国内外知名的手机广告平台的SDK名单汇总,吐血推荐
下面格式:第一行是广告平台名称,第二行是SDK的包名特征,第三行是平台网站 多盟cn.domob.androidhttp://www.domob.cn/百度推广SDK com.baidu统计SDK c ...
- 我为什么要从PhoneGap中逃离? 转
我为什么要从PhoneGap中逃离? 摘要:每一位程序员都有自己的技术信仰,我也不例外.但当技术信仰遇到实际工作中的问题时,你又要怎么做呢?还记得刚刚接触HTML5做跨平台开发的时候这样的问题就摆在 ...
- 实用的命令行终端增强软件:Tabby
还是那句话:出众的软件有很多,适合自己的才是最好的. 一.软件介绍 Tabby是一个开源免费软件,支持Windows.macOS和Linux系统.它提供了一个高度可定制的终端界面,可以通过多种方式添加 ...
- [Python]对称日!
def check(year): if (year%4 == 0 and year%100 != 0) or year%400 == 0: return True else: return False ...
- 使用TS进行Vue-Router的Meta类型扩展
目录 1.前言 2.解决 1.前言 使用Vue-Router时,会将一些字段信息附加到路由的Meta对象里面,比如图标icon,标题,权限等,如下: { path: '/billboard/board ...
- promise时效架构升级方案的实施及落地
一.项目背景 为什么需要架构升级 promise时效包含两个子系统:内核时效计算系统(系统核心是时效计算)和组件化时效系统(系统核心是复杂业务处理以及多种时效业务聚合,承接结算下单黄金流程流量),后者 ...
- Electron-React18-MacOS桌面管理系统|electron27+react仿mac桌面
基于React18+Electron27+ArcoDesign仿macOS桌面端系统框架ElectronMacOS. electron-react-macOs 基于electron27.x+vite4 ...
- Quartz核心原理之架构及基本元素介绍
1 什么是Quartz Quartz是一个作业调度框架,它可以与J2EE和J2SE应用相结合,也可以单独使用.它能够创建多个甚至数万个jobs这样复杂的程序,jobs可以做成标准的java组件或EJB ...
- 大白话说Python+Flask入门(六)Flask SQLAlchemy操作mysql数据库
写在前面 这篇文章被搁置真的太久了,不知不觉拖到了周三了,当然,也算跟falsk系列说再见的时候,真没什么好神秘的,就是个数据库操作,就大家都知道的CRUD吧. Flask SQLAlchemy的使用 ...