influxdb得导出与导入
转载请注明出处:
1、备份元数据
基本语法:
influxd backup <path-to-backup>
备份元数据,没有任何其他参数,备份将只转移当前状态的系统元数据到path-to-backup。path-to-backup为备份保存的目录,不存在会自动创建。
该备份会备份所有数据库以及所有保存策略下得数据。
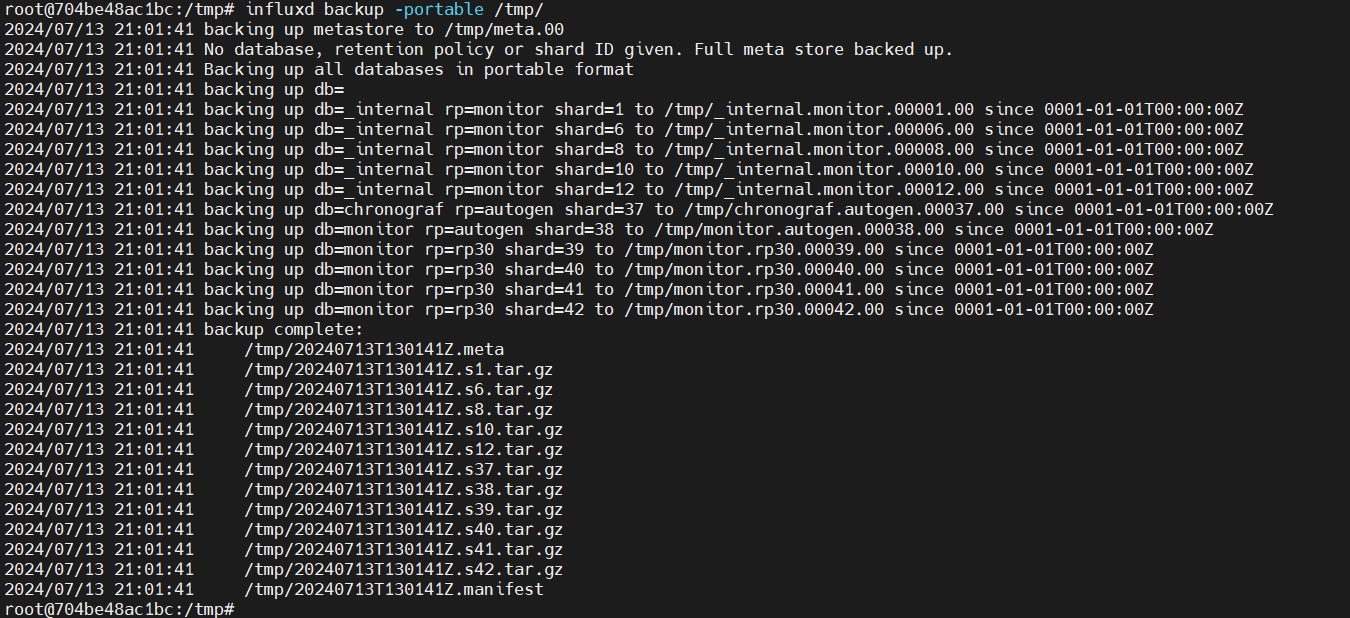
导出常用得其他参数:
root@704be48ac1bc:/# influxd backup -h Creates a backup copy of specified InfluxDB OSS database(s) and saves the files in an Enterprise-compatible
format to PATH (directory where backups are saved). Usage: influxd backup [options] PATH -portable
Required to generate backup files in a portable format that can be restored to InfluxDB OSS or InfluxDB
Enterprise. Use unless the legacy backup is required.
-host <host:port>
InfluxDB OSS host to back up from. Optional. Defaults to 127.0.0.1:8088.
-db <name>
InfluxDB OSS database name to back up. Optional. If not specified, all databases are backed up when
using '-portable'.
-rp <name>
Retention policy to use for the backup. Optional. If not specified, all retention policies are used by
default.
-shard <id>
The identifier of the shard to back up. Optional. If specified, '-rp <rp_name>' is required.
-start <2015-12-24T08:12:23Z>
Include all points starting with specified timestamp (RFC3339 format).
Not compatible with '-since <timestamp>'.
-end <2015-12-24T08:12:23Z>
Exclude all points after timestamp (RFC3339 format).
Not compatible with '-since <timestamp>'.
-since <2015-12-24T08:12:23Z>
Create an incremental backup of all points after the timestamp (RFC3339 format). Optional.
Recommend using '-start <timestamp>' instead.
-skip-errors
Optional flag to continue backing up the remaining shards when the current shard fails to backup.
backup: flag: help requested
具体如下:
Usage: influxd backup [options] PATH
-portable # 在线备份,必选
-host <host:port> # 需要备份的influxdb服务机器地址,可选,Defaults to 127.0.0.1:8088.
-db <name> # 需要备份的db名称,可选,若没有指定,将备份所有数据库
-rp <name> # 备份某个保留策略的数据,未指定,则备份所有rp的数据。
-shard <id> # 需要备份的shard id,可选,若指定了备份shard,必须先选择rp
-start # 需要备份的数据的起始时间,timestamp (RFC3339 format). 不能和-since一起使用
-end # 需要备份的数据的结束时间,timestamp (RFC3339 format). 不能和-since一起使用
-since # 备份这个timestamp之后的数据,建议用-start <timestamp>代替
-skip-errors # 可选,当备份shards时,跳过备份失败的shard,继续备份其他shard。
2.influxdb导入
1.先删除数据库
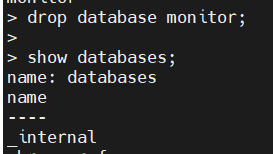
2.导入备份数据:

这种方式只能导入按个数据库进行导入;
3.导入其他配置项参数:
root@704be48ac1bc:/# influxd restore -h Uses backup copies from the specified PATH to restore databases or specific shards from InfluxDB OSS
or InfluxDB Enterprise to an InfluxDB OSS instance. Usage: influxd restore -portable [options] PATH Note: Restore using the '-portable' option consumes files in an improved Enterprise-compatible
format that includes a file manifest. Options:
-portable
Required to activate the portable restore mode. If not specified, the legacy restore mode is used.
-host <host:port>
InfluxDB OSS host to connect to where the data will be restored. Defaults to '127.0.0.1:8088'.
-db <name>
Name of database to be restored from the backup (InfluxDB OSS or InfluxDB Enterprise)
-newdb <name>
Name of the InfluxDB OSS database into which the archived data will be imported on the target system.
Optional. If not given, then the value of '-db <db_name>' is used. The new database name must be unique
to the target system.
-rp <name>
Name of retention policy from the backup that will be restored. Optional.
Requires that '-db <db_name>' is specified.
-newrp <name>
Name of the retention policy to be created on the target system. Optional. Requires that '-rp <rp_name>'
is set. If not given, the '-rp <rp_name>' value is used.
-shard <id>
Identifier of the shard to be restored. Optional. If specified, then '-db <db_name>' and '-rp <rp_name>' are
required.
PATH
Path to directory containing the backup files. restore: flag: help requested
主要作用:
Usage: influxd restore -portable [options] PATH
Options:
-portable #
-host <host:port>
-db <name> # 从备份数据的哪个库恢复数据Name of database to be restored from the backup
-newdb <name>
# 数据恢复到新库名称,若没有指定,选择-db <name>的名称。newdb必须不存在,恢复时会自动创建
-rp <name> # 从备份数据的哪个rp恢复数据,指定了-rp,必须指定-db
-newrp <name> #恢复数据新的rp名称,newrp必须存在。指定了-rp,未指定-newrp则使用-rp
-shard <id> # 需要恢复的shard,如果指定了'-db <db_name>' and '-rp <rp_name>',必须-shard<id>
PATH #备份数据文件list
4.第二种导入方式:
删除influxdb数据库存储得元数据文件,将influxdb得数据库元文件目录指定为备份得目录,然后再重启influxdb数据库即可完成导入
influxd restore -metadir <path-to-meta-or-data-directory> <path-to-backup>
从/var/lib/influxdb/ 目录下删除meta目录,即 rm -rf /var/lib/influxdb/meta,然后重启influxdb,service influxdb restart。
influxdb得导出与导入的更多相关文章
- [moka同学笔记]PHPexcel之excel导出和导入
原案例来自http://www.sucaihuo.com/有修改 1.目录结构(文件不用解释,应该都可以看得懂,直接看代码)
- ORACLE 导出(exp) & 导入(imp)
导出(exp) & 导入(imp) 利用Export可将数据从数据库中提取出来,就是将select的结果存到一个FS二进制文件上 利用Import则可将提取出来的数据送回到Ora ...
- OCR磁盘的导出和导入、备份和恢复以及移动(ocrconfig命令的应用)
数据库版本:10.2.0.1 一,使用导出.导入进行备份和恢复 Oracle推荐在对集群做调整时,比如增加.删除节点之前,应该对OCR做一个备份,可以使用export 备份到指定文件.如果做了repl ...
- paip 自定义输入法多多输入法词库的备份导出以及导入
paip 自定义输入法词库的备份导出以及导入 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn.net/ ...
- mysql如何利用Navicat 导出和导入数据库
MySql是我们经常用到的数据,无论是开发人员用来练习,还是小型私服游戏服务器,或者是个人软件使用,都十分方便.对于做一些个人辅助软件, 选择mysql数据库是个明智的选择,有一个好的工具更是事半功倍 ...
- 用命令行导出和导入MySQL数据库
php 用命令行导出和导入MySQL数据库 命令行导出数据库:1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录如我输入的命令行:cd C:\Program Files ...
- Java CSV操作(导出和导入)
Java CSV操作(导出和导入) CSV是逗号分隔文件(Comma Separated Values)的首字母英文缩写,是一种用来存储数据的纯文本格式,通常用于电子表格或数据库软件.在 CSV文件 ...
- oracle数据库数据导出和导入
oracle的客户端里面的bin下面有两个可执行文件,名称分别为exp.exe和imp.exe. 他俩的用途就是导出和导入数据用的. 全库 导出:exp 用户名/密码@数据库名 full=y file ...
- shell导出和导入redis
1.导出redis #!/bin/bash REDIS_HOST=localhost REDIS_PORT=6379 REDIS_DB=1 KEYNAME=redis:hash:* KEYFILE=k ...
- .Net程序员学用Oracle系列(19):我知道的导出和导入
1.传统的导出/导入工具 1.1.EXP 命令详解 1.2.IMP 命令详解 1.3.EXP/IMP 使用技巧 2.新的导出/导入工具 2.1.EXPDP/IMPDP 参数说明 2.2.EXPDP/I ...
随机推荐
- AIRIOT物联网低代码平台如何配置Modbus TCP协议?
AIRIOT物联网低代码平台稳定性超高,支持上百种驱动,各种主流驱动已在大型项目中通过验证,持续稳定运行. AIRIOT物联网低代码平台如何配置Modbus TCP协议?操作如下: AIRIOT与西门 ...
- AIRIOT物联网低代码平台如何配置Modbus RTU协议?
MBRTU即MODBUS RTU的简称,MODBUS是OSI模型第7层上的应用层报文传输协议,它在连接至不同类型总线或网络的设备之间提供客户机/服务器通信.平台的MBRTU协议是建立在TCP协议之上的 ...
- kafka集群(zookeeper)
部署环境准备 kafka集群部署 ip地址 主机名 安装软件 10.0.0.131 mcwkafka01 zookeeper.kafka 10.0.0.132 mcwkafka02 zookeeper ...
- Django——form组件的全局钩子
前面提到过的都是针对单个字段的校验,如果想同时对多个字段进行校验,就可以使用全局钩子(编写全局钩子预留的clean方法,可以获取到多个字段并进行校验) 注意: ---- 默认的校验.自定义正则规则的校 ...
- kubernetes 二次开发-认证,鉴权(1)
基于webhook的认证 授权过程 认证授权服务需要满足如下kubernetes的规范 kubernetes api-server组件发送 http post 请求 url:https://authn ...
- docker安装Kafka(windows版)
windows环境安装docker参考安装docker桌面版(Windows) 这一步如果出现报错的话可以直接输入wsl -l -v命令来查看当前Ubuntu的wsl版本 安装Kafka需要先安装 z ...
- 还在拼冗长的WhereIf吗?100行代码解放这个操作
通常我们在做一些数据过滤的操作的时候,经常需要做一些判断再进行是否要对其进行条件过滤. 普通做法 最原始的做法我们是先通过If()判断是否需要进行数据过滤,然后再对数据源使用Where来过滤数据. 示 ...
- Vue3等比例缩放图片组件
本文由 ChatMoney团队出品 有些情况我们需要在各种刁钻的情况下都要保持图片比例不变,比如用户缩放窗口等改变布局的情况.实现原理就是通过容器的宽度和内边距在保持你想要的比例. 以下是基础功能的组 ...
- INFINI Labs 产品更新 | Easysearch 支持 SQL 查询、Console 告警功能支持邮件等多渠道
INFINI Labs 产品又更新啦~.本次更新概要如下:Easysearch 新增 SQL 插件和JDBC 驱动,支持 SQL 查询,支持 SQL 常用函数等:Console 针对告警功能做了升级优 ...
- shell基础概述
1.0 编程的目的 计算机的发明,是为了用机器取代/解放人力,而编程的目的则是将人类的思想流程按照某种能够被计算机识别的表达方式传递给计算机,从而达到让计算机能够像人脑/电脑一样自动执行的效果. 编程 ...