[转帖]计算机体系结构-重排序缓存ROB
https://zhuanlan.zhihu.com/p/501631371
在现代处理器中,重排序缓存(Reorder Buffer,即ROB)是一个至关重要的概念,一个标准的乱序执行处理器在其多个流水线环节中都会涉及重排序缓存,而Tomasulo算法一文也指出Tomasulo算法的最大缺点可以由重排序缓存补足,因此了解重排序缓存是十分有必要的。本文重点回答了以下几个问题:
- 为什么需要重排序缓存?
- 重排序缓存的结构是怎样的?
- 重排序缓存如何工作?
- 重排序缓存有什么优缺点?
1、为什么需要ROB
在乱序执行的处理器内核中,处理器会按序发射指令,乱序执行,最后记分牌算法和Tomasulo算法会乱序提交指令,乱序提交指的是一旦指令执行完毕且可以写回(记分牌可能因为读后写冲突而不允许写回),那就立刻写回。
而Tomasulo一文指出乱序提交正是Tomasulo最大的缺点。这是因为冯诺依曼结构向程序员承诺了处理器会按照程序的顺序来执行指令,因此程序员在调试程序的时候会希望当他在某行代码停下来的时候,代码前面的指令全部执行完,而代码后面的指令一条都没有执行,但是很显然,一个乱序执行、乱序提交的机器是没办法达到程序员的预期的。另外,因为控制指令、程序异常和外部中断也会截断指令流,所以通过顺序提交指令来实现精确中断(这里的中断是指中断指令流)至关重要。
因为记分牌和Tomasulo没办法完成精确中断,所以设计人员提出了Reorder Buffer(重排序缓存,ROB)的概念。重排序缓存的目的是让乱序执行的指令被顺序地提交,这个设计理念现在已经成为乱序处理器的基石,可以说,没有重排序缓存,就没有现代的乱序处理器。
那么,重排序缓存的结构是怎样的?它是怎么实现顺序提交和精确中断的?这两个问题本文会逐步解答。
2、ROB的原理
ROB的核心思想是记录下指令在程序中的顺序,一条指令在执行完毕之后不会立马提交(这里的提交指的是修改处理器状态,如修改逻辑寄存器堆),而是先在Buffer中等待,等到前面的所有指令都提交完毕,才可以提交结果到逻辑寄存器堆。想象一个FIFO队列,指令在发射的时候进队,然后在提交的时候出队,通过这么一个FIFO逻辑就可以实现指令的按序提交。
2.1、ROB如何改造Tomasulo
ROB的故事很简单,接下里让我们看看ROB是如何实现修改Tomasulo的,图1是经ROB改进的Tomasulo的结构。

图1:结合ROB的Tomasulo结构
和原始的Tomasulo结构(如图2)相比,结合ROB的Tomasulo主要有三点改动:一是增加了Reorder Buffer(即ROB);二是CDB总线不再直通逻辑寄存器堆,而是直通ROB;三是指令需要从ROB读取数据。ROB在这里就像是一个FIFO队列,指令在发射时入队,在提交时出队。
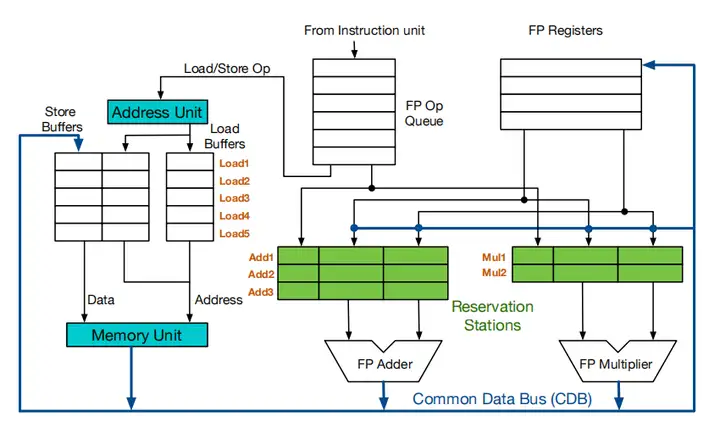
图2:原始Tomasulo
高屋建瓴地说,ROB实现了指令的顺序提交,并且增加了指令发射的效率。ROB具体是如何实现这两个目标的呢?为说明清楚,文章接下来会先讲解ROB的数据结构,然后用一个调度实例来演示说明ROB如何实现顺序提交,最后汇总信息,再次分析这个结构的优缺点。
2.2、ROB的数据结构
图3显示了ROB所包含的信息,PPT里还解读了ROB这么做的优点。在Tomasulo一文中我提到保留站的编号起到了寄存器重命名的作用,而ROB在每条指令发射的时候也会为其分配一个编号,这个编号正好可以取代保留站编号;ROB中包含Busy位,指示某一行是否正保存有指令;State位用来指示保存的指令当前的运行情况,ROB就是通过State的信息来判断某条指令是否可以提交,当最老的指令还没到提交阶段时,ROB中的所有指令都要等待,不能提交;Destination指示指令的目的寄存器;Value保存指令的结果,当指令可以提交,就直接提交Value到逻辑寄存器。

图3:ROB的数据结构
ROB的Value还有别的作用:在一条指令执行完毕但还不能提交时,后序指令有可能从ROB中读取Value。
通过ROB可以实现顺序提交和精确中断。同时,ROB的结构对分支预测也十分友好,因为分支预测有可能失败,所以处理器有处理错误预测的需求,而ROB的存在为此提供了两点便利:一是方便清除错误的指令,因为ROB保证了指令的顺序,所以只需要在分支指令提交的时候检查分支结果,如果分支错误,就清除掉ROB现存的所有指令;二是方便恢复处理器状态,ROB通过各个表项实现了寄存器重命名,ROB实际上在用表项充当物理寄存器,而指令修改ROB物理寄存器不修改逻辑寄存器的做法便于在分支预测失败时恢复处理器状态(因为分支指令之后的所有指令都没有提交,没有修改逻辑寄存器)。
下面第三节将用一个实际案例来讲解ROB是如何实现顺序提交的。
3、调度流程讲解
实际案例使用了南京大学王炜老师体系结构课的部分内容,下面先展示PPT内容,再对PPT内容进行讲解,即以PPT内容-讲解文段-PPT内容-讲解文段.....的方式进行讲解。
3.1、实际案例讲解
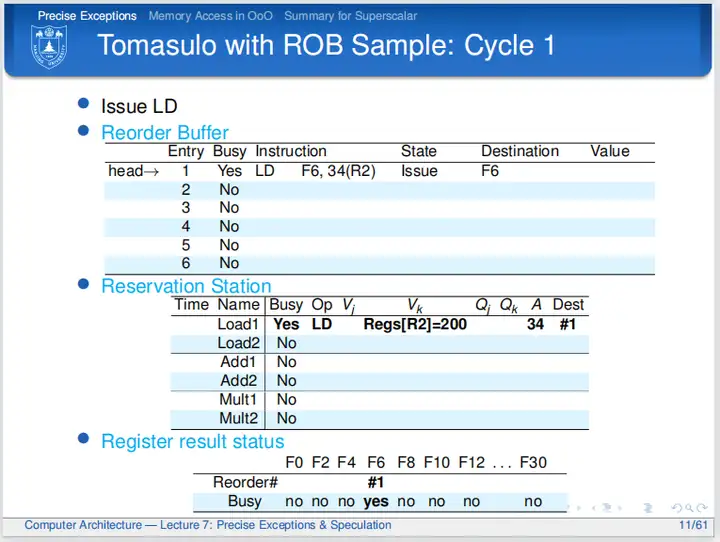
cycle 1
第一个周期,LD指令发射,和Tomasulo不一样的地方在于,在ROB结构中指令在发射的时候会同时改写ROB:处理器会在ROB中按顺序找到一个空行写入指令,置Busy位为Yes,表示当前行含有指令信息;置State为Issue,表示当前指令刚刚完成发射;并在Destination处标记目的寄存器编号。在寄存器结果状态表中,不再用保留站编号来标记寄存器,而是用ROB编号标记,这么做是有好处,之后会对这个做法做进一步解读。
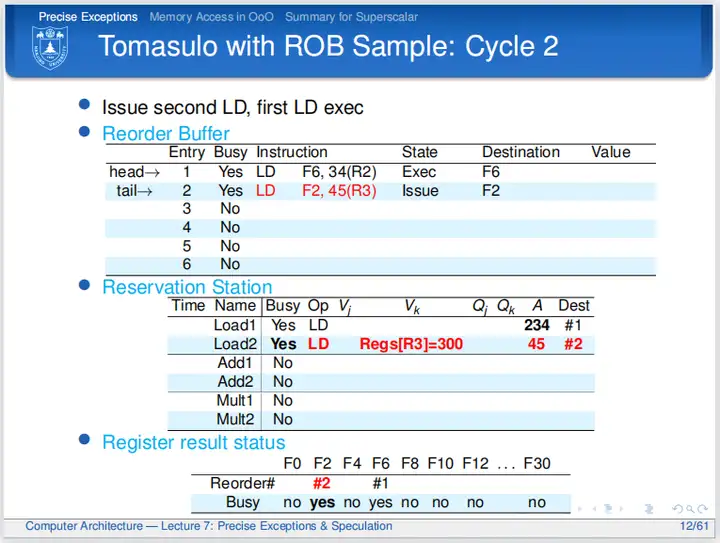
cycle 2
第二个周期,第一条LD指令计算地址和取数(可以在这个周期实现取数,也可以在下一个周期实现取数,这是微体系结构所关注的事情),在周期结束时地址计算完毕且取出数据(取出数据这一点没有体现在PPT中),地址数据写入保留站,并且ROB中的State改为Exec,表示指令执行完毕;因为ROB还有空余行,所以第二条LD可以发射到ROB和保留站,并用ROB的编号标记寄存器结果状态表。
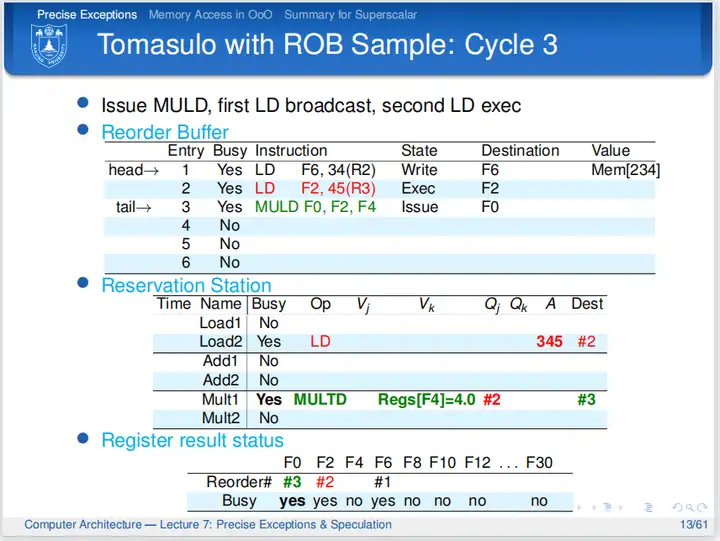
cycle 3
第三个周期,第一条LD指令写回,周期结束时写回结果到ROB,并且清除保留站中的信息,并置ROB的State为Write,表示指令完成写回,此时指令还没有提交,所以没有改写逻辑寄存器;第二条LD指令计算地址和取数;因为ROB还有空间,所以第三条指令得以发射,但是第三条指令需要F2的数据,通过查询寄存器结果状态表,指令得知该数据由ROB的#2指令算得,所以第三条指令标记#2,等待数据。
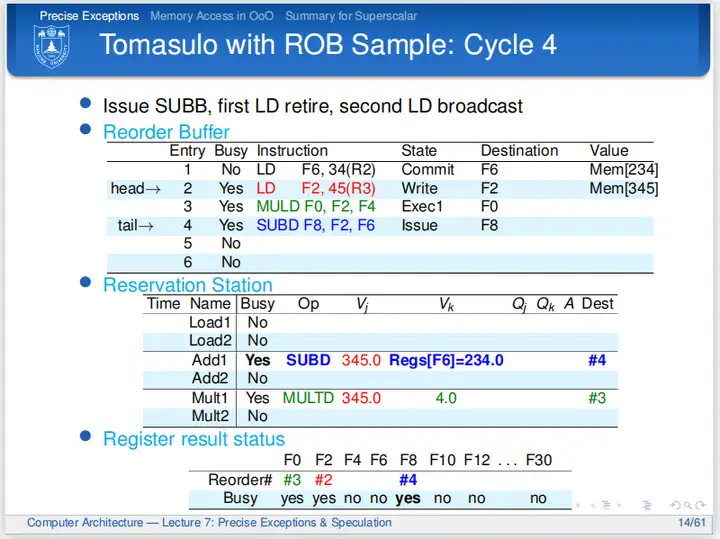
cycle 4
第四个周期,第一条LD指令是最老的指令,所以可以提交,周期结束时更新逻辑寄存器,ROB的头指针指向下一条指令,第一条LD指令的Busy位置为No,表明ROB第一行不再包含指令信息;第二条指令写数据到ROB,并且通过CDB总线广播数据给第三、第四条指令;第三条指令收到广播,开始执行(这里MULD立刻开始执行显得有点快了,其实也可以从下一周期才开始执行,接收到广播之后什么时候开始执行是由微体系结构决定的);第四条指令发射到ROB、保留站,通过广播直接接收F2的数据。
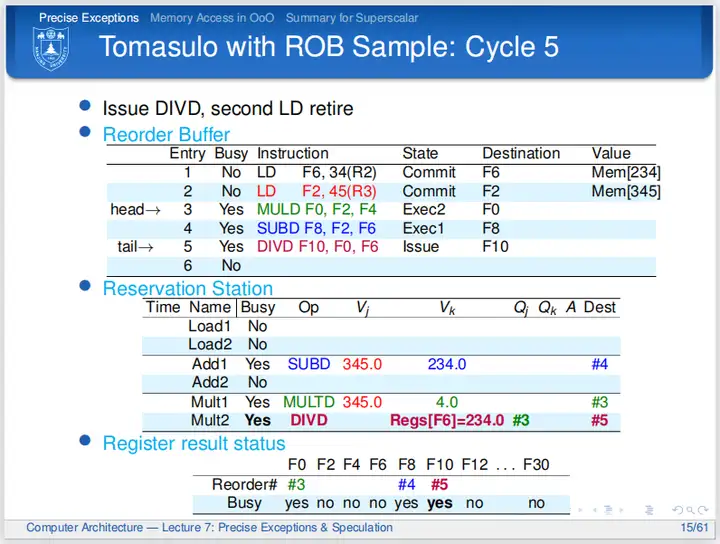
cycle 5
第五个周期,第二条LD指令可以提交,周期结束时置ROB的Busy位为No,更新逻辑寄存器;第三条指令还在执行;第四条指令也开始执行;第五条指令发射,通过查询寄存器结果状态表得知F0由ROB中的#3指令算得,现在需要等待。
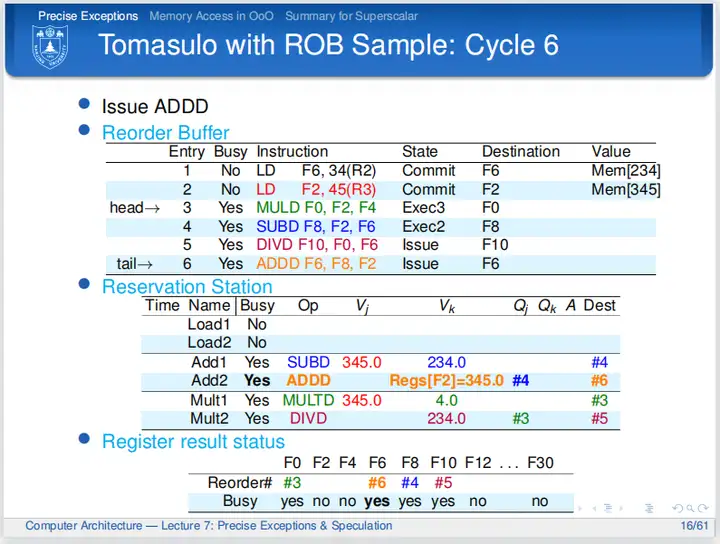
cycle 6
第六个周期,第三条、第四条指令还在执行;第五条指令在等待;第六条指令发射,通过查询寄存器结果状态表的值F8由ROB中的#4指令算得,现在需要等待。

cycle 7
第七个周期,第三条指令还在执行(乘法指令总是很花时间);第四条指令已经执行完毕,周期结束时写回数据到ROB,周期时间内通过CDB广播数据;第五条指令等待乘法指令的结果;第六条指令之前在等待#4指令的结果,这个周期内#4指令通过CDB广播了自己的结果,因此第六条指令得以抓取数据,并开始执行,周期结束时改写State为Exec1,这表明第六条指令已经完成了“执行阶段1”.

第八个周期
第八个周期,第三条指令还在执行;第四条指令虽然上一周期就已经写回,但是因为头指针不指向自己,说明还有前序指令没有提交,SUBD出于顺序提交的考虑只能等待前面的指令提交完才能提交;第五条指令仍在等待;第六条指令完成“执行阶段2”.
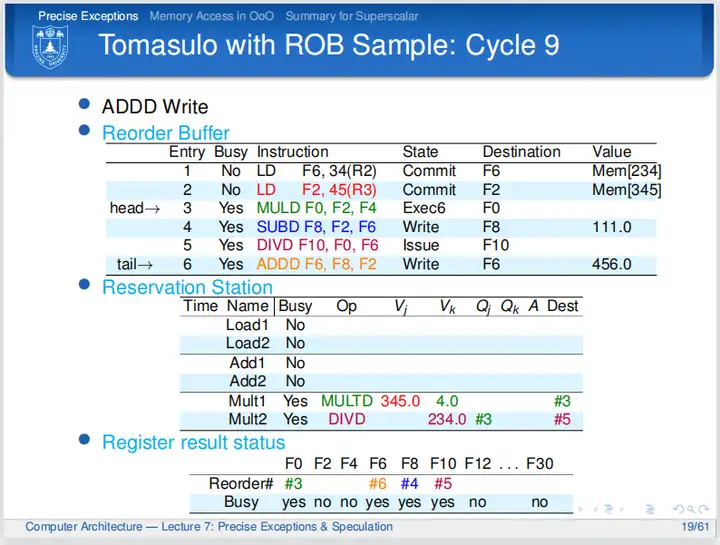
cycle 9
第九个周期,乘法指令还是没有完成自己的任务;第四条、第五条指令无奈,还是等待;第六条指令在这个周期写回,周期结束时结果写回到ROB,清除保留站信息。
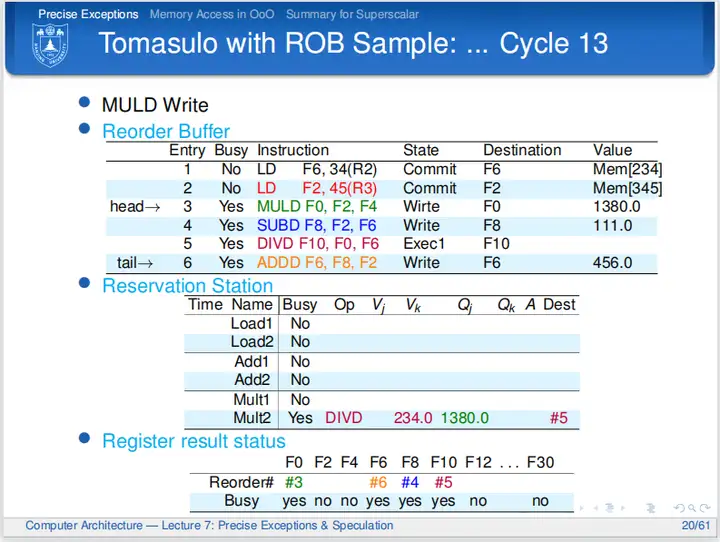
cycle 13
乘法指令执行周期太多,直接从第九跳到第十三个周期。第十三个周期,乘法指令写回,周期结束时结果写回到ROB,清除保留站信息,周期时间内指令结果通过CDB广播;第四条指令等待第三条指令提交;第五条指令接收到广播并执行完“执行阶段1”;第六条指令等待前序指令提交。
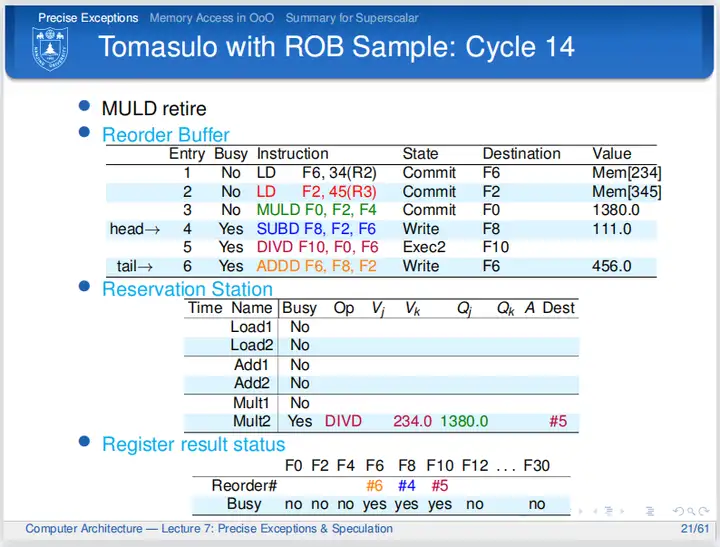
cycle 14
第十四个周期,乘法指令提交,周期结束时置ROB的Busy位为No,表明ROB第三行不再保存有指令,周期结束时更新逻辑寄存器;第四条指令马上就可以提交;第五条指令完成“执行阶段2";第六条指令等待前序指令提交。
再之后的过程就是第四条指令提交,然后第五条指令执行完毕后写回、提交,最后第六条指令提交,至此六条指令就完成了乱序执行、顺序提交的过程。
3.2、要点总结和补充(重点)
- 在使用ROB的Tomasulo中,指令能否发射主要观察两点——保留站是否有空闲和ROB是否有空闲,如果都有空闲,就可以发射,发射之后指令会分别占据保留站、ROB一个表项,并用ROB的编号标记寄存器结果状态表;
- 如果指令不能从逻辑寄存器堆读取到所需数据,就会根据寄存器结果状态表的查询结果查询数据,此时会有三个情况:一是数据由正在执行的指令得出,此时指令需要在保留站中监听CDB;二是数据正在ROB中,但是没有提交,此时指令会从ROB中读出数据;三是数据正在CDB总线上广播,此时指令读取CDB的数据;
- 一旦指令的数据准备完毕,就开始执行,执行可能需要很多个周期,此时别的类似指令就要在保留站中等待,值得注意的是,在上面的案例中指令在执行时并不会清除保留站,而实际上此时可以清除保留站了,这样做的优点会在第四节说明;
- 指令执行完毕后就可以写回,数据会被写回到ROB,但是暂时还不会更新逻辑寄存器堆,同时数据会由CDB广播出去;
- 当一条指令成为ROB中最老的指令时,即ROB的头指针指向该指令时,该指令就可以提交,提交周期结束时逻辑寄存器会被更新,ROB的对应Busy位会被置为无效,头指针会指向下一条指令。
4、ROB的优缺点
相比于原始的Tomasulo,使用ROB的Tomasulo主要改动了三点:使用ROB编号而不是保留站编号来标记寄存器结果状态表;CDB总线直通ROB而不直通逻辑寄存器堆;指令的源数据可以从寄存器堆、CDB总线和ROB中取得。
4.1、让保留站变得更加灵活
这三点改动中的第一点为基于ROB实现的乱序机器带来了好处,不过这个好处在第三节没有体现出来。第三节的实例在指令执行过程中不会清除保留站,但是这其实是可以办到的。原始的Tomasulo在指令执行时不可以清除保留站,因为指令需要用保留站的编号来标记指令输出和目的寄存器,如果允许指令执行时清除保留站,那么保留站编号就可能被后序指令重用,一旦编号被重用,后序指令监听CDB总线的行为就会变得混乱,而且前序指令的结果有可能错误地写入到逻辑寄存器中。
举个例子,比如前序指令占据加法保留站第一行,使用add1编号标记目的寄存器,假设目的寄存器是二号寄存器,并且前序指令一旦执行就清除保留站信息,那后序指令就有可能在前序指令执行时被发射到保留站第一行,此时后序指令会重用add1编号,假如后序指令目的寄存器是四号寄存器,那等到前序指令写回的时候,就有二号、四号两个逻辑寄存器被add1的结果重写,这样就出错了。同时,如果后序有指令要取得四号寄存器的值,那么根据寄存器结果状态表,后序指令就会监听add1结果,此时最开始的指令就会错误地把数据广播给后序指令,后序指令取得了错误的数据,处理器因此变得混乱。
到这里读者应该很好地理解了这一点:原始的Tomasulo不允许指令执行时清除保留站。但是这么做是不好的,因为后序指令能否发射和保留站是否有空余有关系,如果指令总是不解放保留站,那后续指令就可能会卡死在发射阶段,从而指令流水线也会被截断。
采用ROB就可以解决这个问题,因为ROB中使用ROB编号来标记输出和目的寄存器,因此即使清除保留站,也不会出现上面例子中重用编号的情况,这样一来保留站就可以在指令执行时被清除,后序指令有了更多的缓冲空间。
4.2、实现顺序提交,支持分支预测
使用ROB的初心是为了实现精确中断,而从第三节的实例中我们清楚地看到了这一点:ROB结构通过FIFO结构精确地实现了指令的顺序提交。
而且在第三节中没有体现出这一个优点:ROB支持分支预测。记分牌和原始的Tomasulo是很难支持分支预测的,因为指令乱序提交会给分支预测的清除指令和状态恢复带来极大的麻烦。而ROB则很轻松,因为指令总是按顺序提交,所以我们完全可以在分支指令提交的时候去检测分支结果,如果预测失败,就清除掉ROB中的所有指令即可,实现方法就是把ROB所有的表项的Busy位置为无效,同时在下一个周期使用分支指令指定的地址取指。
4.3、增加硬件资源
ROB也有缺点。在基于ROB的Tomasulo算法中,一个逻辑寄存器的结果被拷贝到太多地方,数据可能存在逻辑寄存器中,也可能存在保留站中,还可能存在ROB中,即一个数据需要三倍于数据长度的存储空间,而在记分牌算法里一个寄存器的值只会存在于逻辑寄存器中。
另外,指令读取数据不仅通过逻辑寄存器和CDB,还通过ROB,这需要ROB配置读口,增大布线压力,且要在读取数据的线路的末尾增加选择器(把ROB的数据加入到选择器中),这会潜在地增加关键路径长度。在多发射的处理器中,ROB需要支持多端口读,在一个四发射的机器里,ROB需要支持八个读端口,压力很大。
5、总结
重排序缓存(ROB)通过一个类似FIFO的结构让Tomasulo算法实现了指令的顺序提交,为程序员调试程序、处理器处理中断异常提供了便利,同时让分支预测的处理变得更简单。ROB可以被用作寄存器重命名中的物理寄存器,借助ROB,Tomasulo中的保留站(在此之前保留站被当作物理寄存器)得以被解放,处理器的发射效率进一步提高,但是ROB也增加了处理器的资源消耗和布线压力。总的来说,在需要精确中断和分支预测的现代处理器中,ROB是一个基石性质的概念,每一个高性能处理器核都要有ROB。
[转帖]计算机体系结构-重排序缓存ROB的更多相关文章
- CPU指令重排序与MESI缓存一致性
一.重排序场景 class ResortDemo { int a = 0; boolean flag = false; public void writer() { a = 1; //1 flag = ...
- Java内存模型深度解析:重排序 --转
原文地址:http://www.codeceo.com/article/java-memeory-2.html 数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间 ...
- java内存模型-重排序
数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性.数据依赖分下列三种类型: 名称 代码示例 说明 写后读 a = 1;b = a; 写一个变量之 ...
- 深入理解Java内存模型(二)——重排序
本文属于作者原创,原文发表于InfoQ:http://www.infoq.com/cn/articles/java-memory-model-2 数据依赖性 如果两个操作访问同一个变量,且这两个操作中 ...
- 【转】深入理解Java内存模型(二)——重排序
数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性.数据依赖分下列三种类型: 名称 代码示例 说明 写后读 a = 1;b = a; 写一个变量之 ...
- Java重排序
重排序数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性.数据依赖分下列三种类型: 名称 代码示例 说明 写后读 a = 1;b = a; 写一个 ...
- 深入理解JMM(Java内存模型) --(二)重排序
[转载自并发编程网 – ifeve.com 原文链接:http://ifeve.com/tag/jmm/] 数据依赖性 如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存 ...
- J.U.C JMM. pipeline.指令重排序,happen-before
pipeline: 现在的CPU一般采用流水线方式来执行指令.一个指令执行周期被分成:取值,译码,执行,访存,写会,更新PC若干阶段.然后,多条指令可以同时存在于流水线中,同时被执行,来提高系统的吞吐 ...
- 【java多线程系列】java内存模型与指令重排序
在多线程编程中,需要处理两个最核心的问题,线程之间如何通信及线程之间如何同步,线程之间通信指的是线程之间通过何种机制交换信息,同步指的是如何控制不同线程之间操作发生的相对顺序.很多读者可能会说这还不简 ...
- 不得不提的volatile及指令重排序(happen-before)
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
随机推荐
- 如何用华为云ModelArts平台玩转Llama2
本文分享自华为云社区<如何用华为云ModelArts平台玩转Llama2>,作者:码上开花_Lancer. 天哪~~ Llama2模型开源了拉!! Llama2不仅开源了预训练模型,而且还 ...
- 解决大模型“开发难”,昇思MindSpore自动并行技术应用实践
本文分享自华为云社区<DTSE Tech Talk|第35期:解决大模型"开发难",昇思MindSpore自动并行技术应用实践>,作者华为云社区精选. 昇思MindSp ...
- 云图说|图解制品仓库CodeArts Artifact
摘要:制品仓库用于存放由源码编译生成的.可运行的二进制文件,重要作用是实现制品文件的可信存储,支撑软件开发活动. 本文分享自华为云社区<[云图说]第277期 图解制品仓库CodeArts Art ...
- 号外!5G+X联创营华为云官网上线,5G 创业春天来了!
摘要:为助力互联网行业客户与伙伴实现降本增效.抓住新趋势,华为云发起"5G+X"联创营计划. 会议室里,产品经理和程序员们唇枪舌战,陷入激烈得讨(zheng)论(chao). 产品 ...
- 一文带你了解GaussDB(DWS) 的Roach逻辑备份实现原理
摘要:Roach工具是GaussDB(DWS)推出的一款主力的备份恢复工具,包含物理与逻辑备份两种主要能力,本文着重于讲解Roach逻辑备份的实现原理. 一.简介 在大数据时代,数据的完整和可靠性成为 ...
- vue-grid-layout数据可视化图表面板优化过程所遇问题汇总
对于drag事件不熟悉的,请先阅读:<drag事件详解:html5鼠标拖动排序及resize实现方案分析及实践> 之前老项目grafana面板,如下图所示(GEM添加图表是直接到图表编辑, ...
- 从 ByteHouse 网关,看如何进一步提升 OLAP 引擎性能
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 随着数字化转型的加速,企业面临着海量数据收集.处理和分析挑战.ClickHouse因其分析速度快.高性能的特点 ...
- 【django drf】 阶段练习
目录 需求 settings.py views.py urls.py serializers.py permissions.py page.py authenticate.py model.py 权限 ...
- QA32增强
一.QA32报表新增字段 二.QA32报表程序RQEEAL10 结构增加字段,该结构就是报表展示字段列的结构 表新增字段 找到报表展示的子例程 找到程序RQEEAL10,子例程中新增隐式增强 隐式增强 ...
- Divide by Zero 2021 and Codeforces Round #714 (Div. 2) 个人补题记录
补题链接:Here A. Array and Peaks 题意:给定 数组大小 \(n\) 和 峰值点 \(k\) 请问是否存在这样的排序,不存在则输出-1 先序从 i = 2 开始填,依次 i += ...