CPU指令重排序与MESI缓存一致性
一、重排序场景

class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
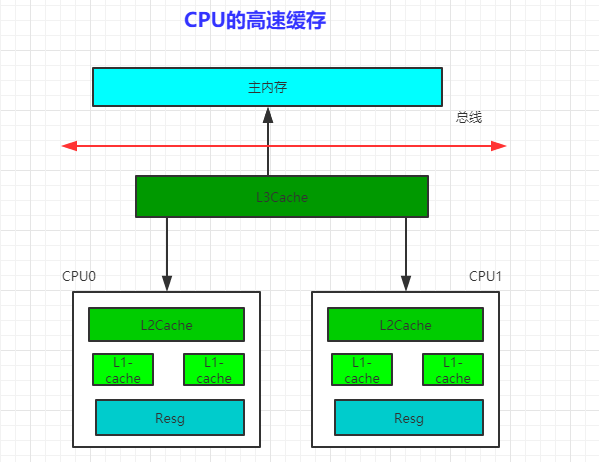
三、缓存一致性协议
据不一致

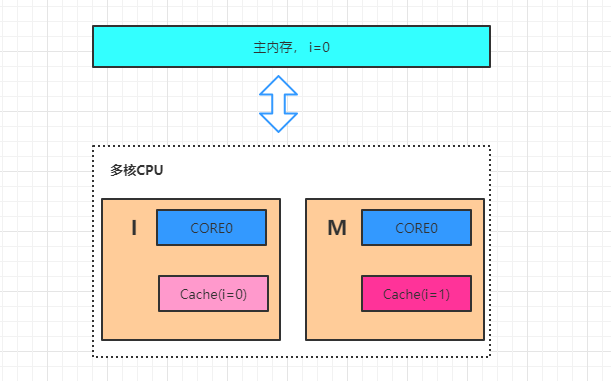
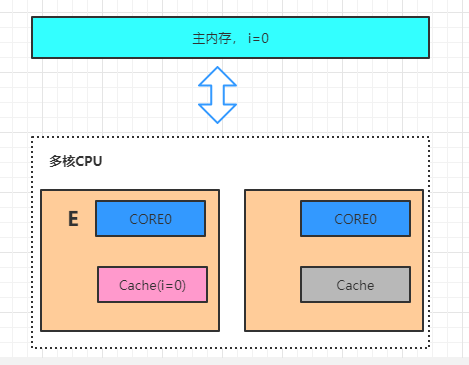
四、重排序原因
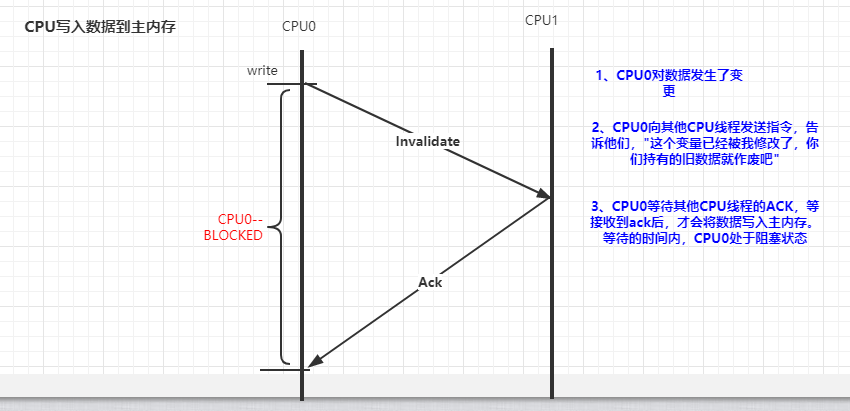
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其

这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。
转载:https://www.cnblogs.com/ningJJ/p/11479145.html
CPU指令重排序与MESI缓存一致性的更多相关文章
- cpu指令重排序的原理
目录: 1.重排序场景 2.追根溯源 3.缓存一致性协议 4.重排序原因 一.重排序场景 class ResortDemo { int a = 0; boolean flag = false; pub ...
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- Java的多线程机制系列:不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- Java的多线程机制系列:(四)不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- 指令重排序及Happens-before法则随笔
指令重排序 对主存的一次访问一般花费硬件的数百次时钟周期.处理器通过缓存(caching)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操作的顺序.也就是说,程序的读写操作不一定会按 ...
- JVM并发机制的探讨——内存模型、内存可见性和指令重排序
并发本来就是个有意思的问题,尤其是现在又流行这么一句话:“高帅富加机器,穷矮搓搞优化”. 从这句话可以看到,无论是高帅富还是穷矮搓都需要深入理解并发编程,高帅富加多了机器,需要协调多台机器或者多个CP ...
- 深入浅出 Java Concurrency (4): 原子操作 part 3 指令重排序与happens-before法则
转: http://www.blogjava.net/xylz/archive/2010/07/03/325168.html 在这个小结里面重点讨论原子操作的原理和设计思想. 由于在下一个章节中会谈到 ...
- J.U.C JMM. pipeline.指令重排序,happen-before
pipeline: 现在的CPU一般采用流水线方式来执行指令.一个指令执行周期被分成:取值,译码,执行,访存,写会,更新PC若干阶段.然后,多条指令可以同时存在于流水线中,同时被执行,来提高系统的吞吐 ...
- 不得不提的volatile及指令重排序(happen-before)
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
随机推荐
- jQuery中的闭包和js中的闭包总结
关于闭包的知识总结下: 一.闭包 1.定义 闭包的关键是作用域,概念是:能有读取其他函数内部的函数 使用的场景有很多,最常见的是函数封装的时候,再就是在使用定时器的时候,会经常用到; //闭包:有参数 ...
- 请简述一下 Ajax 的原理及实现步骤
简述 AJAX:AJAX即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术.通过在后台与服务器进行 ...
- C语言:结构体中(.)和(->)的区别
https://blog.csdn.net/faihung/article/details/79190039 这虽然是个小问题,但有时候很容易让人迷惑,因为有的时候用混淆了,程序编译不通过. 下面说说 ...
- Vue知识整理11:列表渲染(v-for来实现)
简单的v-for结构显示迭代数据 通过value别名 显示下面各个属性值 通过index 和key获取同类数组索引,或者不同属性的key属性名
- Ubuntu vimrc 和 bashrc 配置
先上效果图,把vimrc 和bashrc 备份一下.. vimrc: map <F9> :call SaveInputData()<CR> func! SaveInputDat ...
- Java面试题集(86-115)
Java程序员面试题集(86-115) 摘要:下面的内容包括Struts 2和Hibernate的常见面试题,虽然Struts 2在2013年6月曝出高危漏洞后已经显得江河日下,而Spring MVC ...
- elasticsearch7.0安装及配置优化
简单讲ES开箱即用,不用任何配置也能玩转搜索引擎:以下内容是根据易企秀线上实际使用场景进行的安装和配置,支持冷热数据分离 1.安装 Linux 环境下载安装包 curl -L -O https://a ...
- pyspark的安装配置
1.搭建基本spark+Hadoop的本地环境 https://blog.csdn.net/u011513853/article/details/52865076?tdsourcetag=s_pcqq ...
- base64 换表 解密脚本
做逆向经常遇到换表的base64 有了py脚本 一切都好说: import base64 import string str1 = "x2dtJEOmyjacxDemx2eczT5cVS9f ...
- 【查阅】mysql配置文件/参数文件重要参数笔录(my.cnf)
持续更新,积累自己对参数的理解 [1]my.cnf参数 [client]port = 3306socket = /mysql/data/3306/mysql.sockdefault-character ...