使用influxdb以及Grafana监控vCenter的操作步骤
1. 下载安装介质
- 计划telegraf和influxdb 使用rpm包进行安装。Grafana使用docker容器方式安装
下载路径为:
https://repos.influxdata.com/rhel/7Server/x86_64/stable/
其实可以根据仓库自己查找就可以了。
拉取镜像为:
docker pull grafana/grafana
注意2021.8时的版本信息为:
influxdb-1.8.9.x86_64.rpm
telegraf-1.19.2-1.x86_64.rpm
grafana 8.1的版本
注意 influxdb2的版本变化比较大 资料比较少一些。
2. 安装介质
yum localinstall *.rpm
需要注意的是,设置为开机启动相关。
3. influxdb参数文件设置
- influxdb的设置
- 注意安装完之后需要启动数据库
- systemctl enable influxdb && systemctl restart influxdb 启动数据库即可。
注意可以通过influx 命令登录进数据库,一开始设置完没有密码可以直接登录,但是用有密码之后必须使用命令进行登录了。
influxdb 是一个时序数据库可以通过telegraf 等工具push监控数据进来,然后交由grafana进行图形化展示。
# 显示用户
SHOW USERS
# 创建用户
CREATE USER "username" WITH PASSWORD 'password'
# 赋予用户管理员权限
GRANT ALL PRIVILEGES TO username
# 创建管理员权限的用户
CREATE USER <username> WITH PASSWORD '<password>' WITH ALL PRIVILEGES
# 修改用户密码
SET PASSWORD FOR username = 'password'
# 撤消权限
REVOKE ALL ON mydb FROM username
# 查看权限
SHOW GRANTS FOR username
# 删除用户
DROP USER "username"
- 注意设置好权限之后就可以进行telegraf的处理了。
4. telegraf的配置文件
- systemctl enable influxdb && systemctl restart influxdb 启动数据库即可。
vim /etc/telegraf/vm187.conf
添加内容为:
[global_tags]
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
hostname = ""
omit_hostname = false
[[outputs.influxdb]]
#这里需要修改。
urls = ["http://127.0.0.1:8086"]
database = "vm187"
timeout = "0s"
username = "influxdb"
password = "上一步创建的密码"
[[inputs.vsphere]]
# 这里需要设置为密码
vcenters = [ "https://yourvmcenterip/sdk" ]
username = "administrator@vsphere.local"
password = "yourvcenterpassword"
vm_metric_include = [
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.run.summation",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.wait.summation",
"mem.active.average",
"mem.granted.average",
"mem.latency.average",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.usage.average",
"power.power.average",
"virtualDisk.numberReadAveraged.average",
"virtualDisk.numberWriteAveraged.average",
"virtualDisk.read.average",
"virtualDisk.readOIO.latest",
"virtualDisk.throughput.usage.average",
"virtualDisk.totalReadLatency.average",
"virtualDisk.totalWriteLatency.average",
"virtualDisk.write.average",
"virtualDisk.writeOIO.latest",
"sys.uptime.latest",
]
host_metric_include = [
"cpu.coreUtilization.average",
"cpu.costop.summation",
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.swapwait.summation",
"cpu.usage.average",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.utilization.average",
"cpu.wait.summation",
"disk.deviceReadLatency.average",
"disk.deviceWriteLatency.average",
"disk.kernelReadLatency.average",
"disk.kernelWriteLatency.average",
"disk.numberReadAveraged.average",
"disk.numberWriteAveraged.average",
"disk.read.average",
"disk.totalReadLatency.average",
"disk.totalWriteLatency.average",
"disk.write.average",
"mem.active.average",
"mem.latency.average",
"mem.state.latest",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.totalCapacity.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.errorsRx.summation",
"net.errorsTx.summation",
"net.usage.average",
"power.power.average",
"storageAdapter.numberReadAveraged.average",
"storageAdapter.numberWriteAveraged.average",
"storageAdapter.read.average",
"storageAdapter.write.average",
"sys.uptime.latest",
]
cluster_metric_include = []
datastore_metric_include = []
datacenter_metric_include = []
datacenter_metric_exclude = [ "*" ]
insecure_skip_verify = true
- 设置完之后需要启动telegraf
nohup telegraf -config /etc/telegraf/vm187.conf &
后台运行即可。
- 注意我设置的是最小化的参数。
5. docker 运行grafana
docker run -d -p 3000:3000 --name=grafana -v /opt/grafana-storage:/var/lib/grafana grafana/grafana
注意需要进行持久化避免重启之后数据丢失
6.添加influxdb 的数据源
注意需要输入创建的用户和密码
端口选择为8086
7. 添加grafana的json文件或者是执行导入即可。
- 先展示一下效果
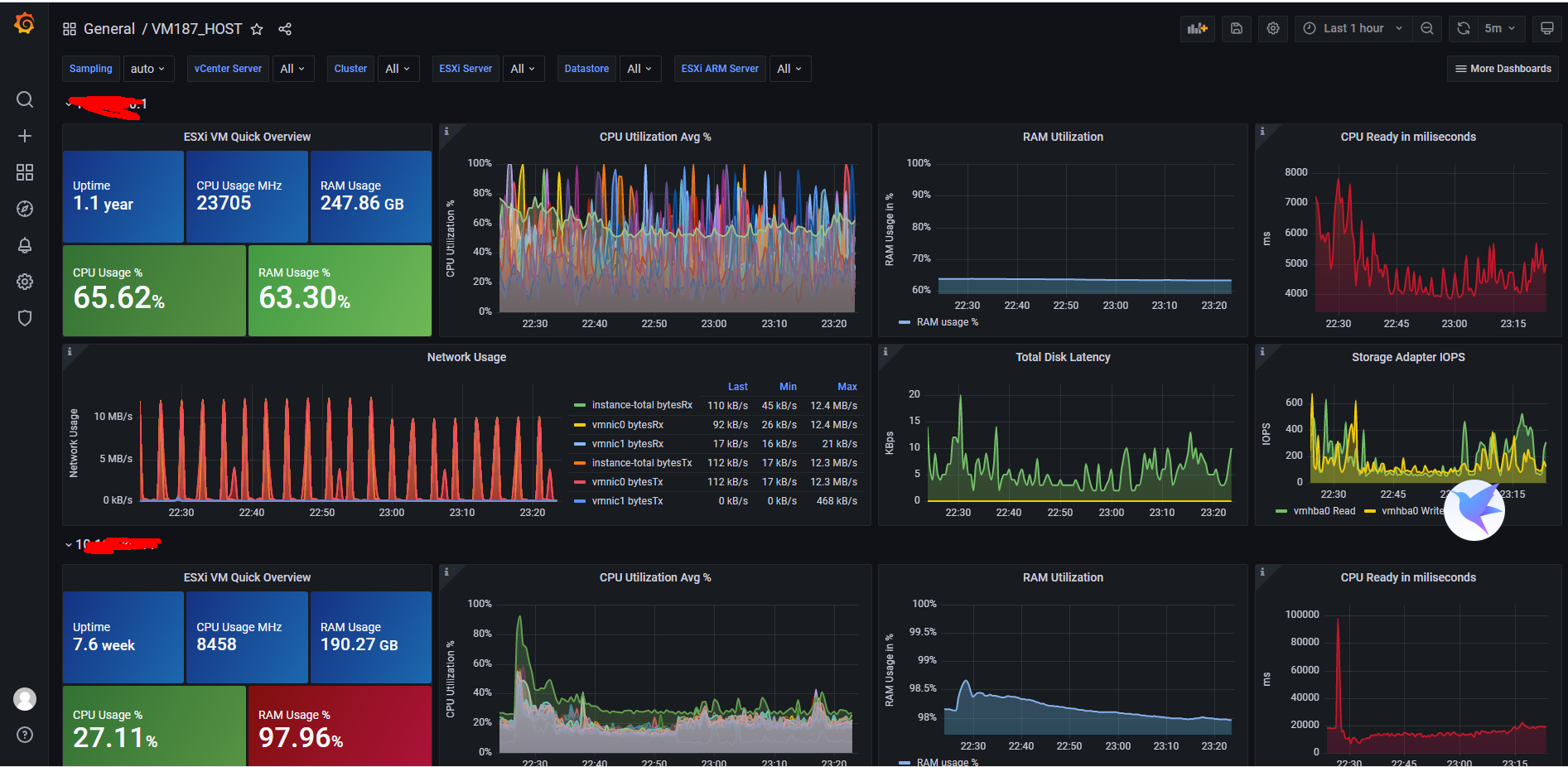
- 使用的配置文件为:
https://grafana.com/grafana/dashboards/6171
使用influxdb以及Grafana监控vCenter的操作步骤的更多相关文章
- 【容器云】十分钟快速构建 Influxdb+cadvisor+grafana 监控
本文作者:七牛云布道师@陈爱珍,DBAPlus社群联合发起人.前新炬技术专家.多年企业级系统的应用运维及分布式系统实战经验.现专注于容器.微服务及DevOps落地的研究与实践. 安装过程 三个都直接下 ...
- [工具开发] 分享两个基于Heapster 和 Influxdb 的 Grafana 监控仪表盘模板
Info Collector: Heapster - /heapster- --metric-resolution=30s- --sink=influxdb:http://influxdb.defau ...
- 使用 Grafana、collectd 和 InfluxDB 打造现代监控系统
想打造 New Relic 那样漂亮的实时监控系统我们只需要 InfluxDB/collectd/Grafana 这三个工具,这三个工具的关系是这样的: 采集数据(collectd)-> 存储数 ...
- Kubernetes监控:部署Heapster、InfluxDB和Grafana
本节内容: Kubernetes 监控方案 Heapster.InfluxDB和Grafana介绍 安装配置Heapster.InfluxDB和Grafana 访问 grafana 访问 influx ...
- 全网最详细!Centos7.X 搭建Grafana+Jmeter+Influxdb 性能实时监控平台
背景 日常工作中,经常会用到Jmeter去压测,毕竟LR还要钱(@¥&*...),而最常用的接口压力测试,我们都是通过聚合报告去查看压测结果的,然鹅聚合报告的真的是丑到家了,作为程序猿这当然不 ...
- Centos8.X 搭建Grafana+Jmeter+Influxdb 性能实时监控平台
前言 本篇文章引用了小菠萝测试笔记,大部分内容非原创,基于自身实操过程中,完善了部分. 本篇随笔是在Linux上搭建的,后面会补充在docker以及k8s上如何部署安装 工具介绍 工具 介绍 Jmet ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时监控Android系统和应用进程
基于Python结合InfluxDB及Grafana图表实时监控Android系统和应用进程 By: 授客 QQ:1033553122 1. 测试环境 2. 实现功能 3. 使用前提 4. ...
- 使用Telegraf + Influxdb + Grafana 监控SQLserver服务器的运行状况
使用Telegraf + Influxdb + Grafana 监控SQLserver服务器的运行状况 前言 本文在Debian9下采用Docker的方式安装Telegraf + Influxdb + ...
- 【监控】使用 Grafana、collectd 和 InfluxDB 打造现代监控系统
参考资料:Grafana 是 Graphite 和 InfluxDB 仪表盘和图形编辑器:http://www.oschina.net/p/grafana 使用 Grafana.collectd 和 ...
- 搭建grafana+telegraf+influxdb服务器性能监控平台
最近在学习性能测试,了解到一套系统资源使用率低的监控环境,也就是grafana+telegraf+influxdb. InfluxDB是一款优秀的时间序列数据库,适合存储设备性能.日志.物联网传感器等 ...
随机推荐
- 基于DAYU的实时作业开发,分分钟搭建企业个性化推荐平台
摘要:搭建这个平台最费时耗力的事莫过于对批.流作业的编排,作业组织管理以及任务调度了.但是这一切,用DAYU的数据开发功能几个任务可通通搞定. 大多数电商类企业都会搭建自己的个性化推荐系统,利用自己拥 ...
- 云图说|AppCube零代码,开启无码新生活
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要: 应用魔方 App ...
- 鸿蒙轻内核M核源码分析:中断Hwi
摘要:本文带领大家一起剖析了鸿蒙轻内核的中断模块的源代码,掌握中断相关的概念,中断初始化操作,中断创建.删除,开关中断操作等. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列五 中断Hwi&g ...
- Log4Shell 漏洞披露已近一年,它对我们还有影响吗?
在 Log4Shell 高危漏洞事件披露几乎整整一年之后,新的数据显示,对全球大多数组织来说,补救工作是一个漫长.缓慢.痛苦的过程. 根据漏洞扫描领先者 Tenable 公司的遥测数据来看,截至今年1 ...
- 备份批处理文件 bat 生成 date 取年时,只取到周
备份数据库文件时,发现MySQL备份生成的文件名为 [vipsoft_周三],发现是系统的日期格式问题.需调整日期格式,生成 [vipsoft_20220601.sql] mysqldump -uro ...
- 电子签章Java后端与前端交互签名位置计算
电子签章过程中存在着在网页上对签署文件进行预览.指定签署位置.文件签署等操作,由于图片在浏览器上的兼容性和友好性优于PDF文件,所以一般在网页上进行电子签章时,会先将PDF文件转换成图片,展示给用户. ...
- Beyond Compare常用快捷键
[会话]菜单的功能与快捷键 [文件]菜单的功能与快捷键 [编辑]菜单的功能与快捷键 [搜索]菜单的功能与快捷键
- SpringBoot 项目实战 | 瑞吉外卖 Day01
一.软件开发整体介绍 1.软件开发流程 2.角色分工 项目经理:对整个项目负责,任务分配.把控进度 产品经理:进行需求调研,输出需求调研文档.产品原型等 UI设计师:根据产品原型输出界面效果图 架构师 ...
- 深度 | 新兴软件研发范式崛起,云计算全面走向 Serverless 化
11月3日,2022 杭州 · 云栖大会上,阿里云智能总裁张建锋表示,以云为核心的新型计算体系正在形成,软件研发范式正在发生新的变革,Serverless 是其中最重要的趋势之一,阿里云将坚定推进核心 ...
- 阿里云 Serverless 异步任务处理系统在数据分析领域的应用
异步任务处理系统中的数据分析 数据处理.机器学习训练.数据统计分析是最为常见的一类离线任务.这类任务往往都是经过了一系列的预处理后,由上游统一发送到任务平台进行批量训练及分析.在处理语言方面,Pyth ...