聊聊分布式 SQL 数据库Doris(九)
优化器的作用是优化查询语句的执行效率,它通过评估不同的执行计划并选择最优的执行计划来实现这一目标。
CBO: 一种基于成本的优化器,它通过评估不同查询执行计划的成本来选择最优的执行计划。CBO会根据数据库系统定义的统计信息以及其他因素,对不同的执行计划进行评估,并选择成本最低的执行计划。CBO的目标是找到一个最优的执行计划,使得查询的执行成本最低。
RBO: 一种基于规则的优化器,它通过应用一系列的优化规则来选择最优的执行计划。RBO会根据预定义的规则对查询进行优化,这些规则基于数据库系统的特定逻辑和语义。RBO的优点是实现简单,适用于特定的查询模式和数据分布。然而,RBO可能无法找到最优的执行计划,特别是对于复杂的查询和大规模的数据集。
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP查询引擎)和Apache ORCFile (存储格式,编码和压缩) 的技术。 Doris的查询优化器则是基于Impala改造实现的。Doris官方提供的 Nereids优化器 文档。
优化器组件
查询优化器由多个部分组成,分别是: 词法语法解析、语义解析、query改写、生成执行计划。最后这步根据算法实现与业务场景的不同会有些许差异。
词法语法解析
这个步骤,其实是做两件事情,首先是解析SQL文本,提取关键字出来,比如(select、from等); 然后分析SQL文本是否满足SQL语法,最终生成一个AST树。其结构如下:
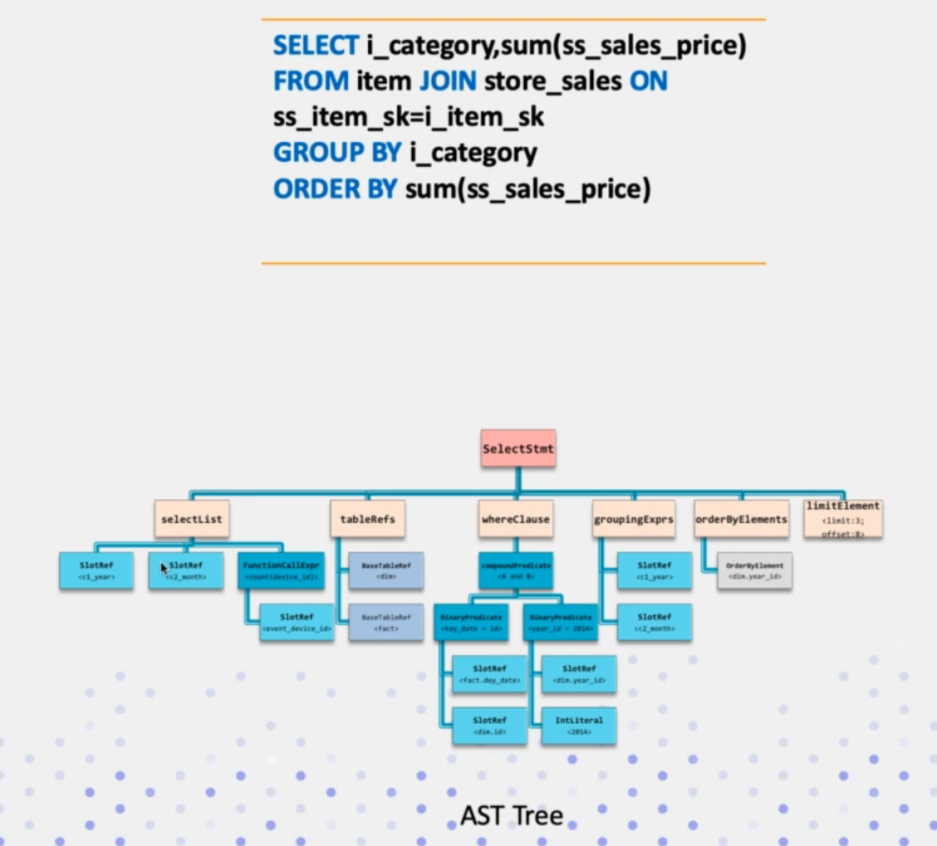
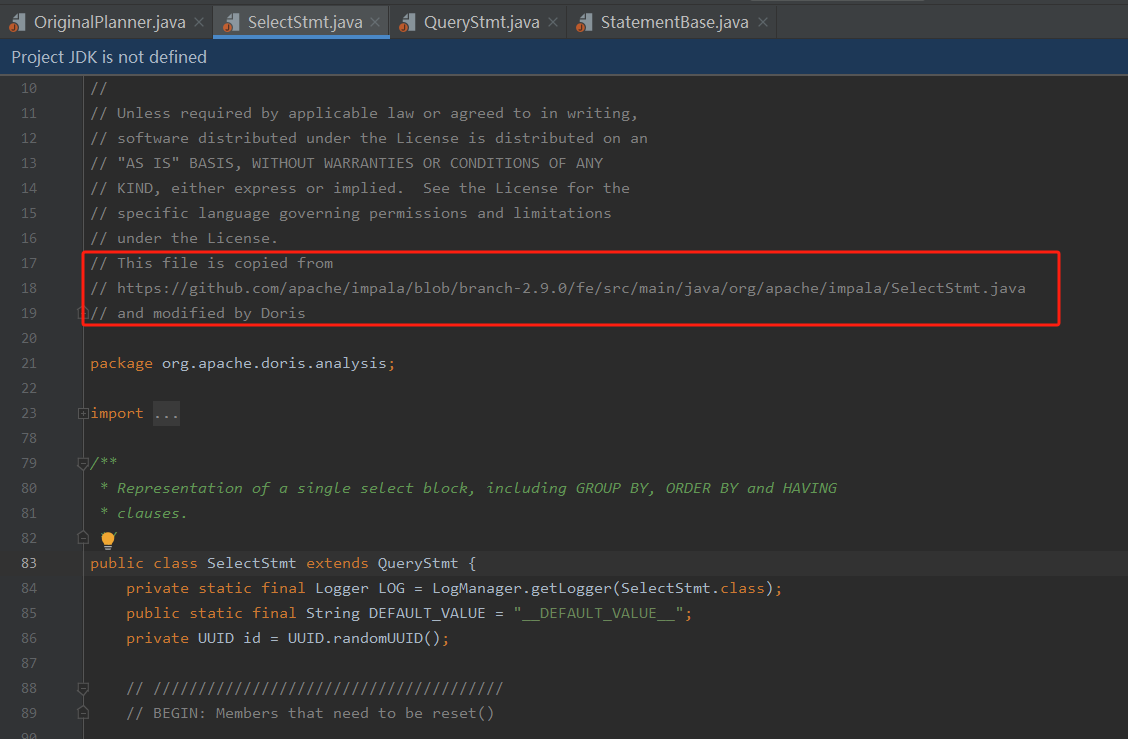
对于不同类型的SQL,其语法树的根节点类型也是不一样的。一般是InsertStmt、UpdateStmt、DeleteStmt、SelectStmt等。而这些概念其实是impala中的,Doris的SQL查询引擎是参考自impala。在其源码中有这么一段注释:
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)sql查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。其相关信息及文档可参考: impala中文手册
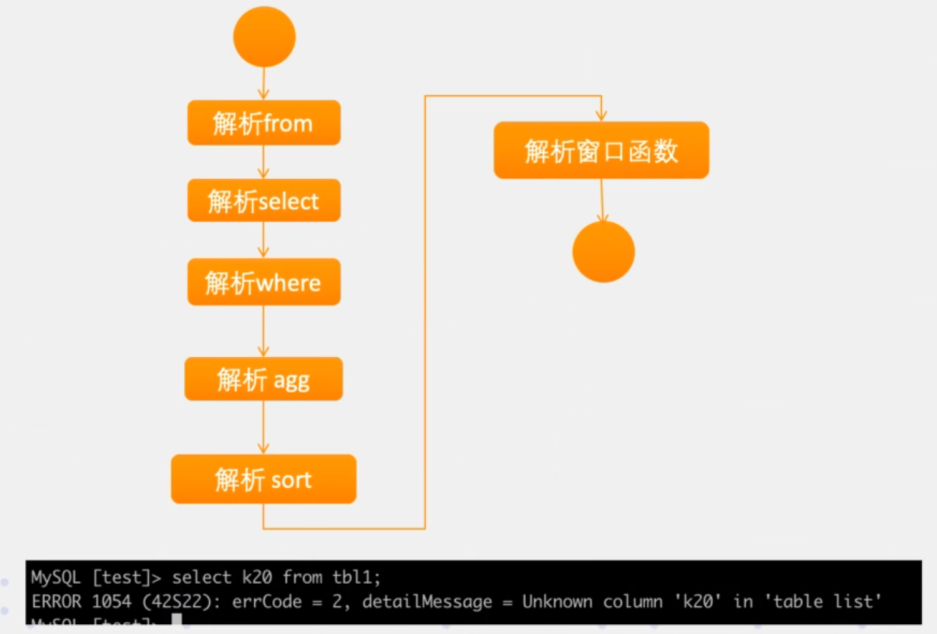
语义解析
根据AST树与元数据中的表、列信息等做一个语义校验,比如,表、字段是否在元数据中存在。其步骤一般如下:
query改写
对原始的sql文本做一定程度的改写使得SQL更简单,执行效率更高;一般是条件表达式改写、子查询改写等。
在Doris中,有一个接口 ExprRewriteRule 负责表达式的改写规则,基于该接口与各种不同的规则有不同的实现,在 Analyzer类的内部类 GlobalState 构造函数中,注册了诸多的规则到rules集合中,而该list会被传递到ExprRewriter类中被应用。
StmtRewriter 类处理子查询改写逻辑,其中的方法会处理各种场景下的子查询改写,比如rewriteSelectStatement方法.
这一步骤的处理是基于词法语法解析后生成的AST树进行的。
public class GlobalState(Env env, ConnectContext context) {
this.env = env;
this.context = context;
List<ExprRewriteRule> rules = Lists.newArrayList();
// BetweenPredicates must be rewritten to be executable. Other non-essential
// expr rewrites can be disabled via a query option. When rewrites are enabled
// BetweenPredicates should be rewritten first to help trigger other rules.
rules.add(BetweenToCompoundRule.INSTANCE);
// Binary predicates must be rewritten to a canonical form for both predicate
// pushdown and Parquet row group pruning based on min/max statistics.
rules.add(NormalizeBinaryPredicatesRule.INSTANCE);
// Put it after NormalizeBinaryPredicatesRule, make sure slotRef is on the left and Literal is on the right.
rules.add(RewriteBinaryPredicatesRule.INSTANCE);
rules.add(RewriteImplicitCastRule.INSTANCE);
rules.add(RoundLiteralInBinaryPredicatesRule.INSTANCE);
rules.add(FoldConstantsRule.INSTANCE);
rules.add(EraseRedundantCastExpr.INSTANCE);
rules.add(RewriteFromUnixTimeRule.INSTANCE);
rules.add(CompoundPredicateWriteRule.INSTANCE);
rules.add(RewriteDateLiteralRule.INSTANCE);
rules.add(RewriteEncryptKeyRule.INSTANCE);
rules.add(RewriteInPredicateRule.INSTANCE);
rules.add(RewriteAliasFunctionRule.INSTANCE);
rules.add(RewriteIsNullIsNotNullRule.INSTANCE);
rules.add(MatchPredicateRule.INSTANCE);
rules.add(EliminateUnnecessaryFunctions.INSTANCE);
List<ExprRewriteRule> onceRules = Lists.newArrayList();
onceRules.add(ExtractCommonFactorsRule.INSTANCE);
onceRules.add(InferFiltersRule.INSTANCE);
exprRewriter = new ExprRewriter(rules, onceRules);
// init mv rewriter
List<ExprRewriteRule> mvRewriteRules = Lists.newArrayList();
mvRewriteRules.add(new ExprToSlotRefRule());
mvRewriteRules.add(ToBitmapToSlotRefRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmapOrHLLRule.INSTANCE);
mvRewriteRules.add(CountDistinctToBitmap.INSTANCE);
mvRewriteRules.add(NDVToHll.INSTANCE);
mvRewriteRules.add(HLLHashToSlotRefRule.INSTANCE);
mvExprRewriter = new ExprRewriter(mvRewriteRules);
// context maybe null. eg, for StreamLoadPlanner.
// and autoBroadcastJoinThreshold is only used for Query's DistributedPlanner.
// so it is ok to not set autoBroadcastJoinThreshold if context is null
if (context != null) {
// compute max exec mem could be used for broadcast join
long perNodeMemLimit = context.getSessionVariable().getMaxExecMemByte();
double autoBroadcastJoinThresholdPercentage = context.getSessionVariable().autoBroadcastJoinThreshold;
if (autoBroadcastJoinThresholdPercentage > 1) {
autoBroadcastJoinThresholdPercentage = 1.0;
} else if (autoBroadcastJoinThresholdPercentage <= 0) {
autoBroadcastJoinThresholdPercentage = -1.0;
}
autoBroadcastJoinThreshold = (long) (perNodeMemLimit * autoBroadcastJoinThresholdPercentage);
} else {
// autoBroadcastJoinThreshold is a "final" field, must set an initial value for it
autoBroadcastJoinThreshold = 0;
}
}
单机执行计划
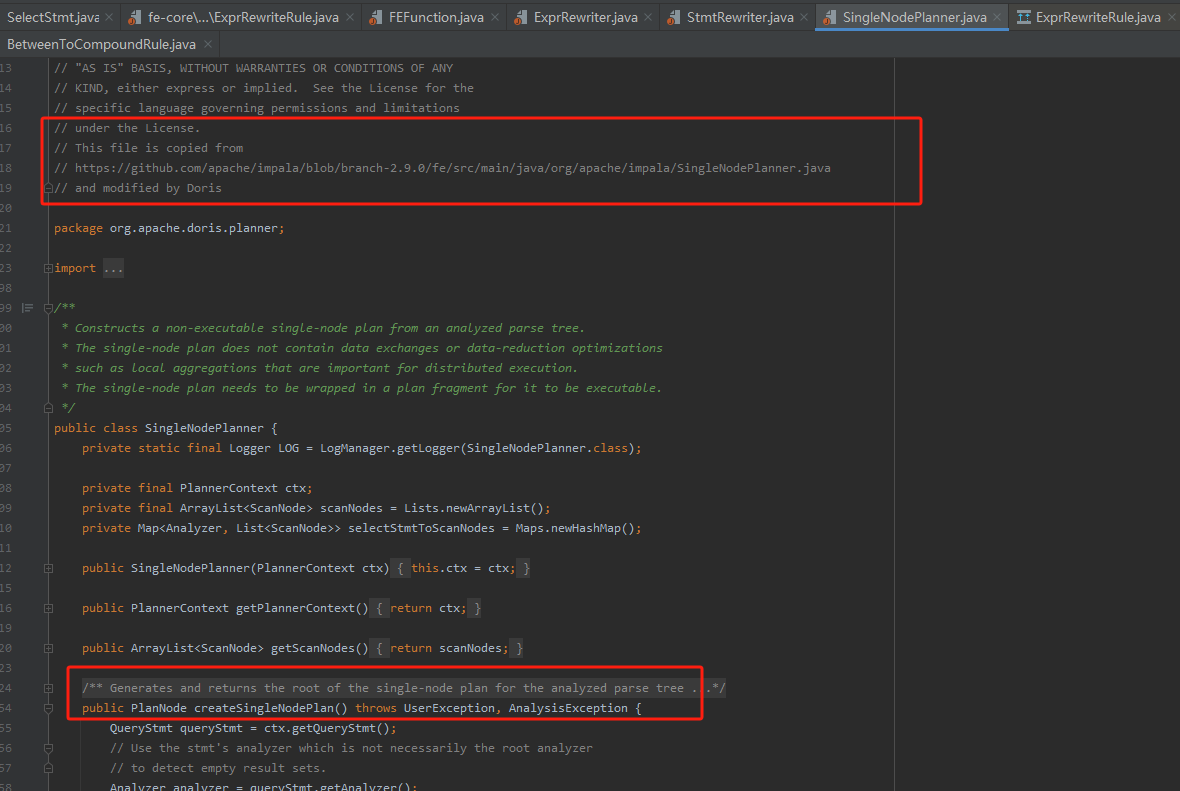
这一过程会生成PlanNodeTree,一般用于处理Join Reorder场景下的join调优与谓词下推等下推优化。
SingleNodePlanner类用于生成单击执行计划,该类其实也是基于impala框架改写适用于Doris的。在这个类中,除了谓词下推与join reorder外,还有类似列裁剪之类的优化,都在这个类中有处理。
分布式执行计划
DistributedPlanner类负责分布式执行计划的优化,其中会处理Join场景下的分布式执行,选择最优的Join执行路径;其次就是Agg聚合函数的分布式执行逻辑,Agg会分两步执行,先会在local本地scan,然后再Agg Node上在做一次scan聚合;当然还有一些算子需要做分布式逻辑执行优化. 都可以在这个类中找到。当然这个类也是基于impala框架改写的。
如下是AggNode的分布式执行计划优化:
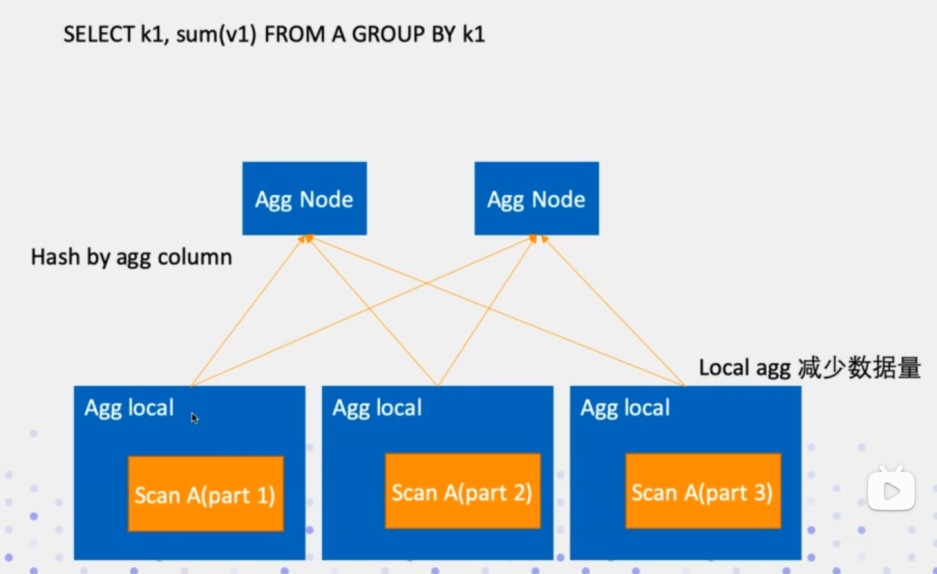
总结
Doris的很多设计,其实都是有据可依,参考借鉴已有的框架/论文,再依据实际的业务场景做改写;这也正是我们要学习了解的东西,通过一个点,然后铺开去了解学习相关的其他点,慢慢的串联起来形成面。查询优化器结合如下博客再加上自己去阅读一下代码,对整个脉络及机制就算是掌握了。
聊聊分布式 SQL 数据库Doris(五) 这是之前写的对查询优化器相关的一些知识普及.
查询优化器详解 Doris团队针对查询优化器的视频讲解.
Doris SQL 原理解析 小米工程师写的,更深入的剖析.
聊聊分布式 SQL 数据库Doris(九)的更多相关文章
- 分布式SQL数据库中部分索引的好处
在优锐课的java学习分享中,探讨了分布式SQL数据库中部分索引的优势,并探讨了性能测试,结果等. 如果使用局部索引而不是常规索引,则在可为空的列上(其中只有一小部分行的该列不具有空值),然后可以大大 ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- CockroachDB学习笔记——[译]The New Stack:遇见CockroachDB,一个弹性SQL数据库
原文链接:https://www.cockroachlabs.com/blog/the-new-stack-meet-cockroachdb-the-resilient-sql-database/ 原 ...
- 【原创】分布式之数据库和缓存双写一致性方案解析(三) 前端面试送命题(二)-callback,promise,generator,async-await JS的进阶技巧 前端面试送命题(一)-JS三座大山 Nodejs的运行原理-科普篇 优化设计提高sql类数据库的性能 简单理解token机制
[原创]分布式之数据库和缓存双写一致性方案解析(三) 正文 博主本来觉得,<分布式之数据库和缓存双写一致性方案解析>,一文已经十分清晰.然而这一两天,有人在微信上私聊我,觉得应该要采用 ...
- Spring Cloud Config(一):聊聊分布式配置中心 Spring Cloud Config
目录 Spring Cloud Config(一):聊聊分布式配置中心 Spring Cloud Config Spring Cloud Config(二):基于Git搭建配置中心 Spring Cl ...
- Google的分布式关系型数据库F1和Spanner
F1是Google开发的分布式关系型数据库,主要服务于Google的广告系统.Google的广告系统以前使用MySQL,广告系统的用户经常需要使用复杂的query和join操作,这就需要设计shard ...
- 分布式MySQL数据库TDSQL架构分析
摘要:腾讯计费平台部为了解决基于内存的NoSQL解决方式HOLD平台在应对多种业务接入时的不足.结合团队在MySQL领域多年应用和优化经验,终于在MySQL存储引擎基础上,打造一套分布式SQL系统TD ...
- SQL数据库的基础操作
一,认识SQL数据库 美国Microsoft公司推出的一种关系型数据库系统.SQLServer是一个可扩展的.高性能的.为分布式客户机/服务器计算所设计的数据库管理系统,实现了与WindowsNT的有 ...
- DRDS分布式SQL引擎—执行计划介绍
摘要: 本文着重介绍 DRDS 执行计划中各个操作符的含义,以便用户通过查询计划了解 SQL 执行流程,从而有针对性的调优 SQL. DRDS分布式SQL引擎 — 执行计划介绍 前言 数据库系统中,执 ...
- ASP.NET动态网站制作(15)-- SQL数据库(1)
前言:数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,用户可以对文件中的数据进行增.删.改.查.数据库有很多种类型,从简单的存储有各种数据的表格到能都进行海量数据存储的大型数据库 ...
随机推荐
- 图解算法,原理逐步揭开「GitHub 热点速览」
想必每个面过大厂的小伙伴都被考过算法,那么有没有更快了解算法的方式呢?这是一个老项目,hello-algo 用图解的方式让你了解运行原理.此外,SQL 闯关自学项目也是一个让你能好好掌握 SQL 技术 ...
- centos7升级内核到最新稳定版
前言 centos7默认的内核版本才3.10,诸如VXLAN.eBPF等特性无法体验,因此需要升级.目前(2022.02)Linux的内核版本已更新到5.16. 步骤 更新仓库 yum update ...
- 21.1 使用PEfile分析PE文件
PeFile模块是Python中一个强大的便携式第三方PE格式分析工具,用于解析和处理Windows可执行文件.该模块提供了一系列的API接口,使得用户可以通过Python脚本来读取和分析PE文件的结 ...
- Java日志系列:Log4j使用和原理分析
目录 一.简介 二.使用 三.日志级别 四.组件说明 Loggers Appenders Layouts 五.配置 加载初始化配置 配置文件加载 查看日志记录器的详细信息 六.Layout的格式 七. ...
- 【pytorch】目标检测:YOLO的基本原理与YOLO系列的网络结构
利用深度学习进行目标检测的算法可分为两类:two-stage和one-stage.two-stage类的算法,是基于Region Proposal的,它包括R-CNN,Fast R-CNN, Fast ...
- Nginx Ingress Contoller 通过 Envoy 代理和 Jaeger 进行分布式追踪(二)
1.概述 在<应用程序通过 Envoy 代理和 Jaeger 进行分布式追踪(一)>一文中,我们详细介绍了单个应用程序如何通过 Envoy 和 Jaeger 实现链路追踪的过程.然而,单独 ...
- Unity TextMeshPro 添加中文字体遇见的问题以及解决方案
前言 按标准官方教程为 Unity TextMeshPro 添加中文字体时出现了各种奇奇怪怪的问题,于是有了这篇随笔. 中文字体解决方案 以下步骤适用于 TextMeshPro 3.0.6. 字符数量 ...
- 使用Java Xpath 爬取某易云歌曲
本文使用Java xpath 爬取某易云歌曲,并下载至本地. 代码仅用于个人学习使用,欢迎各位大佬提出建议. 1.添加依赖 <dependency> <groupId>cn.w ...
- HarmonyOS扫码服务,应用服务一扫直达打造系统级流量新入口
二维码如今是移动应用流量入口以及功能实现的重要工具,也是各App的流量入口,是物.人.服务的连接器,通过扫码我们可以更便捷的生活,更高效的进行信息交互,包括信息的发布.信息的获取. 在日常扫码过程中, ...
- Excel中的数值四舍五入方法详解
在日常工作和数据处理中,我们经常需要对数值进行四舍五入操作.Excel作为一款强大的电子表格软件,提供了多种方法来实现数值的四舍五入.本文将介绍Excel中常用的四舍五入函数及其基本使用方法. ROU ...