SpringBoot 整合多数据源的事务问题
代码
先贴代码:
核心就是:Spring给我们提供的一个类 AbstractRoutingDataSource,然后我们再写一个切面来切换数据源,肯定要有一个地方存储key还要保证上下文都可用,所以我们使用 ThreadLocal 来存储数据源的key
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
注解:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DS {
String value() default DataSourceCons.DS1;
}
常量类:
public interface DataSourceCons {
String DS1 ="ds1";
String DS2 ="ds2";
}
上下文存储对象:
@Slf4j
public class DynamicDataSourceContextHolder {
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
public static void setContextHolder(String dsName) {
log.info("切换到 ===> {} 数据源", dsName);
CONTEXT_HOLDER.set(dsName);
}
public static String get() {
return CONTEXT_HOLDER.get();
}
public static void clear() {
CONTEXT_HOLDER.remove();
}
}
切面:后续这个Order注解有大用
@Aspect
@Component
// @Order(-1)
public class DynamicDataSourceAspect {
@Pointcut("@annotation(com.lizhi.dds.anno.DS)")
public void point1() {
}
@Around("point1()")
public Object switchDS(ProceedingJoinPoint pjp) throws Throwable {
try {
DS ds = getDataSource(pjp);
if (ds != null){
DynamicDataSourceContextHolder.setContextHolder(ds.value());
}
return pjp.proceed();
} finally {
DynamicDataSourceContextHolder.clear();
}
}
private DS getDataSource(ProceedingJoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
DS methodAnno = signature.getMethod().getAnnotation(DS.class);
if (methodAnno != null) {
return methodAnno;
} else {
return pjp.getTarget().getClass().getAnnotation(DS.class);
}
}
}
存储数据源的类:我们这里就写一个map来存储数据源,大家也可以加其它的属性
@Data
@Configuration
@ConfigurationProperties(prefix = "spring.datasource.druid")
public class DruidProperties {
private Map<String, Map<String, String>> ds;
}
核心类:我们写一个类来继承这个核心类来自定义我们自己的东西
@Component
public class DynamicDataSource extends AbstractRoutingDataSource {
@Autowired
private DruidProperties druidProperties;
/**
* 初始化数据源
*
* @throws Exception
*/
@PostConstruct
public void init() throws Exception {
Map<String, Map<String, String>> ds = druidProperties.getDs();
Map<Object, Object> dataSources = new HashMap<>();
for (Map.Entry<String, Map<String, String>> entry : ds.entrySet()) {
DataSource dataSource = DruidDataSourceFactory.createDataSource(entry.getValue());
dataSources.put(entry.getKey(), dataSource);
}
setTargetDataSources(dataSources);
setDefaultTargetDataSource(dataSources.get(DataSourceCons.DS1));
afterPropertiesSet();
}
/**
* 拿数据源的时候会调用此方法来找key
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceContextHolder.get();
}
}
直接来看一下这个类的源码:就知道动态数据源是怎么来的了
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {
// 我们所有的数据源都会存储在这里面
@Nullable
private Map<Object, Object> targetDataSources;
// 默认用哪个数据源
@Nullable
private Object defaultTargetDataSource;
private boolean lenientFallback = true;
private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();
// 解析过后的所有数据源
@Nullable
private Map<Object, DataSource> resolvedDataSources;
// 解析过后的默认数据源
@Nullable
private DataSource resolvedDefaultDataSource;
/**
* Specify the map of target DataSources, with the lookup key as key.
* The mapped value can either be a corresponding {@link javax.sql.DataSource}
* instance or a data source name String (to be resolved via a
* {@link #setDataSourceLookup DataSourceLookup}).
* <p>The key can be of arbitrary type; this class implements the
* generic lookup process only. The concrete key representation will
* be handled by {@link #resolveSpecifiedLookupKey(Object)} and
* {@link #determineCurrentLookupKey()}.
*/
public void setTargetDataSources(Map<Object, Object> targetDataSources) {
this.targetDataSources = targetDataSources;
}
/**
* Specify the default target DataSource, if any.
* <p>The mapped value can either be a corresponding {@link javax.sql.DataSource}
* instance or a data source name String (to be resolved via a
* {@link #setDataSourceLookup DataSourceLookup}).
* <p>This DataSource will be used as target if none of the keyed
* {@link #setTargetDataSources targetDataSources} match the
* {@link #determineCurrentLookupKey()} current lookup key.
*/
public void setDefaultTargetDataSource(Object defaultTargetDataSource) {
this.defaultTargetDataSource = defaultTargetDataSource;
}
@Override
public void afterPropertiesSet() {
if (this.targetDataSources == null) {
throw new IllegalArgumentException("Property 'targetDataSources' is required");
}
this.resolvedDataSources = CollectionUtils.newHashMap(this.targetDataSources.size());
this.targetDataSources.forEach((key, value) -> {
Object lookupKey = resolveSpecifiedLookupKey(key);
DataSource dataSource = resolveSpecifiedDataSource(value);
this.resolvedDataSources.put(lookupKey, dataSource);
});
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource = resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
/**
* Resolve the given lookup key object, as specified in the
* {@link #setTargetDataSources targetDataSources} map, into
* the actual lookup key to be used for matching with the
* {@link #determineCurrentLookupKey() current lookup key}.
* <p>The default implementation simply returns the given key as-is.
* @param lookupKey the lookup key object as specified by the user
* @return the lookup key as needed for matching
*/
protected Object resolveSpecifiedLookupKey(Object lookupKey) {
return lookupKey;
}
/**
* Resolve the specified data source object into a DataSource instance.
* <p>The default implementation handles DataSource instances and data source
* names (to be resolved via a {@link #setDataSourceLookup DataSourceLookup}).
* @param dataSource the data source value object as specified in the
* {@link #setTargetDataSources targetDataSources} map
* @return the resolved DataSource (never {@code null})
* @throws IllegalArgumentException in case of an unsupported value type
*/
protected DataSource resolveSpecifiedDataSource(Object dataSource) throws IllegalArgumentException {
if (dataSource instanceof DataSource) {
return (DataSource) dataSource;
}
else if (dataSource instanceof String) {
return this.dataSourceLookup.getDataSource((String) dataSource);
}
else {
throw new IllegalArgumentException(
"Illegal data source value - only [javax.sql.DataSource] and String supported: " + dataSource);
}
}
/**
* Return the resolved default target DataSource, if any.
* @return the default DataSource, or {@code null} if none or not resolved yet
* @since 5.2.9
* @see #setDefaultTargetDataSource
*/
@Nullable
public DataSource getResolvedDefaultDataSource() {
return this.resolvedDefaultDataSource;
}
/**
* 决定要使用哪个数据源的方法(核心)
*/
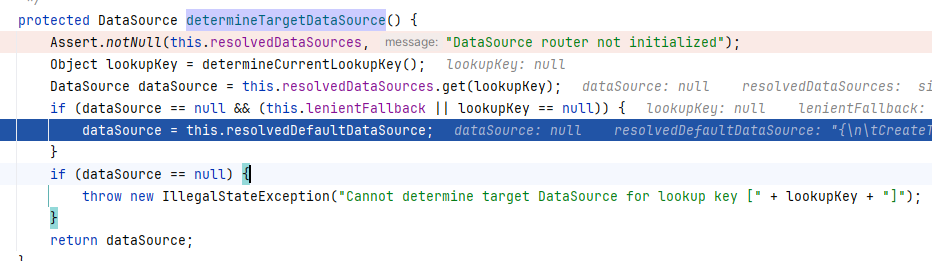
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
// 先拿到数据源的key
Object lookupKey = determineCurrentLookupKey();
// 从我们初始化好的map里根据key拿到一个数据源
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
// 如果没拿到就用默认的数据源
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
/**
* 找一下数据源的key(我们重写了此方法,所以拿到的就是我们上下文里存储的key)
*/
@Nullable
protected abstract Object determineCurrentLookupKey();
}
application.yml:
server:
port: 9999
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
ds:
ds1:
url: jdbc:mysql://localhost:3306/ry-vue?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
driverClassName: com.mysql.cj.jdbc.Driver
ds2:
url: jdbc:mysql://localhost:3306/atguigudb?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: root
driverClassName: com.mysql.cj.jdbc.Driver
在org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource#determineTargetDataSource 方法上打一个断点,然后发一个请求过去就能看到了,肯定一看就懂。
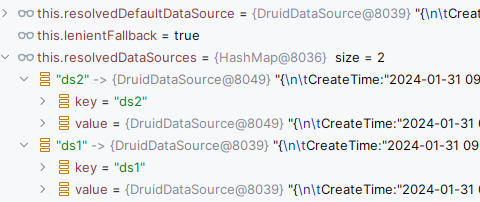
然后我们来说遇到的问题。
发现问题
问题1:两个库用同一个事务的问题
当我们使用如下代码时就会出现事务问题:
代码:
@Transactional
@Override
public List<SysUser> listAll() {
System.out.println("employeeService.listAll() = " + employeeService.listAll());
return sysUserMapper.selectList(null);
}
@DS(DataSourceCons.DS2)
@Override
public List<Employees> listAll() {
return employeeMapper.selectList(null);
}
问题截图:

我们发现的确出现了问题,发现第二张表的数据源使用的还是上一个的数据源,那我们就会想,是不是数据源切换没成功啊?别想了,我们看一下控制台就可以发现的确有打印(蓝色框里),说明走切面了。
那是哪的问题呢。
我们又会想到两个库使用同一个事务肯定会有问题。那我们就直接用Spring的事务的传播特性来解决不就好了,于是我们就直接上手改传播特性为 REQUIRES_NEW(默认的传播特性是 REQUIRED 也就是使用同一个事务,那我们就直接在第二个方法上加上事务注解并设置传播特性为 REQUIRES_NEW 即可,就是创建一个新事务,使用不同的事务)。我们改完之后发现还是没什么卵用。那我们就会疑惑了那是哪的问题呢?
解决方案:事务传播特性设置为 REQUIRES_NEW
问题2:优先级问题
这个问题的答案我就直接说了:事务的原理是代理,我们切换数据源的切面的原理也是代理,它俩的执行的前后顺序是有问题的。我们需要把切换数据源的切面让它在事务前执行即可。
解决方案:也就是需要加个Order注解来提升优先级。
源码分析
第一次Debug
先在第二个事务的方法设置传播特性为 REQUIRES_NEW,然后来分析。最后会分析 REQUIRED 为啥不行
我们直接在事务的方法上打一个断点:

那我们就会想了,都不知道从哪看,那该怎么办,没关系:不知道从那看很简单,我们直接看调用栈来找。

我们通过调用栈可以发现:
- 红框里是我们自己的方法,所以不用管
- 紫框里是代理,所以也不用管
- 蓝框里我们一看有 Transaction 关键字,那不就是事务相关的吗,好家伙,这不就找到了
那我们直接就在上面打个断点org.springframework.transaction.interceptor.TransactionInterceptor#invoke
发现它调用了 org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransaction 方法
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,
final InvocationCallback invocation) throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
// 如果transaction属性为null,则该方法为非事务性方法。
TransactionAttributeSource tas = getTransactionAttributeSource();
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
if (txAttr == null || !(ptm instanceof CallbackPreferringPlatformTransactionManager)) {
// 如果需要的话就创建一个事务(**核心**)
TransactionInfo txInfo = createTransactionIfNecessary(ptm, txAttr, joinpointIdentification);
Object retVal;
try {
// 执行目标方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
// 出现异常就处理异常
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
cleanupTransactionInfo(txInfo);
}
if (retVal != null && vavrPresent && VavrDelegate.isVavrTry(retVal)) {
// Set rollback-only in case of Vavr failure matching our rollback rules...
TransactionStatus status = txInfo.getTransactionStatus();
if (status != null && txAttr != null) {
retVal = VavrDelegate.evaluateTryFailure(retVal, txAttr, status);
}
}
// 提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
}
前面的都不需要看,直接看 createTransactionIfNecessary() 方法:TransactionAspectSupport类
protected TransactionInfo createTransactionIfNecessary(@Nullable PlatformTransactionManager tm,
@Nullable TransactionAttribute txAttr, final String joinpointIdentification) {
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 获取一个事务(核心)
status = tm.getTransaction(txAttr);
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Skipping transactional joinpoint [" + joinpointIdentification +
"] because no transaction manager has been configured");
}
}
}
return prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
}
来到真正的核心 getTransaction() 方法:AbstractPlatformTransactionManager类
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// 事务的定义信息
TransactionDefinition def = (definition != null ? definition : TransactionDefinition.withDefaults());
// 获取一个事务
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
// 已经有事务的处理
if (isExistingTransaction(transaction)) {
// Existing transaction found -> check propagation behavior to find out how to behave.
return handleExistingTransaction(def, transaction, debugEnabled);
}
// 没有事务的处理
if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
else if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRED ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW ||
def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
SuspendedResourcesHolder suspendedResources = suspend(null);
try {
// 开启一个事务
return startTransaction(def, transaction, debugEnabled, suspendedResources);
}
}
}
三个方法:doGetTransaction() 方法、handleExistingTransaction() 方法、startTransaction() 方法。我们一个一个来看。
第一个方法:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doGetTransaction
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(isNestedTransactionAllowed());
ConnectionHolder conHolder =
(ConnectionHolder) TransactionSynchronizationManager.getResource(obtainDataSource());
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
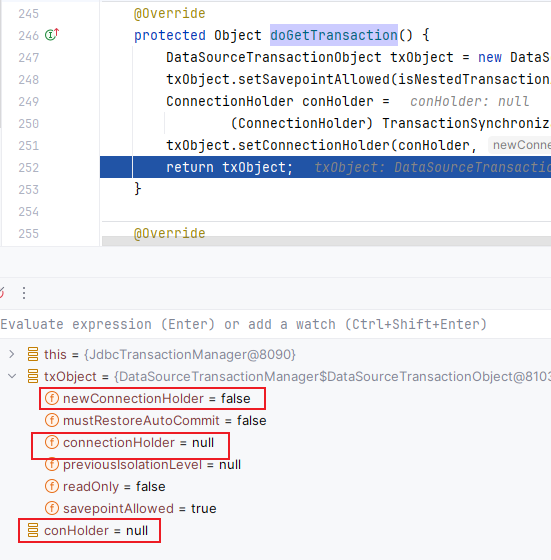
这是第一次这三个的值。
核心呢其实就是从缓存里获取了ConnectionHolder对象,连接缓存
来看一下这个方法:
org.springframework.transaction.support.TransactionSynchronizationManager#getResource
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
return doGetResource(actualKey);
}
/**
* Actually check the value of the resource that is bound for the given key.
*/
@Nullable
private static Object doGetResource(Object actualKey) {
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
Object value = map.get(actualKey);
// Transparently remove ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
map.remove(actualKey);
// Remove entire ThreadLocal if empty...
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
我们不是继承了AbstractRoutingDataSource这个类吗,这个key呢就是我们的这个类。

第一次肯定是拿不到连接缓存的,所以一路返回。又到了 getTransaction() 这个大方法
第一次肯定也是不存在事务的,所以也不会走我们的 第二个核心方法 handleExistingTransaction()
所以就来到了我们的第三个核心方法:
org.springframework.transaction.support.AbstractPlatformTransactionManager#startTransaction
private TransactionStatus startTransaction(TransactionDefinition definition, Object transaction,
boolean debugEnabled, @Nullable SuspendedResourcesHolder suspendedResources) {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
// 开始
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
直接看 doBegin() 方法
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
Connection con = null;
try {
// 如果事务没有连接缓存,那就给它一个
if (!txObject.hasConnectionHolder() ||
txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
// 根据当前数据源来获取一个连接 这个也是导致我们的问题所在处一
Connection newCon = obtainDataSource().getConnection();
if (logger.isDebugEnabled()) {
logger.debug("Acquired Connection [" + newCon + "] for JDBC transaction");
}
// 给当前事务设置一个连接缓存
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
// 设置一堆事务的特性:隔离级别啊、自动提交啊什么的
txObject.getConnectionHolder().setSynchronizedWithTransaction(true);
con = txObject.getConnectionHolder().getConnection();
Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
txObject.setPreviousIsolationLevel(previousIsolationLevel);
txObject.setReadOnly(definition.isReadOnly());
// Switch to manual commit if necessary. This is very expensive in some JDBC drivers,
// so we don't want to do it unnecessarily (for example if we've explicitly
// configured the connection pool to set it already).
if (con.getAutoCommit()) {
txObject.setMustRestoreAutoCommit(true);
if (logger.isDebugEnabled()) {
logger.debug("Switching JDBC Connection [" + con + "] to manual commit");
}
con.setAutoCommit(false);
}
prepareTransactionalConnection(con, definition);
txObject.getConnectionHolder().setTransactionActive(true);
int timeout = determineTimeout(definition);
if (timeout != TransactionDefinition.TIMEOUT_DEFAULT) {
txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
}
if (txObject.isNewConnectionHolder()) {
// 给当前线程绑定一下连接缓存,后续再来方便获取
// 也就是往刚才的那个map里放一下
// key还是我们的那个数据源的类,value就是连接缓存对象
// 这个也是导致我们的问题所在处二
TransactionSynchronizationManager.bindResource(obtainDataSource(), txObject.getConnectionHolder());
}
}
}
总结:就是根据我们的数据源来获取一个连接,并缓存起来,以供后续使用。并会设置一些事务的相关信息。
我们当前获取到的连接:
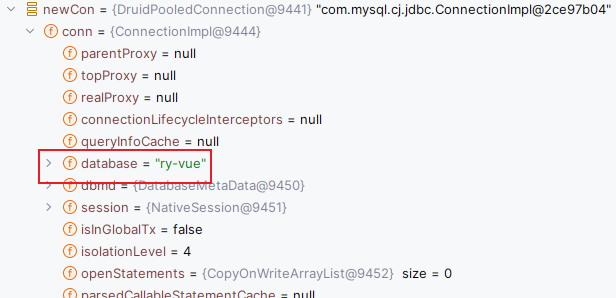
绑定的缓存:key还是我们的那个类,value就是我们根据当前数据源获取到的连接,当前数据源是第一个数据源。我们
接下来看一下第二个数据源的连接是什么。
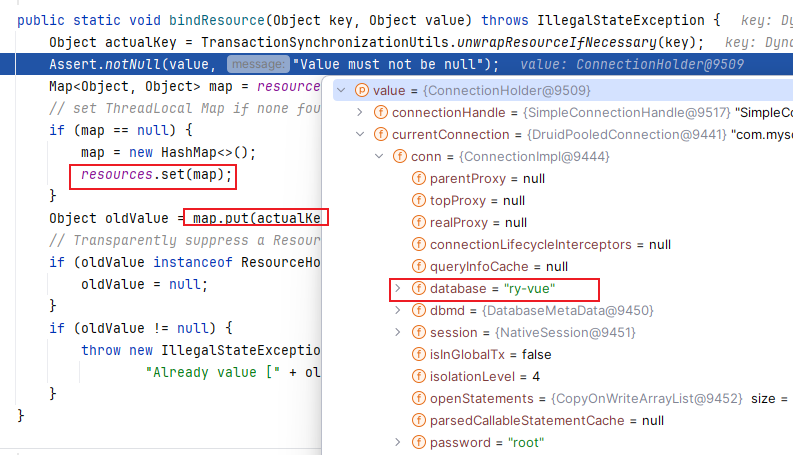
我们来看一下 obtainDataSource().getConnection() 这个方法是怎么做的:AbstractRoutingDataSource类
@Override
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
// 我们写的实现类
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceContextHolder.get();
}
是不是很熟悉?这不就是Spring给我们提供的来做动态数据源那个类的源码吗!前面已经分析过了

由于我们上下文存储的key是null,所以就给了一个默认数据源。所以获取到的是第一个数据源的连接。我们看一下第二个方法是否还是这个数据源,让我们进入第二次 Debug吧。
第二次Debug
前面都是一样的套路,但是走到这里就会发生变化了。还记得我们的三个核心方法吗?第一次 Debug的时候并没有走我们的第二个核心方法,这一次就要走了
进来的条件:判断当前事务对象是否有连接缓存并且当前连接缓存的事务是活跃的
org.springframework.transaction.support.AbstractPlatformTransactionManager#handleExistingTransaction:
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
if (debugEnabled) {
logger.debug("Suspending current transaction");
}
Object suspendedResources = suspend(transaction);
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(
definition, null, false, newSynchronization, debugEnabled, suspendedResources);
}
// 我们设置的传播特性会走这里
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
if (debugEnabled) {
logger.debug("Suspending current transaction, creating new transaction with name [" +
definition.getName() + "]");
}
// 清除一下上一次事务的信息
SuspendedResourcesHolder suspendedResources = suspend(transaction);
try {
// 开启一个新的事务(核心)
return startTransaction(definition, transaction, debugEnabled, suspendedResources);
}
catch (RuntimeException | Error beginEx) {
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
}
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
if (!isNestedTransactionAllowed()) {
throw new NestedTransactionNotSupportedException(
"Transaction manager does not allow nested transactions by default - " +
"specify 'nestedTransactionAllowed' property with value 'true'");
}
if (debugEnabled) {
logger.debug("Creating nested transaction with name [" + definition.getName() + "]");
}
if (useSavepointForNestedTransaction()) {
// Create savepoint within existing Spring-managed transaction,
// through the SavepointManager API implemented by TransactionStatus.
// Usually uses JDBC 3.0 savepoints. Never activates Spring synchronization.
DefaultTransactionStatus status =
prepareTransactionStatus(definition, transaction, false, false, debugEnabled, null);
status.createAndHoldSavepoint();
return status;
}
else {
// Nested transaction through nested begin and commit/rollback calls.
// Usually only for JTA: Spring synchronization might get activated here
// in case of a pre-existing JTA transaction.
return startTransaction(definition, transaction, debugEnabled, null);
}
}
// Assumably PROPAGATION_SUPPORTS or PROPAGATION_REQUIRED.
if (debugEnabled) {
logger.debug("Participating in existing transaction");
}
if (isValidateExistingTransaction()) {
if (definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT) {
Integer currentIsolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
if (currentIsolationLevel == null || currentIsolationLevel != definition.getIsolationLevel()) {
Constants isoConstants = DefaultTransactionDefinition.constants;
throw new IllegalTransactionStateException("Participating transaction with definition [" +
definition + "] specifies isolation level which is incompatible with existing transaction: " +
(currentIsolationLevel != null ?
isoConstants.toCode(currentIsolationLevel, DefaultTransactionDefinition.PREFIX_ISOLATION) :
"(unknown)"));
}
}
if (!definition.isReadOnly()) {
if (TransactionSynchronizationManager.isCurrentTransactionReadOnly()) {
throw new IllegalTransactionStateException("Participating transaction with definition [" +
definition + "] is not marked as read-only but existing transaction is");
}
}
}
// 默认的传播特性走这里
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
总结:就是根据不同的传播特性来做不同的事情。
先来看一下一个重要的事情,我们发现进来这个方法之后 Transaction 对象里还是有之前的连接缓存的,这是万万不行的,所以需要清掉。
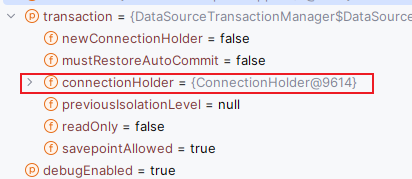
当我们经过这个方法 suspend() 后,我们神奇的发现里面的信息没有了:

直接来看一下这个方法:
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
// 清除连接信息
suspendedResources = doSuspend(transaction);
}
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException | Error ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
它里面又调用了这个方法来做:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doSuspend
@Override
protected Object doSuspend(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
// 设置为null
txObject.setConnectionHolder(null);
return TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
然后我们直接来看我们的传播特性做的事情。其实还是之前 startTransaction() 做的事情。就是开
启一个新的事务来做。我们可以看一下这一次的连接是谁的

我们发现这次的连接还是第一个数据源的连接,这就出大问题了。我们想要的是第二个数据源的连接。这是怎么回事呢?不要急,我们直接来看。
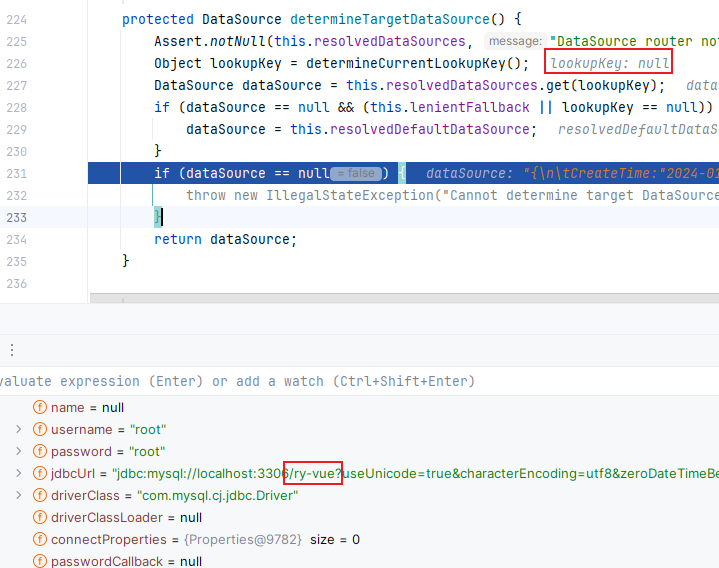
这是咋回事啊,我靠,切面没成功吗,key还是null,所以获取到的数据源就是默认的数据源了。来看一下控制台是否打印切换数据源的信息:确实没有信息

当我们全部放行之后,再次查看控制台就会发现,我们的数据源切换成功了!

what?这是什么情况。这个时候我们就要运用大脑里的知识来想一想了,想到原理。Spring事务是aop,我们的这个切换数据源的也是aop,那会不会是切面之间的执行顺序还有先后啊。于是我们直接实践,直接在切换数据源的切面上加上了 Order 注解,来提高优先级。加了之后,我们神奇的发现成功了!Amazing!
解决
优先级:
再次一路 Debug 到doBegin() 方法来验证猜想:

打开控制台查看,也会发现有信息输出:

直接成功!
同一个事务问题:
我们把第二个方法的事务的传播特性还设置回原来的 REQUIRED 或者不加事务注解。
还是来到第二个核心方法:handleExistingTransaction()
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
// Assumably PROPAGATION_SUPPORTS or PROPAGATION_REQUIRED.
// 处理 PROPAGATION_SUPPORTS 和 PROPAGATION_REQUIRED 的传播特性
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
prepareTransactionStatus():
protected final DefaultTransactionStatus prepareTransactionStatus(
TransactionDefinition definition, @Nullable Object transaction, boolean newTransaction,
boolean newSynchronization, boolean debug, @Nullable Object suspendedResources) {
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, newTransaction, newSynchronization, debug, suspendedResources);
prepareSynchronization(status, definition);
return status;
}
就是把当前的事务状态给返回了,所以后续拿到的连接还是上一个的
总结
切面的优先级问题(Order注解)
事务的传播特性(Propagation类)
文章到这里就结束了,应该还是有点长的。希望有点帮助哈。
SpringBoot 整合多数据源的事务问题的更多相关文章
- springboot整合多数据源解决分布式事务
一.前言 springboot整合多数据源解决分布式事务. 1.多数据源采用分包策略 2.全局分布式事务管理:jta-atomikos. ...
- springBoot整合多数据源
springBoot整合相关 1:springBoot整合多数据源: 应用场景: 项目需要同时连接两个不同的数据库A, B,并且它们都为主从架构,一台写库,多台读库. 工具/版本: jdk1. ...
- springboot+atomikos+多数据源管理事务(mysql 8.0)
jta:Java Transaction API,即是java中对事务处理的api 即 api即是接口的意思 atomikos:Atomikos TransactionsEssentials 是一个为 ...
- Springboot整合RocketMQ解决分布式事务
直接上代码: 代码结构如下: 依次贴出相关类: DataSource1Config: package com.example.demo.config;import org.apache.ibatis. ...
- springboot+mybatis多数据源的事务问题
1.springboot+mybatis实现多数据源后,针对单个数据源我们可以使用@Transactional(name="xxxTransactionManager") 来指定使 ...
- SpringBoot整合多数据源实现
项目架构 1.导入相关依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifac ...
- springboot整合多数据源及事物
有两种方式:一种是分包的方式.一种是加注解的方式(@DataSource(ref="")). 分包方式:项目结构图如下: 分为com.itmayiedu.test01.com.it ...
- SpringBoot整合Druid数据源
关于SpringBoot数据源请参考我上一篇文章:https://www.cnblogs.com/yueshutong/p/9409295.html 一:Druid介绍 1. Druid是什么? Dr ...
- springboot整合RocketMq(非事务)
1.配置文件 1.yml配置文件 rocketmq: #mq配置 producer: iseffect: true type: default # (transaction,default) tran ...
- SpringBoot之数据访问和事务-专题三
SpringBoot之数据访问和事务-专题三 四.数据访问 4.1.springboot整合使用JdbcTemplate 4.1.1 pom文件引入 <parent> <groupI ...
随机推荐
- POJ 1456 Supermarket【贪心 + 并查集】
http://poj.org/problem?id=1456 题意:给你 N 件不同的商品,每件商品最多可以买一次.每件物品对应两个值 pi di pi 表示物品的价值,di 表示可以买的最迟时间(也 ...
- [kuangbin] 专题13 基础计算几何 题解 + 总结
kuangbin带你飞:点击进入新世界 [kuangbin] 专题7 线段树 题解 + 总结:https://www.cnblogs.com/RioTian/p/13413897.html kuang ...
- mybatisplus 查询结果排除某字段实现
数据有Test表,表里有id,name,ip_address,last_time四个字段 通常查询写法,返回结果会把id,name,ip_address,last_time四个字段都返回 public ...
- SpringCloud学习 系列十、服务熔断与降级(2-方法级别服务降级)
系列导航 SpringCloud学习 系列一. 前言-为什么要学习微服务 SpringCloud学习 系列二. 简介 SpringCloud学习 系列三. 创建一个没有使用springCloud的服务 ...
- springboot+vue实现 下载服务端返回的文件功能
开发中会遇到,通过浏览器下载服务器端返回的文件功能,本文使用springboot+vue实现该功能. 后端代码: 注:后端返回的文件名遇到中文就会乱码,一直也没得到很好的解决方案,最后就统一返回1.x ...
- 《深入理解计算机系统》实验五 —— Perfom Lab
本次实验是CSAPP的第5个实验,这次实验主要是让我们熟悉如何优化程序,如何写出更具有效率的代码.通过这次实验,我们可以更好的理解计算机的工作原理,在以后编写代码时,具有能结合软硬件思考的能力. @ ...
- Python异步编程原理篇之协程的IO
协程的IO asyncio 作为实现异步编程的库,任务执行中遇到系统IO的时能够自动切换到其他任务.协程使用的IO模型是IO多路复用.在 asyncio 低阶API 一篇中提到过 "以Lin ...
- Liunx常用操作(11)-VI编辑器-末行模式命令
vI编辑器三种模式 分别为命令模式.输入模式.末行模式.
- wireshark 报文颜色
在使用wireshark抓包分析的过程中,默认会对不同的包进行着色,截图如下: 对不同的颜色有了解,可快速的过滤包或分析请求. 菜单栏选择视图-->着色规则,即可看到不同颜色代表的含义: 大致可 ...
- SV概述
System Verilog概述 路科验证视频,B站可看(补充一下知识) 学习SV之前,最好有Verilog基础 SV诞生 SV发展历史 Verilog - 偏向于设计 System Verilog ...