图像识别算法--VGG16
前言:人类科技就是不断烧开水(发电)、丢石头(航天等)。深度学习就是一个不断解方程的过程(参数量格外大的方程)
本文内容:
1、介绍VGG16基本原理
2、VGG16 pytorch复现
图像识别算法--VGG16
1、参考文献
VGG16:[1]SIMONYAN K, ZISSERMAN A. Very Deep Convolutional Networks for Large-Scale Image Recognition[M/OL]. arXiv, 2015[2023-04-07]. http://arxiv.org/abs/1409.1556.
Dropout:[2]SRIVASTAVA N, HINTON G, KRIZHEVSKY A, 等. Dropout: A Simple Way to Prevent Neural Networks from Overfitting[J].
2、VGG16理论
2.1 VGG16 优点
1、使用3x3的卷积核而非7x7的卷积核
First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative. Second, we decrease the number of parameters.
也就是说VGG16一方面减少了参数(相对于7x7),另外一方面通过3非线性层,更加具有非线性表达能力
2.2 VGG16网络结构图
VGG设计的神经网络结构图:
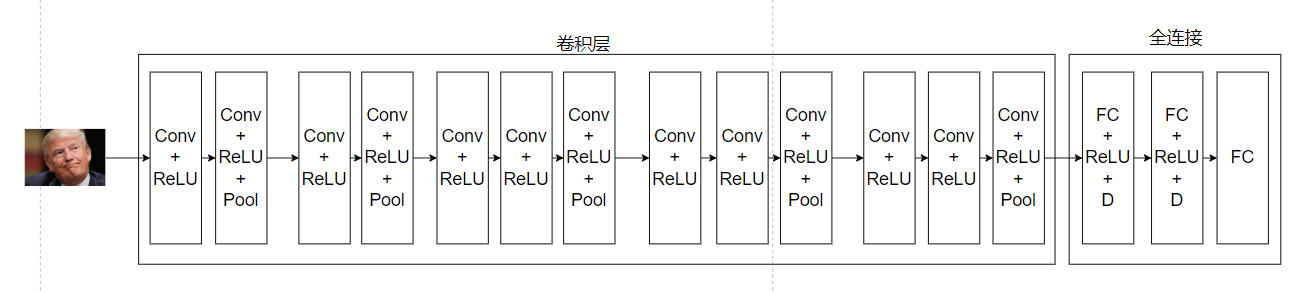
D:dropout
图片变化过程:
1:输入我们的川建国(224x224x3)--->224x224x64--->112x112x64
2:112x112x64--->112x112x128--->56x56x128
3:56x56x128--->56x56x256--->56x56x256--->28x28x256
4:28x28x256--->28x28x512--->28x28x512--->14x14x512
5:14x14x512--->14x14x512--->14x14x512--->7x7x512
变化过程第一个数字代表输入,最后一个数字代表这一层的输出,下一层的输入
全连接层:
1、输入:7x7x512(25088),输出:4096
2、输入:4096,输出4096
3、输入:4096,输出1000 (因为进行的是1000个分类)
在参考文献1中作者同时比较了下面几种不同结构(VGG11、VGG16与VGG19):

建议:
we have found that our conceptually much simpler scheme already provides a speedup of 3.75 times on an off-the-shelf 4-GPU system, as compared to using a single GPU. On a system equipped with four NVIDIA Titan Black GPUs, training a single net took 2–3 weeks depending on the architecture.
我们发现,与使用单个GPU相比,我们在概念上更简单的方案已经在现成的4 - GPU系统上提供了3.75倍的加速比。在搭载4个NVIDIA Titan Black GPU的系统上,根据架构的不同,训练单个网络需要2 ~ 3周。
访问链接:https://www.image-net.org/challenges/LSVRC/2012/index.php
如果想复现VGG16,直接使用论文作者数据是不要切合实际的:1、数据过大;2、没有这么高的电脑配置。
推荐使用数据集:https://download.pytorch.org/tutorial/hymenoptera_data.zip
url = "https://download.pytorch.org/tutorial/hymenoptera_data.zip"
save_path = os.path.join(data_dir, "hymenoptera_data.zip")
if not os.path.exists(save_path):
urllib.request.urlretrieve(url, save_path)
zip = zipfile.ZipFile(save_path)
zip.extractall(data_dir)
zip.close()
os.remove(save_path)
pytorch官方数据,主要是实现蜜蜂和蚂蚁分类,不过在使用前必须对图片进行处理,因为他提供的图片并非都是224x224x3,所以需要对图片进行转换。
"""
图片预处理:
1、图片裁剪
2、标准化
3、图片旋转
"""
class ImageTransform():
def __init__(self, resize, mean, std):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
#scale在调整大小之前,指定裁剪的随机区域的下限和上限。规模是相对于原始图像的面积来定义的
transforms.RandomHorizontalFlip(), #以给定的概率随机水平翻转给定的图像
transforms.ToTensor(), #将图片转化为张量
transforms.Normalize(mean, std) #将图片进行正则化
]),
'val': transforms.Compose([
transforms.Resize(resize), #改变尺寸
transforms.CenterCrop(resize), #中心裁剪图像
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
def __call__(self, img, phase='train'):
return self.data_transform[phase](img)
上述代码涉及到一个理论:在卷积神经网络中(VGG也是一种卷积神经网络),在对于训练集数据不足的时候,可以尝试对图片进行旋转等操作来补充训练集数据。比如我们川建国,我旋转他就相当于又增加了一个训练集数据。
如果实验室电脑配置不够:建议直接租算力(如果只是轻微使用深度学习+实验室没钱)
推荐网站:AutoDL-品质GPU租用平台-租GPU就上AutoDL,学生认证价格也还ok。网站提供GPU(部分):

多尺度评价的实验结果:

作者操作过程中还使用了:1、\(L_{2}\)范数;2、设置0.5的dropout
2.2.1 复现代码
#定义训练网络 VGG-16
import torch.nn.functional as F
class vgg16(nn.Module):
def __init__(self):
super().__init__()
#开始定义网络结构
self.conv1 = torch.nn.Conv2d(3, 64, 3, padding=(1,1))
self.conv2 = torch.nn.Conv2d(64, 64, 3, padding=(1, 1))
self.pool1 = torch.nn.MaxPool2d((2, 2), padding=(1, 1)) #64x112x112
self.conv3 = torch.nn.Conv2d(64, 128,3,padding=(1,1))
self.conv4 = torch.nn.Conv2d(128, 128, 3, padding=(1, 1))
self.pool2 = torch.nn.MaxPool2d((2, 2), padding=(1, 1))
self.conv5 = torch.nn.Conv2d(128, 256,3, padding=(1,1))
self.conv6 = torch.nn.Conv2d(256, 256,3, padding=(1, 1))
self.conv7 = torch.nn.Conv2d(256, 256,3, padding=(1, 1))
self.pool3 = torch.nn.MaxPool2d((2,2), padding=(1, 1))
self.conv8 = torch.nn.Conv2d(256, 512,3, padding=(1,1))
self.conv9 = torch.nn.Conv2d(512, 512,3, padding=(1, 1))
self.conv10 = torch.nn.Conv2d(512, 512,3, padding=(1, 1))
self.pool4 = torch.nn.MaxPool2d((2,2),padding=(1, 1))
self.conv11 = torch.nn.Conv2d(512, 512,3)
self.conv12 = torch.nn.Conv2d(512, 512,3, padding=(1, 1))
self.conv13 = torch.nn.Conv2d(512, 512,3, padding=(1, 1))
self.pool5 = torch.nn.MaxPool2d((2,2),padding=(1, 1))
self.fc1 = nn.Linear(512*7*7, 4096)
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(4096, 4096)
self.dropout2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(4096, 2)
def forward(self, x):
insize = x.size(0)
out = F.relu(self.conv1(x))
out = self.pool1(F.relu(self.conv2(out)))
out = F.relu(self.conv3(out))
out = self.pool2(F.relu(self.conv4(out)))
out = F.relu(self.conv5(out))
out = F.relu(self.conv6(out))
out = self.pool3(F.relu(self.conv7(out)))
out = F.relu(self.conv8(out))
out = F.relu(self.conv9(out))
out = self.pool4(F.relu(self.conv10(out)))
out = F.relu(self.conv11(out))
out = F.relu(self.conv12(out))
out = self.pool5(F.relu(self.conv13(out)))
out = out.view(insize, -1) #这里对于不同数据处理会有不一样,-1位于后面相当于直接将数据进行平铺-->1*n;
# -1位于前面则--->n*1
out = self.dropout1(self.act1(self.fc1(out)))
out = self.dropout2(self.act1(self.fc2(out)))
out = self.fc3(out)
out = F.log_softmax(out, dim=1)
return out
device = torch.device('cuda:0' if torch.cuda.is_available() else 'CPU')
vgg = vgg16()
x = torch.rand(size=(4, 3, 224, 224)) #相当于4张224x224的图片,所以旋转out.view(insize, -1)
"""
x = torch.rand(size=(3, 224, 224)) out.view(224*224*3, -1)
"""
vgg(x)
图像识别算法--VGG16的更多相关文章
- 再谈AR中的图像识别算法
之前在<浅谈移动平台创新玩法>简单的猜测了easyar中使用的图像识别算法,基于图片指纹的哈希算法的图片检索 .后再阿里引商大神的指点下,意识到图片检测只适用于静态图片的识别,只能做AR脱 ...
- 跟我读CVPR 2022论文:基于场景文字知识挖掘的细粒度图像识别算法
摘要:本文通过场景文字从人类知识库(Wikipedia)中挖掘其背后丰富的上下文语义信息,并结合视觉信息来共同推理图像内容. 本文分享自华为云社区<[CVPR 2022] 基于场景文字知识挖掘的 ...
- PC端车牌识别朱凯茵从事图像识别算法、OCR算法
大家好,我是从事图像识别的pc端车牌识别朱凯茵,多多交流OCR算法,不限于车牌识别等,技术需要突破,你我成就梦想.
- Neural Networks and Deep Learning(week2)Logistic Regression with a Neural Network mindset(实现一个图像识别算法)
Logistic Regression with a Neural Network mindset You will learn to: Build the general architecture ...
- 【转载】细粒度图像识别Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classification
细粒度图像识别Object-Part Attention Driven Discriminative Localization for Fine-grained Image Classificatio ...
- 机器学习算法·KNN
机器学习算法应用·KNN算法 一.问题描述 验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能.但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻.目前对验 ...
- 预训练模型与Keras.applications.models权重资源地址
什么是预训练模型 简单来说,预训练模型(pre-trained model)是前人为了解决类似问题所创造出来的模型.你在解决问题的时候,不用从零开始训练一个新模型,可以从在类似问题中训练过的模型入手. ...
- [译]使用scikit-learn进行机器学习(scikit-learn教程1)
原文地址:http://scikit-learn.org/stable/tutorial/basic/tutorial.html 翻译:Tacey Wong 概要: 该章节,我们将介绍贯穿scikit ...
- Linux之我见
Linux哲学之美 linux就像是一个哲学的最佳实践.如果非要对它评价,我真的不知道该怎么赞叹,我只能自豪的说着:“linux的美丽简直让人沉醉.” 我只能说是我处在linux学习的修炼之路上的一个 ...
- Android Sudoku第一版
经过几天的下班空闲时间写了一个android上的数独游戏,今天也申请了几个发布平台的账号,发布出去了,google play要收25刀,而且这个在大陆基本访问不上,所以暂时就没买.在移动平台写应用程序 ...
随机推荐
- postman数据驱动(.csv文件)
做api测试的时候同一个接口我们会用大量的数据(正常流/异常流)去验证,要是一种场 景写一个接口的话相对于比较麻烦,这个时候就可以使用数据驱动来实现 1.本地创建一个txt文件,第一行写上字段名,多个 ...
- 学到一个编码技巧:用重复写入代替if判断,减少程序分支
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 近期阅读了rust标准库的hashbrown库(也就是一个 ...
- ABP vNext系列文章01---模块化
一.模块化应用 1.继承AbpModule 每个模块都应该定义一个模块类.定义模块类的最简单方法是创建一个派生自AbpModule的类,如下所示: 2.配置依赖注入和其他模块---ConfigSe ...
- 在Unity中使用SQLite保存配置表数据(For Lua)
在Lua中使用sqlite Lua版本Sqlite文档:http://lua.sqlite.org/index.cgi/doc/tip/doc/lsqlite3.wiki sqlite官网:https ...
- 【三】AI Studio 项目详解——单机多机训练分布式训练--PARL
相关文章 [一]-环境配置+python入门教学 [二]-Parl基础命令 [三]-Notebook.&pdb.ipdb 调试 [四]-强化学习入门简介 [五]-Sarsa&Qlear ...
- 解决.netWebAPI输出时间格式带T问题
GlobalConfiguration.Configuration.Formatters.JsonFormatter.SerializerSettings.Converters.Add( new Ne ...
- 小知识:Linux如何删除大量小文件
环境:RHEL 6.5 + Oracle 11.2.0.4 需求:使用df -i巡检发现Inodes使用率过高,需要清理删除文件来解决.如果Inodes满,该目录将不能写,即使df -h查看还有剩余空 ...
- .NET Core开发实战(第33课:集成事件:使用RabbitMQ来实现EventBus)--学习笔记(上)
33 | 集成事件:使用RabbitMQ来实现EventBus 这一节我们来讲解如何通过 CAP 组件和 RabbitMQ 来实现 EventBus 要实现 EventBus,我们这里借助了 Rabb ...
- JS 页面离开事件 页面关闭事件,实现登录成功返回上个页面
壹 ❀ 引 登录成功后跳转到上一个页面是很常见的需求,比如在天猫添加购物车时网站会效验用户登录情况,若未登录则跳转登录,登录成功返回到先前的商品页. 这个功能实现并不困难,但因为我的奇思妙想让我先后了 ...
- 源码剖析Spring依赖注入:今天你还不会,你就输了
在之前的讲解中,我乐意将源码拿出来并粘贴在文章中,让大家看一下.然而,我最近意识到这样做不仅会占用很多篇幅,而且实际作用很小,因为大部分人不会花太多时间去阅读源码. 因此,从今天开始,我将采取以下几个 ...