【转载】 模仿学习:在线模仿学习与离线模仿学习 ———— Imitate with Caution: Offline and Online Imitation
网上闲逛找到的一篇文章,介绍模仿学习的,题目:
之所以转载这个文章是因为这个文章还是蛮浅显易懂的,而且还蛮有知识量的,尤其是自己以前对模仿学习的了解也比较粗浅,看了这个文章后学习到了知识。
离线模仿学习还好理解一些,对于在线模仿学习一直不是很理解,本文给出了一种很有名的在线模仿学习算法,Data Aggregation Approach: DAGGER
地址:
==================================================================
What’s Imitation Learning ?
As the same itself suggests, almost every species including humans learn by imitating and also improvise. That’s evolution in one sentence. Similarly we can make machines mimic us and learn from a human expert. Autonomous driving is a good example: We can make an agent learn from millions of driver demonstrations and mimic an expert driver.
This Learning from demonstrations also known as Imitation Learning (IL) is an emerging field in reinforcement learning and AI in general. The application of IL in robotics is ubiquitous, a robot can learn a policy from analysing demonstrations of the policy performed by a human supervisor.
Expert Absence vs Presence:
The Imitation learning takes 2 directions conditioned on whether the expert is absent during training or if the expert is present to correct the agent’s action. Let’s talk about the first case when the expert is absent.
Expert Absence During Training
Absence of expert basically means that the agent just has access to the expert demonstrations and nothing more than that. In these “Expert Absence” tasks, the agent tries to use a fixed training set (state-action pair) demonstrated by an expert in order to learn a policy and achieve an action as similar as possible as the expert’s one. These “Expert Absence” tasks can also be termed as offline imitation learning tasks.
This problem can be framed as supervised learning by classification. The expert demonstrates contain numerous training trajectories and each trajectory comprises a sequence of observations and a sequence of actions executed by an expert. These training trajectories are fixed and are not affected by the agent’s policy, this “Expert Absence” tasks can also be termed as offline imitation learning tasks.
This learning problem can be formulated as a supervised learning problem in which a policy can be obtained by solving a simple supervised learning problem: we can simply train a supervised learning model that directly maps the state to actions to mimic the expert through his/her demonstrations. We call this approach “behavioural cloning”.
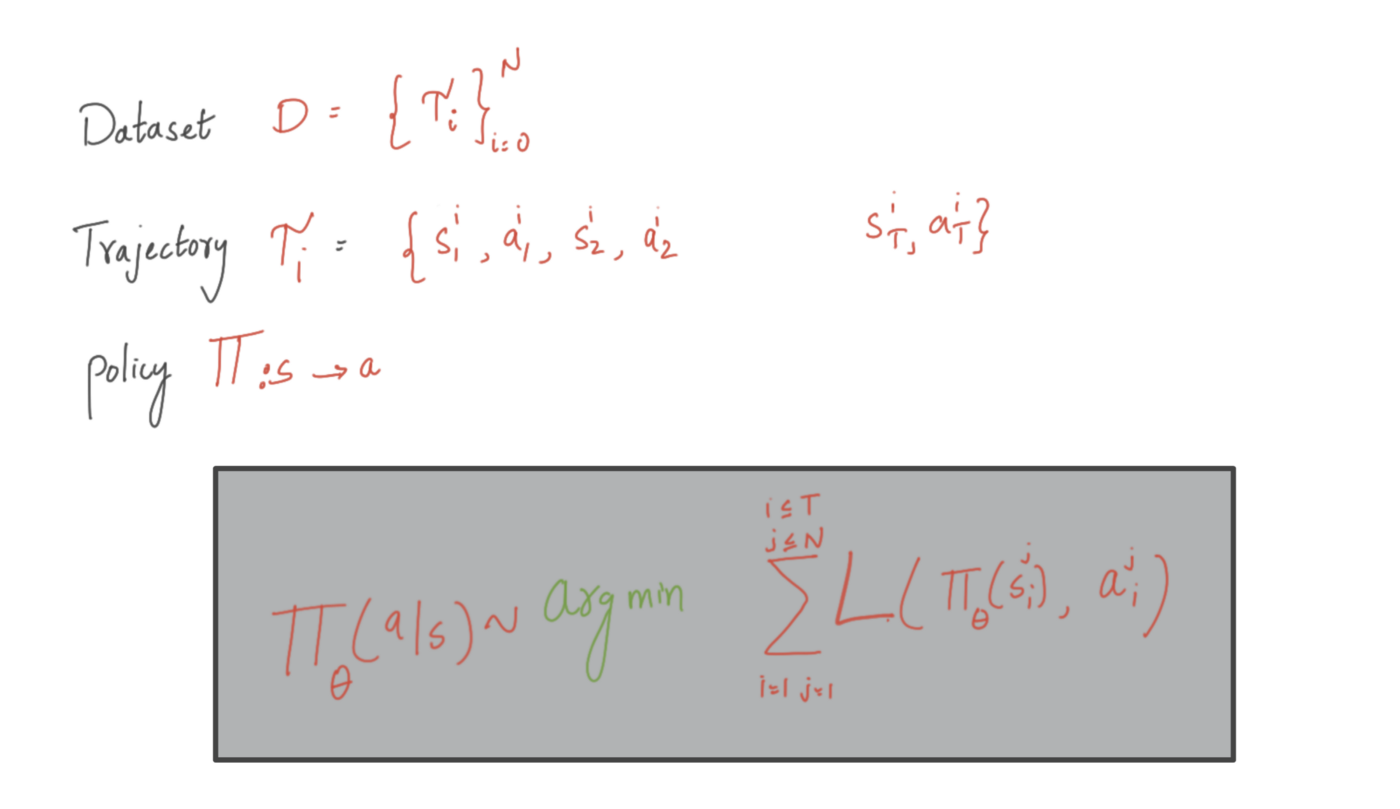
Now we need a surrogate loss function which quantifies the difference between the demonstrated behaviour and the learned policy. We use maximum expected log-likelihood functions for formulating the loss.
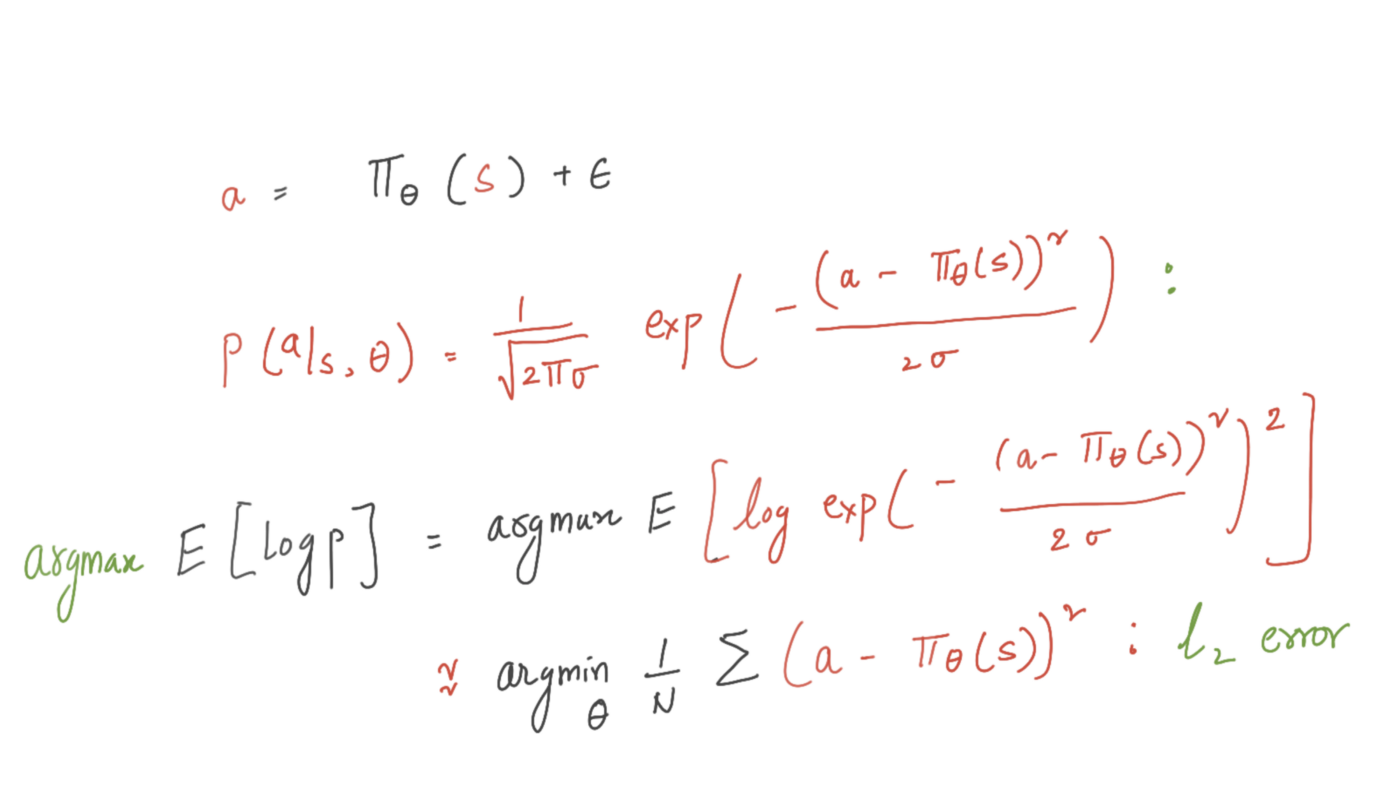
L2 error ~ Maximising Log Likelihood
we choose cross entropy if we are solving a classification problem and L2 loss if its regression problem. It’s simple to see minimising the l2 loss function is equivalent to maximising the expected log likelihood under the Gaussian distribution.
Challenges
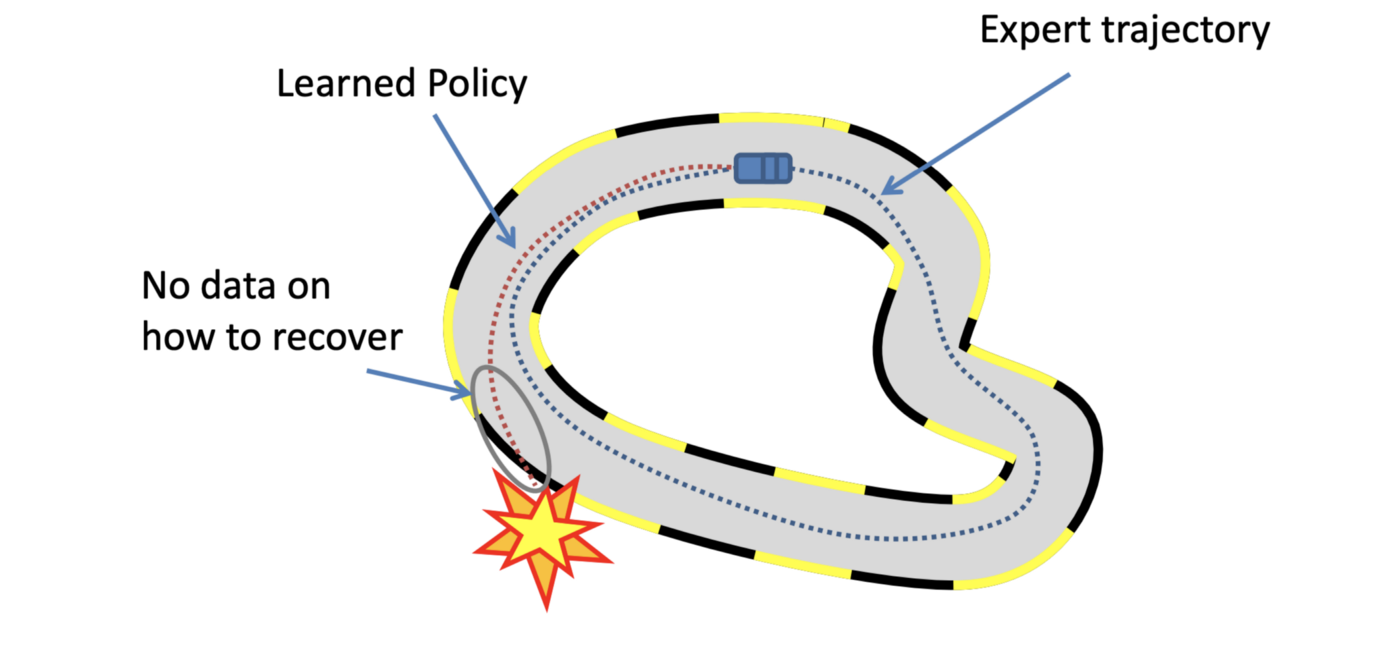
Everything looks fine till now but one important shortcoming with behavioural cloning is generalisation. Experts only collect a subset of infinite possible states that agents can experience. A simple example is that an expert car driver doesn’t collect unsafe and risky states by drift off-course, but an agent can encounter such risky states it may not have learned corrective actions as there is no data. This occurs because of “covariate shift” a known challenge, where the states encountered during training differ from the states encountered during testing, reducing robustness and generalisation.
One way to solve this “covariance shift” problem is to collect more demonstrations of risky states, this can be prohibitively expensive. Expert presence during the training can help us solve this problem and bridge the gap between the demonstrated policy and agent policy.
Expert Presence: Online Learning
In this section we will introduce the most famous on-line imitation learning algorithm called Data Aggregation Approach: DAGGER. This method is very effective in closing the gap between the states encountered during training and the states encountered during testing, i.e “covariate shift”.
What if the expert evaluates the learners policy during the learning? The expert provides the correct actions to take to the examples that come from the learner’s own behaviour. This is what DAgger tries to achieve exactly. The main advantage of DAgger is that the expert teaches the learner how to recover from past mistakes.
The steps are simple and similar to behavioural cloning except we collect more trajectories based on what agent has learned so far
1. The policy is initialised by behavioural cloning of the expert demonstrations D, resulting in policy π1
2. The agent uses π1 and interact with the environment to generate a new dataset D1 that contains trajectories
3. D = D U D1: We add the new generated dataset D1 to the expert demonstrations D.
1. New demonstrations D is used to train a policy π2…..

To leverage the presence of the expert, a mix of expert and learner is used to query the environment and collect the dataset. Thus, DAGGER learns a policy from the expert demonstrations under the state distribution induced by the learned policy. If we set β=0, which in this case means all trajectories during are generated from the learner agent.
Algorithm:

DAgger alleviates the problem of “covariance shift” ( the state distribution induced by the learner’s policy is different from the state distribution in the initial demonstration data). This approach significantly reduces the size of the training dataset necessary to obtain satisfactory performance.
Conclusion
DAgger has seen extraordinary success in robotic control and has also been applied to control UAVs. Since the learner encounters various states in which the expert did not demonstrate how to act, an online learning approach such as DAGGER is essential in these applications.
In the next blog in this series, we will understand the shortcomings of DAgger algorithm and importantly we will emphasis on the safety aspects of DAgger algorithms.
=============================================================
个人的分析:
Data Aggregation Approach: DAGGER
这个算法的详细步骤还是要看算法描述:

从算法描述中可以看到一个出现了三个策略,Pi_E是专家的策略,Pi_L是学习者的策略,Pi是采样数据时的策略。
每次训练得出新的学习者策略的数据集都是 Aggregate datesets: D 。
Aggregate datesets: D数据集是不断与采样数据融合的,不过这里我有个疑问,那就是这个数据集一直融合会不会导致数据量过大呢。
有一个需要注意的那就是Di 数据集的来历,这个数据集是使用当前学习者策略采集到的轨迹中的状态,然后使用专家策略给出这些状态下专家策略所对应的动作,然后组成状态动作对组成数据集Di 。
有一个问题就是这个超参数beta的设置是如何来的,这里其实是N次迭代也就是有N个beta,关于这个beta的设置可能只有去找原始论文和相关代码了,本文这里也只是介绍性的,因此了解这些也是OK的。
=========================================================
【转载】 模仿学习:在线模仿学习与离线模仿学习 ———— Imitate with Caution: Offline and Online Imitation的更多相关文章
- 在线算法与离线算法(online or offline)
1. 在线算法(online) PFC(prefix-free code)编码树的解码过程:可以在二进制编码串的接收过程中实时进行,而不必等到所有比特位都到达后才开始: 2. 离线算法(offline ...
- wampsever在线模式和离线模式有什么区别
我们在开发网站的时候经常会使用到wampsever服务器,在测试项目的时候我们会经常发现,wampsever服务器在线模式和离线模式都可以使用并且测试,还有一个现象就是我们在测试无线网络,用手机访问的 ...
- HDU 4605 Magic Ball Game (在线主席树|| 离线 线段树)
转载请注明出处,谢谢http://blog.csdn.net/ACM_cxlove?viewmode=contents by---cxlove 题意:给出一棵二叉树,每个结点孩子数目为0或者2. ...
- hdu 4605 Magic Ball Game (在线主席树/离线树状数组)
版权声明:本文为博主原创文章,未经博主允许不得转载. hdu 4605 题意: 有一颗树,根节点为1,每一个节点要么有两个子节点,要么没有,每个节点都有一个权值wi .然后,有一个球,附带值x . 球 ...
- SPOJ DQUERY D-query (在线主席树/ 离线树状数组)
版权声明:本文为博主原创文章,未经博主允许不得转载. SPOJ DQUERY 题意: 给出一串数,询问[L,R]区间中有多少个不同的数 . 解法: 关键是查询到某个右端点时,使其左边出现过的数都记录在 ...
- Sencha Toucha 2 —1.环境安装配置、在线打包、离线打包
环境安装配置 1. 下载 1.1 Sencha Touch 下载 http://cdn.sencha.com/touch/sencha-touch-2.2.1-gpl.zip 1 ...
- HDU 2586 How far away ?(经典)(RMQ + 在线ST+ Tarjan离线) 【LCA】
<题目链接> 题目大意:给你一棵带有边权的树,然后进行q次查询,每次查询输出指定两个节点之间的距离. 解题分析:本题有多重解决方法,首先,可用最短路轻易求解.若只用LCA解决本题,也有三种 ...
- [转载]各种在线api地址
J2SE1.7英文api地址: http://download.oracle.com/javase/7/docs/api/J2SE1.6英文api地址: http://download.oracle ...
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
课程大纲及内容简介: 每节课约35分钟,共不下40讲 第一章(11讲) ·分布式和传统单机模式 ·Hadoop背景和工作原理 ·Mapreduce工作原理剖析 ·第二代MR--YARN原理剖析 ·Cl ...
- [转载]github在线更改mysql表结构工具gh-ost
GitHub正式宣布以开源的方式发布gh-ost:GitHub的MySQL无触发器在线更改表定义工具! gh-ost是GitHub最近几个月开发出来的,目的是解决一个经常碰到的问题:不断变化的产品需求 ...
随机推荐
- JavaScript通过递归实现深拷贝
思路 首先是用Object.prototype.toString.call(obj)来得到传入的值的类型,如果是几个基本类型,则直接返回值就可以了 如果是引用类型,则通过深拷贝函数递归进行再次拷贝. ...
- MySql 表数据的增、删、改、查
数据表的增.删.改.查 前言 在学习 MySql 一定少不了对数据表的增.删.改.查,下面将详细讲解如何操作数据表. 前面已经建好了表 customer 列表如下: 插入数据 插入数据可以使用 INS ...
- 判断URL是否编码,编码后的sign对签名和验签都有影响,导致验签不通过
判断URL是否编码,编码后的sign对签名和验签都有影响,导致验签不通过如果含有 + %符号无法判断, 否则判断不准或报错 Exception in thread "main" j ...
- 关于vue中image控件,onload事件里,event.target 为null的奇怪问题探讨
废话不多说(主要文笔比较差),直接上代码 一个简单的demo,如下 <img :src="orginalImgSrc" style="display: none;& ...
- MySql用户与权限控制
MySql用户与权限控制 -- 刷新权限命令 # -- 刷新mysql权限命令 flush privileges; 用户管理 1.查看用户 #查看用户 USE mysql; SELECT host,u ...
- typora中LaTeX公式常用指令
# typora中LaTeX公式常用指令 以下指令只能保证在typora中完美显示,但是在其他编辑器中可能会部分不支持 \cal F.X.Y = KaTeX parse error: Expected ...
- 网络OSI七层模型及各层作用 tcp-ip
背景 虽然说以前学习计算机网络的时候,学过了,但为了更好地学习一些物联网协议(MQTT.CoAP.LWM2M.OPC),需要重新复习一下. OSI七层模型 七层模型,亦称OSI(Open System ...
- Yaml配置文件语法详解
YAML 简介 YAML,即 "YAML Ain't a Markup Language"(YAML 不是一种标记语言)的递归缩写,YAML 意思其实是" Yet Ano ...
- 虚拟 DOM 的优缺点?
什么是虚拟dom用js模拟一颗dom树,放在浏览器内存中.当你要变更时,虚拟dom使用diff算法进行新旧虚拟dom的比较,将变更放到变更队列中, 反应到实际的dom树,减少了dom操作. 虚拟DOM ...
- Vue 框架怎么实现对象和数组的监听?
如果被问到 Vue 怎么实现数据双向绑定,大家肯定都会回答 通过 Object.defineProperty() 对数据进行劫持,但是 Object.defineProperty() 只能对属性进行数 ...