【转载】 机器学习数据可视化 (t-SNE 使用指南)—— Why You Are Using t-SNE Wrong
原文地址:
https://towardsdatascience.com/why-you-are-using-t-sne-wrong-502412aab0c0
=====================================
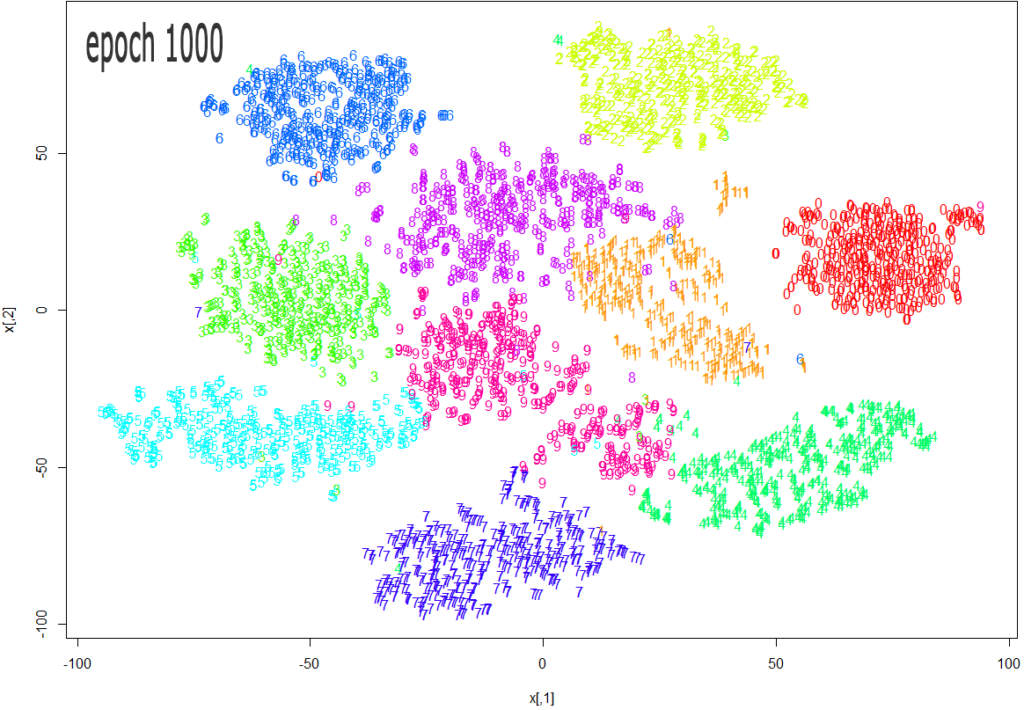
Source: https://datascienceplus.com/multi-dimensional-reduction-and-visualisation-with-t-sne/
t-SNE has become a very popular technique for visualizing high dimensional data. It’s extremely common to take the features from an inner layer of a deep learning model and plot them in 2-dimensions using t-SNE to reduce the dimensionality. Unfortunately, most people just use scikit-learn’s implementation without actually understanding the results and misinterpreting what they mean.
While t-SNE is a dimensionality reduction technique, it is mostly used for visualization and not data pre-processing (like you might with PCA). For this reason, you almost always reduce the dimensionality down to 2 with t-SNE, so that you can then plot the data in two dimensions.
The reason t-SNE is common for visualization is that the goal of the algorithm is to take your high dimensional data and represent it correctly in lower dimensions — thus points that are close in high dimensions should remain close in low dimensions. It does this in a non-linear and local way, so different regions of data could be transformed differently.
t-SNE has a hyper-parameter called perplexity. Perplexity balances the attention t-SNE gives to local and global aspects of the data and can have large effects on the resulting plot. A few notes on this parameter:
- It is roughly a guess of the number of close neighbors each point has. Thus, a denser dataset usually requires a higher perplexity value.
- It is recommended to be between 5 and 50.
- It should be smaller than the number of data points.
The biggest mistake people make with t-SNE is only using one value for perplexity and not testing how the results change with other values. If choosing different values between 5 and 50 significantly change your interpretation of the data, then you should consider other ways to visualize or validate your hypothesis.
It is also overlooked that since t-SNE uses gradient descent, you also have to tune appropriate values for your learning rate and the number of steps for the optimizer. The key is to make sure the algorithm runs long enough to stabilize.
There is an incredibly good article on t-SNE that discusses much of the above as well as the following points that you need to be aware of:
- You cannot see the relative sizes of clusters in a t-SNE plot. This point is crucial to understand as t-SNE naturally expands dense clusters and shrinks spares ones. I often see people draw inferences by comparing the relative sizes of clusters in the visualization. Don’t make this mistake.
- Distances between well-separated clusters in a t-SNE plot may mean nothing. Another common fallacy. So don’t necessarily be dismayed if your “beach” cluster is closer to your “city” cluster than your “lake” cluster.
- Clumps of points — especially with small perplexity values — might just be noise. It is important to be careful when using small perplexity values for this reason. And to remember to always test many perplexity values for robustness.
Now — as promised some code! A few things of note with this code:
- I first reduce the dimensionality to 50 using PCA before running t-SNE. I have found that to be good practice (when having over 50 features) because otherwise, t-SNE will take forever to run.
- I don’t show various values for perplexity as mentioned above. I will leave that as an exercise for the reader. Just run the t-SNE code a few more times with different perplexity values and compare visualizations.
from sklearn.datasets import fetch_mldata
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# get mnist data
mnist = fetch_mldata("MNIST original")
X = mnist.data / 255.0
y = mnist.target
# first reduce dimensionality before feeding to t-sne
pca = PCA(n_components=50)
X_pca = pca.fit_transform(X)
# randomly sample data to run quickly
rows = np.arange(70000)
np.random.shuffle(rows)
n_select = 10000
# reduce dimensionality with t-sne
tsne = TSNE(n_components=2, verbose=1, perplexity=50, n_iter=1000, learning_rate=200)
tsne_results = tsne.fit_transform(X_pca[rows[:n_select],:])
# visualize
df_tsne = pd.DataFrame(tsne_results, columns=['comp1', 'comp2'])
df_tsne['label'] = y[rows[:n_select]]sns.lmplot(x='comp1', y='comp2', data=df_tsne, hue='label', fit_reg=False)
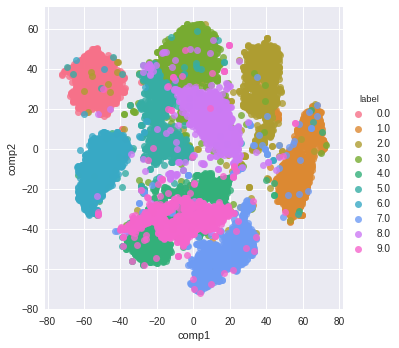
And here is the resulting visualization:
=========================================
【转载】 机器学习数据可视化 (t-SNE 使用指南)—— Why You Are Using t-SNE Wrong的更多相关文章
- 前端数据可视化echarts.js使用指南
一.开篇 首先这里要感谢一下我的公司,因为公司需求上面的新颖(奇葩)的需求,让我有幸可以学习到一些好玩有趣的前端技术,前端技术中好玩而且比较实用的我想应该要数前端的数据可视化这一方面,目前市面上的数据 ...
- 机器学习-数据可视化神器matplotlib学习之路(五)
这次准备做一下pandas在画图中的应用,要做数据分析的话这个更为实用,本次要用到的数据是pthon机器学习库sklearn中一组叫iris花的数据,里面组要有4个特征,分别是萼片长度.萼片宽度.花瓣 ...
- 机器学习-数据可视化神器matplotlib学习之路(四)
今天画一下3D图像,首先的另外引用一个包 from mpl_toolkits.mplot3d import Axes3D,接下来画一个球体,首先来看看球体的参数方程吧 (0≤θ≤2π,0≤φ≤π) 然 ...
- 机器学习-数据可视化神器matplotlib学习之路(三)
之前学习了一些通用的画图方法和技巧,这次就学一下其它各种不同类型的图.好了先从散点图开始,上代码: from matplotlib import pyplot as plt import numpy ...
- 机器学习-数据可视化神器matplotlib学习之路(二)
之前学习了matplotlib的一些基本画图方法(查看上一节),这次主要是学习在图中加一些文字和其其它有趣的东西. 先来个最简单的图 from matplotlib import pyplot as ...
- 机器学习-数据可视化神器matplotlib学习之路(一)
直接上代码吧,说明写在备注就好了,这次主要学习一下基本的画图方法和常用的图例图标等 from matplotlib import pyplot as plt import numpy as np #这 ...
- Python数据可视化编程实战pdf
Python数据可视化编程实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1vAvKwCry4P4QeofW-RqZ_A 提取码:9pcd 复制这段内容后打开百度 ...
- python数据可视化编程实战PDF高清电子书
点击获取提取码:3l5m 内容简介 <Python数据可视化编程实战>是一本使用Python实现数据可视化编程的实战指南,介绍了如何使用Python最流行的库,通过60余种方法创建美观的数 ...
- Python Seaborn综合指南,成为数据可视化专家
概述 Seaborn是Python流行的数据可视化库 Seaborn结合了美学和技术,这是数据科学项目中的两个关键要素 了解其Seaborn作原理以及使用它生成的不同的图表 介绍 一个精心设计的可视化 ...
- 机器学习PAL数据可视化
机器学习PAL数据可视化 本文以统计全表信息为例,介绍如何进行数据可视化. 前提条件 完成数据预处理,详情请参见数据预处理. 操作步骤 登录PAI控制台. 在左侧导航栏,选择模型开发和训练 > ...
随机推荐
- es6.6.1 索引的增加,查询,修改,删除
1.新增 test2/user2/1/_create PUT操作{"name":"qiqi","age":17} 2.查询 test2/us ...
- sqlCel查询一个表中部分字段的数据后插入到另一个表中
问题: 部门每天需要从后台系统将物流总表数据导出,Excel中整理出订单的物流发货渠道和发货时间,再手动导入到数据库中,整个过程不麻烦,但在Excel中比较繁琐. 需求: 将这个繁琐的过程变得更简单, ...
- Node.js 的ORM(Sequelize) 的使用
Sequelize是一个Node.js 的ORM.什么是ORM呢?对象关系映射(Object Relational Mapping).什么意思?就是在编程语言中,很容易创建对象,如果在面向对象的语言中 ...
- Spring中文官方文档
Spring 中文文档 https://springdoc.cn/ Spring Boot 中文文档 https://www.docs4dev.com/docs/zh/spring-boot/1.5. ...
- 松灵机器人scout mini小车 自主导航(2)——仿真指南
松灵机器人Scout mini小车仿真指南 之前介绍了如何通过CAN TO USB串口实现用键盘控制小车移动.但是一直用小车测试缺乏安全性.而松灵官方贴心的为我们准备了gazebo仿真环境,提供了完整 ...
- 用户数据报协议UDP
UDP的首部格式如下: (1) 源端口,源端口号.在需要对方回信时选用.不需要时可用全0. ⑵目的端口,目的端口号.这在终点交付报文时必须使用. ⑶长度,UDP用户数据报的长度,其最小值是8(仅有首部 ...
- 使用SVG做模型贴图的思路
大多数情况下,三维模型使用PNG,JPG作为模型的贴图,当然为了性能优化,有时候也会使用压缩贴图来提高渲染效率和较少GPU压力. 今天提供一种新的思路,使用SVG作为模型的贴图,可以达到动态调整图片精 ...
- 使用PHP实现字符串的上标和下标,比如:M²和Log₂FC
要在PHP中实现字符串的上标和下标效果,并直接在命令行或网页中正确显示,你可以分别使用Unicode转义序列或HTML实体来表示上标(UPER)和下标(SUB)字符.对于打印到网页的情况,可以使用HT ...
- MYSQL DQL in 到底会不会走索引&in 范围查询引发的思考。
前情引子 in 会不会走索引?很多人肯定会回答.废话.如果命中了索引.那肯定会走. 其实我和大多数人一样.一开始也是这么想的.直至有一个血淋淋的案子让我有所改观.有所思考. 背景介绍 业务的工单表.我 ...
- Django4全栈进阶之路24 项目实战(报修类型表):CKEditor富文本
CKEditor是一个强大的富文本编辑器,可以用于在网站或应用程序中创建和编辑内容.以下是在安装和使用CKEditor的一般步骤: 安装CKEditor: 下载CKEditor:访问CKEditor官 ...