实例:([Flappy Bird Q-learning]
实例:(Flappy Bird Q-learning)
问题分析
让小鸟学习怎么飞是一个强化学习(reinforcement learning)的过程,强化学习中有状态(state)、动作(action)、奖赏(reward)这三个要素。智能体(Agent,在这里就是指我们聪明的小鸟)需要根据当前状态来采取动作,获得相应的奖赏之后,再去改进这些动作,使得下次再到相同状态时,智能体能做出更优的动作。
状态的选择 在这个问题中,状态的提取方式可以有很多种:比如说取整个游戏画面做图像处理啊,或是根据小鸟的高度和管子的距离啊。在这里选用的是跟SarvagyaVaish项目相同的状态提取方式,即取小鸟到下一根下侧管子的水平距离和垂直距离差作为小鸟的状态:

(图片来自Flappy Bird RL by SarvagyaVaish)
记这个状态为,
为水平距离,
为垂直距离。
动作的选择 小鸟只有两种动作可选:1.向上飞一下,2.什么都不做。
奖赏的选择 这里采用的方式是:小鸟活着时,每一帧给予1的奖赏;若死亡,则给予-1000的奖赏;若成功经过一个水管,则给予50的奖赏。
关于Q
提到Q-learning,我们需要先了解Q的含义。
Q为动作效用函数(action-utility function),用于评价在特定状态下采取某个动作的优劣,可以将之理解为智能体(Agent,我们聪明的小鸟)的大脑。我们可以把Q当做是一张表。表中的每一行是一个状态,每一列(这个问题中共有两列)表示一个动作(飞与不飞)。
例如:
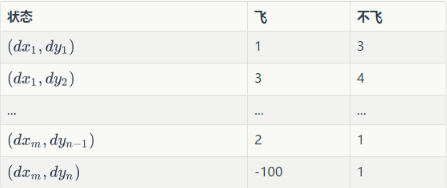
这张表一共 行,表示
个状态,每个状态所对应的动作都有一个效用值。训练之后的小鸟在某个位置处飞与不飞的决策就是通过这张表确定的。小鸟会先去根据当前所在位置查找到对应的行,然后再比较两列的值(飞与不飞)的大小,选择值较大的动作作为当前帧的动作。
训练
那么这个Q是怎么训练得来的呢,贴一段伪代码。
Initialize Q arbitrarily //随机初始化Q值
Repeat (for each episode): //每一次游戏,从小鸟出生到死亡是一个episode
Initialize S //小鸟刚开始飞,S为初始位置的状态
Repeat (for each step of episode):
根据当前Q和位置S,使用一种策略,得到动作A //这个策略可以是ε-greedy等
做了动作A,小鸟到达新的位置S',并获得奖励R //奖励可以是1,50或者-1000
Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)] //在Q中更新S
S ← S'
until S is terminal //即到小鸟死亡为止
其中有两个值得注意的地方
1.“根据当前Q和位置S,使用一种策略,得到动作A,这个策略可以是ε-greedy等。”
这里便是题主所疑惑的问题,如何在探索与经验之间平衡?假如我们的小鸟在训练过程中,每次都采取当前状态效用值最大的动作,那会不会有更好的选择一直没有被探索到?小鸟一直会被桎梏在以往的经验之中。而假若小鸟在这里每次随机选取一个动作,会不会因为探索了太多无用的状态而导致收敛缓慢?
于是就有人提出了ε-greedy方法,即每个状态有ε的概率进行探索(即随机选取飞或不飞),而剩下的1-ε的概率则进行开发(选取当前状态下效用值较大的那个动作)。ε一般取值较小,0.01即可。当然除了ε-greedy方法还有一些效果更好的方法,不过可能复杂很多。
以此也可以看出,Q-learning并非每次迭代都沿当前Q值最高的路径前进。
\2.
这个就是Q-learning的训练公式了。其中α为学习速率(learning rate),γ为折扣因子(discount factor)。根据公式可以看出,学习速率α越大,保留之前训练的效果就越少。折扣因子γ越大,所起到的作用就越大。但
指什么呢?
小鸟在对状态进行更新时,会考虑到眼前利益(R),和记忆中的利益()。
指的便是记忆中的利益。它是指小鸟记忆里下一个状态
的动作中效用值的最大值。如果小鸟之前在下一个状态
的某个动作上吃过甜头(选择了某个动作之后获得了50的奖赏),那么它就更希望提早地得知这个消息,以便下回在状态
可以通过选择正确的动作继续进入这个吃甜头的状态
。
可以看出,γ越大,小鸟就会越重视以往经验,越小,小鸟只重视眼前利益(R)。
根据上面的伪代码,就可以写出Q-learning的代码了。
成果

训练后的小鸟一直挂在那里可以飞到几千分~
实例:([Flappy Bird Q-learning]的更多相关文章
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 程序员带你一步步分析AI如何玩Flappy Bird
以下内容来源于一次部门内部的分享,主要针对AI初学者,介绍包括CNN.Deep Q Network以及TensorFlow平台等内容.由于笔者并非深度学习算法研究者,因此以下更多从应用的角度对整个系统 ...
- 如何用简单例子讲解 Q - learning 的具体过程?
作者:牛阿链接:https://www.zhihu.com/question/26408259/answer/123230350来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- DQN(Deep Q-learning)入门教程(四)之Q-learning Play Flappy Bird
在上一篇博客中,我们详细的对Q-learning的算法流程进行了介绍.同时我们使用了\(\epsilon-贪婪法\)防止陷入局部最优. 那么我们可以想一下,最后我们得到的结果是什么样的呢?因为我们考虑 ...
- canvas 制作flappy bird(像素小鸟)全流程
flappy bird制作全流程: 一.前言 像素小鸟这个简单的游戏于2014年在网络上爆红,游戏上线一段时间内appleStore上的下载量一度达到5000万次,风靡一时, 近年来移动web的普及为 ...
- 自己动手写游戏:Flappy Bird
START:最近闲来无事,看了看一下<C#开发Flappy Bird游戏>的教程,自己也试着做了一下,实现了一个超级简单版(十分简陋)的Flappy Bird,使用的语言是C#,技术采用了 ...
- C语言版flappy bird黑白框游戏
在此记录下本人在大一暑假,2014.6~8这段时间复习C语言,随手编的一个模仿之前很火热的小游戏----flappy bird.代码bug基本被我找光了,如果有哪位兄弟找到其他的就帮我留言下吧,谢谢了 ...
- 闲扯游戏编程之html5篇--山寨版《flappy bird》源码
新年新气象,最近事情不多,继续闲暇学习记点随笔,欢迎拍砖.之前的〈简单游戏学编程语言python篇〉写的比较幼稚和粗糙,且告一段落.开启新的一篇关于javascript+html5的从零开始的学习.仍 ...
- 用Phaser来制作一个html5游戏——flappy bird (一)
Phaser是一个简单易用且功能强大的html5游戏框架,利用它可以很轻松的开发出一个html5游戏.在这篇文章中我就教大家如何用Phaser来制作一个前段时间很火爆的游戏:Flappy Bird,希 ...
- 简化版的Flappy Bird开发过程(不使用第三方框架)
目录 .1构造世界 .2在世界中添加元素 .3碰撞检测 .4添加动画特效 .5总结 .0 开始之前 之前曾经用Html5/JavaScript/CSS实现过2048,用Cocos2d-html5/Ch ...
随机推荐
- MindSpore 建立神经网络
代码原地址: https://www.mindspore.cn/tutorial/zh-CN/r1.2/model.html 建立神经网络: import mindspore.nn as nn cla ...
- 2023年 IJCAI 审稿模板
================================================== ================================================= ...
- 学习使用docker-compose搭建Redis哨兵集群
搭建的记录 Redis的容器部署后,redis-server的默认安装目录为 /usr/local/bin. docker volumes 映射的文件与本地的文件共享,修改本地文件后,需要重启dock ...
- keycloak~关于社区登录的过程说明
keycloak将第三方登录(社区登录)进行了封装,大体主要会经历以下三个过程: 打开社区认证页面,输入账号密码或者扫码,完成社区上的认证 由社区进行302重定向,回到keycloak页面 keycl ...
- 09-canvas绘制坐标系
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- SMU Summer 2024 Contest Round 4
SMU Summer 2024 Contest Round 4 Made Up 题意 给你三个序列 \(A,B,C\) ,问你满足 \(A_i = B_{C_j}\) 的 \((i,j)\) 对有多少 ...
- jxls导入excel
我们在开发中经常用jxls实现导出功能,殊不知jxls也有导入功能,下面来介绍下如何使用jxls导入excel. 首先在maven的pom中添加相关依赖,如下: <dependency> ...
- AndroidStudio 各种异常情况处理大法
最近使用AndroidStudio出现了.java文件,显示为xml文件等问题,通过各种采坑之后,发现删除本地的缓存文件这个方法最管用,差不多可以根治95%的莫名其妙的问题.解决办法如下: 先将AS关 ...
- protostuff序列化接口封装
1.pom <dependency> <groupId>com.dyuproject.protostuff</groupId> <artifactId> ...
- hook拼多多客服软件发消息,拼多多客服机器人代码,拼多多发消息代码
最近由于工作需要,逆向了拼多多客服平台,能调用消息监听.消息发送.根据订单号发起会话,是纯hook实现的,demo包括c++调用demo,c#调用demo.hook 的dll是c++编写的,有需要的人 ...