【赵渝强老师】Kafka的消息持久化

1、Kafka消息持久性概述
Kakfa依赖文件系统来存储和缓存消息。对于硬盘的传统观念是硬盘总是很慢,基于文件系统的架构能否提供优异的性能?实际上硬盘的快慢完全取决于使用方式。同时 Kafka 基于 JVM 内存有以下缺点:
对象的内存开销非常高,通常是要存储的数据的两倍甚至更高
随着堆内数据的增加,GC的速度越来越慢
实际上磁盘线性写入的性能远远大于任意位置写的性能,线性读写由操作系统进行了大量优化(read-ahead、write-behind 等技术),甚至比随机的内存读写更快。所以与常见的数据缓存在内存中然后刷到硬盘的设计不同,Kafka 直接将数据写到了文件系统的日志中:
写操作:将数据顺序追加到文件中
读操作:从文件中读取
这样实现的好处:
读操作不会阻塞写操作和其他操作,数据大小不对性能产生影响
硬盘空间相对于内存空间容量限制更小
线性访问磁盘,速度快,可以保存更长的时间,更稳定
2、Kafka的持久化原理解析
一个Topic 被分成多 Partition,每个 Partition 在存储层面是一个 append-only 日志文件,属于一个 Partition 的消息都会被直接追加到日志文件的尾部,每条消息在文件中的位置称为 offset(偏移量)。

如下图所示,我们之前创建了mytopic1,具有三个分区。我们可以到对应的日志目录下进行查看。
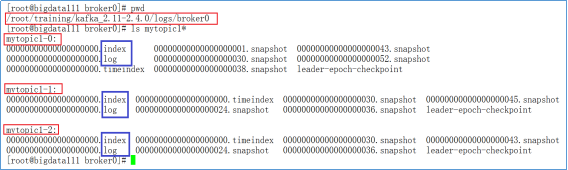
Kafka日志分为index与log(如上图所示),两个成对出现:index文件存储元数据,log存储消息。索引文件元数据指向对应log文件中message的迁移地址;例如2,128指log文件的第2条数据,偏移地址为128;而物理地址(在index文件中指定)+ 偏移地址可以定位到消息。
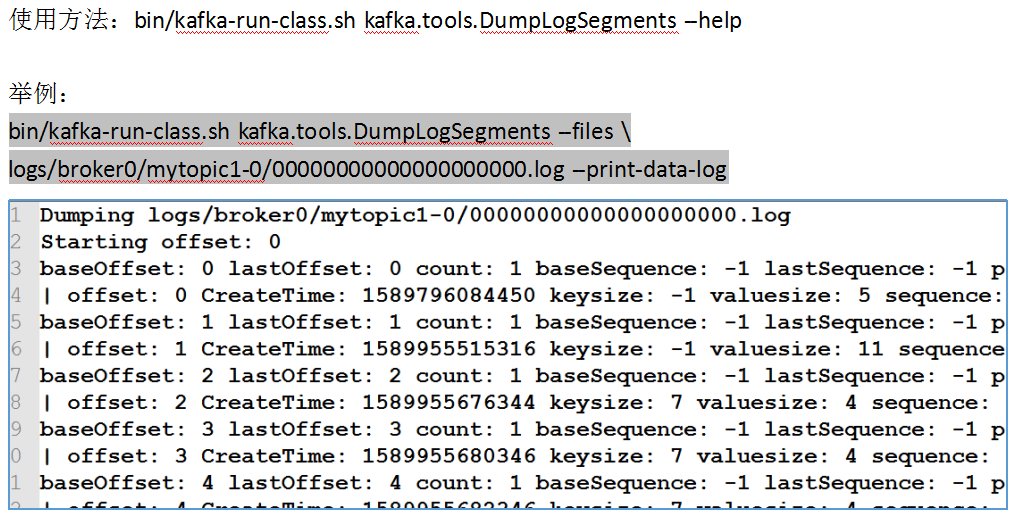
我们可以使用Kafka自带的工具来查看log日志文件中的数据信息:
【赵渝强老师】Kafka的消息持久化的更多相关文章
- kafka 讲讲acks参数对消息持久化的影响
目录 (0)写在前面 (1)如何保证宕机时数据不丢失? (2)多副本冗余的高可用机制 (3)多副本之间数据如何同步? (4)ISR到底指的什么东西? (5)acks参数的含义? (6)最后的思考 ...
- Kafka 分布式消息队列介绍
Kafka 分布式消息队列 类似产品有JBoss.MQ 一.由Linkedln 开源,使用scala开发,有如下几个特点: (1)高吞吐 (2)分布式 (3)支持多语言客户端 (C++.Java) 二 ...
- Kafka的消息格式
Commit Log Kafka储存消息的文件被它叫做log,按照Kafka文档的说法是: Each partition is an ordered, immutable sequence of me ...
- EQueue - 详细谈一下消息持久化以及消息堆积的设计
前言 之前写了一篇文章,总体介绍了EQueue.在看这篇文章之前如果还没看过那篇文章,可能会看不懂这篇文章.所以建议没看过的朋友务必先看一下那篇文章中所提到的各种概念,这样才能更好的理解本文所说的内容 ...
- 快速入门:弄懂Kafka的消息流转过程
大家都知道 Kafka 是一个非常牛逼的消息队列框架,阿里的 RocketMQ 也是在 Kafka 的基础上进行改进的.对于初学者来说,一开始面对这么一个庞然大物会不知道怎么入手.那么这篇文章就带你先 ...
- 弄懂Kafka的消息流转过程
原文地址:https://www.cnblogs.com/chanshuyi/p/quick_start_of_kafka.html 大家都知道 Kafka 是一个非常牛逼的消息队列框架,阿里的 Ro ...
- 用kafka实现消息推送
一个人知道的Topic是单点推送,大家都知道Topic是广播. kafka消息消费机制: 1.广播消费:通过定义topic前缀来标识属于广播的消息(例如:topicname:gonggao153568 ...
- 面试官让你讲讲acks参数对消息持久化的影响
(0)写在前面 面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响? 这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西 ...
- SpringBoot开发案例之整合Kafka实现消息队列
前言 最近在做一款秒杀的案例,涉及到了同步锁.数据库锁.分布式锁.进程内队列以及分布式消息队列,这里对SpringBoot集成Kafka实现消息队列做一个简单的记录. Kafka简介 Kafka是由A ...
- Kafka设计解析(十一)Kafka无消息丢失配置
转载自 huxihx,原文链接 Kafka无消息丢失配置 目录 一.Producer端二.Consumer端 Kafka到底会不会丢数据(data loss)? 通常不会,但有些情况下的确有可能会发生 ...
随机推荐
- 写写Redis十大类型hyperloglog(基数统计)的常用命令
hyperloglog处理问题的关键所在和bitmap差不多,都是为了减少对sql的写操作,提高性能,用于基数统计的算法.基数就是一种数据集,用于收集去重后内容的数量.会有0.81%的误差 hyper ...
- python multipart/form-data post接口请求
python multipart/form-data post接口请求 def WebKit_format(data, boundary="----WebKitFormBoundary*** ...
- 【Vue】Re18 Router 第五部分(KeepAlive)
一.KeepAlive概述 默认状态下,用户点击新的路由时,是访问新的组件 那么当前组件是会被销毁的,然后创建新的组件对象出来 如果某些组件频繁的使用,将造成内存空间浪费,也吃内存性能 所以需求是希望 ...
- 【Layui】08 时间线 Timeline
文档地址: https://www.layui.com/demo/timeline.html 常规时间线: <ul class="layui-timeline"> &l ...
- Pytorch使用ReduceLROnPlateau来更新学习率
如需了解完整代码请跳转到: https://www.emperinter.info/2020/08/05/change-leaning-rate-by-reducelronplateau-in-pyt ...
- IntersectionObserver + scrollIntoView 实现电梯导航
电梯导航也被称为锚点导航,当点击锚点元素时,页面内相应标记的元素滚动到视口.而且页面内元素滚动时相应锚点也会高亮.电梯导航一般把锚点放在左右两侧,类似电梯一样.常见的电梯导航效果如下,比如一些官方文档 ...
- 恶补基础知识:Java 栈与队列详解
@ 目录 前言 简介 栈 Java实现栈的示例代码: 栈的主要应用场景包括: 队列 Java实现队列的示例代码: LinkedList中的add方法和offer方法的区别 队列主要应用场景: 总结 前 ...
- Java常用类——包装类 小白版个人推荐
包装类及自动装箱/拆箱 包装类是将Java中的八种基本数据类型封装成的类,所有数据类型都能很方便地与对应的包装类相互转换,以解决应用中要求使用数据类型,而不能使用基本数据类型的情况. int a = ...
- C语言编程-GCC编译过程
gcc编译 预处理 ->编译->汇编->链接 预处理 gcc -E helloworld.c -o helloworld.i 头文件展开:不检查语法错误,即可以展开任意文件: 宏定义 ...
- 2024-08-21:用go语言,给定一个从 0 开始索引的整数数组 nums 和一个整数 k,请设计一个算法来使得数组中的所有元素都大于或等于 k,返回所需的最少操作次数。 每次操作可以执行以下步骤
2024-08-21:用go语言,给定一个从 0 开始索引的整数数组 nums 和一个整数 k,请设计一个算法来使得数组中的所有元素都大于或等于 k,返回所需的最少操作次数. 每次操作可以执行以下步骤 ...