transformer模型
Transformer由谷歌团队在论文《Attention is All You Need》提出,是基于attention机制的模型,最大的特点就是全部的主体结构均为attention。
以下部分图片来自论文,部分图片来自李宏毅老师的transformer课程
课程链接:强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili
2023-12-12
transformer模型结构:

(1) Encoder(编码器)
如图4,红色部分为编码器部分,可以看出是由Multi-Head Attention,Add & Norm, Feed Forward, Add & Norm组成的。
1.1 Add & Norm
Add & Norm层由Add和Norm两个主体构成。其中,Add是指残差连接的部分,Norm是指Layer Norlization的部分。其计算公式如下:
(2). Decoder(解码器)
如图右半部分所示,为Decoder部分,结构上与Encoder类似,但是存在以下差别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个出现值的概率。
1、Self-attention:


自注意力机制中有三个重要的输入矩阵:查询矩阵Q(query)、键矩阵K(key)和值矩阵V(value)。这三个矩阵都是由输入序列经过不同的线性变换得到的。query 、 key & value 的概念其实来源于推荐系统。基本原理是:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。
a1,a2,a3,a4分别是有关输入的4个vector,以a1为例,a1 * Wq1 = q1(其中的Wq1也是一个矩阵,不过此矩阵是通过训练模型得到的参数,同理,k1,k2,k3,k4,v1,v2,v3,v4也是通过与矩阵Wk1,WK2,WV1,WV2...相乘得到)。
然后以q2为例,q2分别与k1,k2,k3,k4做dot-product(也是矩阵相乘)得到a2-1,a2-2,a2-3,a2-4
a2-1,a2-2,a2-3,a2-4分别与v1,v2,v3,v4矩阵相乘,再相加得到b2 (公式见图片右上角)
※ 自注意力机制的计算过程包括三个步骤:
- 计算注意力权重:计算每个位置与其他位置之间的注意力权重,即每个位置对其他位置的重要性。
- 计算加权和:将每个位置向量与注意力权重相乘,然后将它们相加,得到加权和向量。
- 线性变换:对加权和向量进行线性变换,得到最终的输出向量。



2、Multi-head self-attention 多头自注意力
transformer的attention是基于多头机制的self-attention构成的,将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。



与上面同理,只不过此处以两头为例,q1只与Ki1,kj1做dot-product得到ai1, aj1; ai1, aj1再与vi1,vj1做矩阵乘法,结果相加得到bi1
3、transformer's Encoder&Decoder


此处值得注意的是用到了残差模块residual,layer Norm,

第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量 Key 和 Value。这些向量将在每个解码器的 Encoder-Decoder Attention 层被使用,这有助于解码器把注意力集中在输入序列的合适位置
在完成了编码阶段后,我们开始解码阶段。解码阶段的每个时间步都输出一个元素。
接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。就像我们处理编码器输入一样,我们也为解码器的输入加上位置编码,来指示每个词的位置。
Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于编码器栈的输出。
4、Decoder中的Masked self-attention

mask self-attention中“mask"代表了掩盖的意思,ai不再受右边的ai+n的影响,因为在生成的过程中,ai左边的已经生成了,而右边的并没有生成,无法对此处的ai产生影响。
5. Input
Transformer的输入主要由单词embedding和位置embedding组成Transformer的embedding
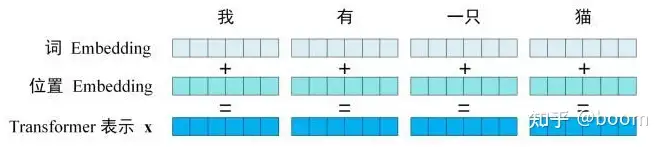
5.1单词embedding
单词embedding可以由多种方式获取,初始化+训练或者通过work2vec、glove等算法与训练得到。
5.2位置embedding
transformer最大的改变是彻底放弃了RNN结构,使用了self-attention作为核心的结构,self-attention利用的是全局信息,而没有使用位置信息,而这部分信息对NLP来说非常重要。所以,self-attention加入了位置embedding来弥补这部分的缺失。

Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。最后选择最高概率所对应的单词,作为这个时间步的输出.
transformer模型的更多相关文章
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- transformer模型解读
最近在关注谷歌发布关于BERT模型,它是以Transformer的双向编码器表示.顺便回顾了<Attention is all you need>这篇文章主要讲解Transformer编码 ...
- transformer模型简介
Transformer模型由<Attention is All You Need>提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成.论文地 ...
- Transformer模型---decoder
一.结构 1.编码器 Transformer模型---encoder - nxf_rabbit75 - 博客园 2.解码器 (1)第一个子层也是一个多头自注意力multi-head self-atte ...
- Transformer模型---encoder
一.简介 论文链接:<Attention is all you need> 由google团队在2017年发表于NIPS,Transformer 是一种新的.基于 attention 机制 ...
- Transformer模型总结
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 它是由编码组件.解码组件和它们之间的连接组成. 编码组件部分由一堆编码器(6个 enco ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
- RealFormer: 残差式 Attention 层的Transformer 模型
原创作者 | 疯狂的Max 01 背景及动机 Transformer是目前NLP预训练模型的基础模型框架,对Transformer模型结构的改进是当前NLP领域主流的研究方向. Transformer ...
随机推荐
- from my mac
hello
- 图解 LeetCode 算法汇总——链表
本文首发公众号:小码A梦 一般数据主要存储的形式主要有两种,一种是数组,一种是链表.数组是用来存储固定大小的同类型元素,存储在内存中是一片连续的空间.而链表就不同于数组.链表中的元素不是存储在内存中可 ...
- modbus转profinet网关连接UV系列流量计程序实例
modbus转profinet网关连接UV系列流量计程序实例 用户现场是西门子1200PLC通过兴达易控Modbus转Profinet网关连接流量计的配置,对流量瞬时值及报警值监控及控制程序案例 硬件 ...
- nfls10.1
T1 大水题,用位运算更加便捷求解. T2 看出来有环了,但是没往基环树上想,寄. 暴力分,有部分分是基础树,可以跑一遍深搜,根节点的选择是 k 种颜色,剩下的是 k - 1 种颜色.还有暴力是可以二 ...
- [NOI2014] 字符串(题解)
字符串(题解) 题目描述 近日,园长发现动物园中好吃懒做的动物越来越多了.例如企鹅,只会卖萌向游客要吃的.为了整治动物园的不良风气,让动物们凭自己的真才实学向游客要吃的,园长决定开设算法班,让动物们学 ...
- 再学Blazor——扩展方法
上篇提到 Blazor 组件的高级写法,是采用扩展方法对 HTML 元素和组件进行扩展,以便于书写组件结构和代码阅读.本篇主要介绍扩展方法实现的思路. 什么是扩展方法 要扩展哪个类 扩展方法的实现 1 ...
- [ABC205E] White and Black Balls 题解
White and Black Balls 题目大意 将 \(n\) 个白球,\(m\) 个黑球排成一列,要求满足 \(\forall i\in[1,n+m],w_i\le b_i+k\),问存在多少 ...
- k8s-1.23.6 安装部署文档(超详细)
一.文档简介 作者:lanjiaxuan 邮箱:lanheader@163.com 博客地址:https://www.cnblogs.com/lanheader/ 更新时间:2022-09-09 二. ...
- [Python急救站课程]绘制蜡笔小新图案
可爱的蜡笔小新想要吗?画起来 import turtle as t '''设置''' t.setup(800, 500) # 创建画布并使其位于屏幕中心 t.pensize(2) # 画笔粗细 t.c ...
- AcWing 456. 车站分级
原题链接AcWing 456. 车站分级 抽象出题意,停靠过的车站的等级一定严格大于为停靠过的车站的等级,且不存在环,例如车站\(A\)等级大于车站\(B\),则\(A >= B + 1\),不 ...