基于Prometheus和Grafana的监控平台 - 运维告警
通过前面几篇文章我们搭建好了监控环境并且监控了服务器、数据库、应用,运维人员可以实时了解当前被监控对象的运行情况,但是他们不可能时时坐在电脑边上盯着DashBoard,这就需要一个告警功能,当服务器或应用指标异常时发送告警,通过邮件或者短信的形式告诉运维人员及时处理。
今天我们就来聊聊 基于Prometheus和Grafana的监控平台的异常告警功能。
告警方式
Grafana
新版本的Grafana已经提供了告警配置,直接在dashboard监控panel中设置告警即可,但是我用过后发现其实并不灵活,不支持变量,而且好多下载的图表无法使用告警,所以我们不选择使用Grafana告警,而使用Alertmanager。

Alertmanager
相比于Grafana的图形化界面,Alertmanager需要依靠配置文件实现,配置稍显繁琐,但是胜在功能强大灵活。接下来我们就一步一步实现告警通知。
告警类型
Alertmanager告警主要使用以下两种:
- 邮件接收器 email_config
- Webhook接收器 webhook_config,会用post形式向配置的url地址发送如下格式的参数。
{
"version": "2",
"status": "<resolved|firing>",
"alerts": [{
"labels": < object > ,
"annotations": < object > ,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>"
}]
}这次主要使用邮件的方式进行告警。
#### 实现步骤
下载
从GitHub上下载最新版本的Alertmanager,将其上传解压到服务器上。
tar -zxvf alertmanager-0.19.0.linux-amd64.tar.gz- 配置Alertmanager
vi alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'mail.163.com:25' #邮箱发送端口
smtp_from: 'xxx@163.com'
smtp_auth_username: 'xxx@163.com' #邮箱账号
smtp_auth_password: 'xxxxxx' #邮箱密码
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 10s # 在发送新警报前的等待时间
repeat_interval: 1h # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxx@xxx.com'修改完成后可以使用./amtool check-config alertmanager.yml校验文件是否正确。
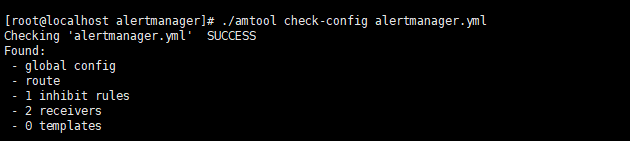
校验正确启动alertmanager。`nohup ./alertmanager &`。(第一次启动可以不使用nohup静默启动,方便后面查看日志)
我们只定义了一个路由,那就意味着所有由Prometheus产生的告警在发送到Alertmanager之后都会通过名为`email`的receiver接收。实际上,对于不同级别的告警,会有不同的处理方式,因此在route中,我们还可以定义更多的子Route。具体配置规则大家可以去百度进一步了解。配置Prometheus
在Prometheus安装目录下建立rules文件夹,放置所有的告警规则文件。alerting: alertmanagers: - static_configs: - targets: ['192.168.249.131:9093'] rule_files: - rules/*.yml
在rules文件夹下建立告警规则文件service_down.yml,当服务器下线时发送邮件。
groups: - name: ServiceStatus rules: - alert: ServiceStatusAlert expr: up == 0 for: 2m labels: team: node annotations: summary: "Instance {{ $labels.instance }} has bean down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minutes." value: "{{ $value }}"
**配置详解** alert:告警规则的名称。
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为PENDING,等待期后为FIRING。
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
配置完成后重启Prometheus,访问Prometheus查看告警配置。
- 测试
关闭node_exporter,过2分钟就可以收到告警邮件啦,截图如下:
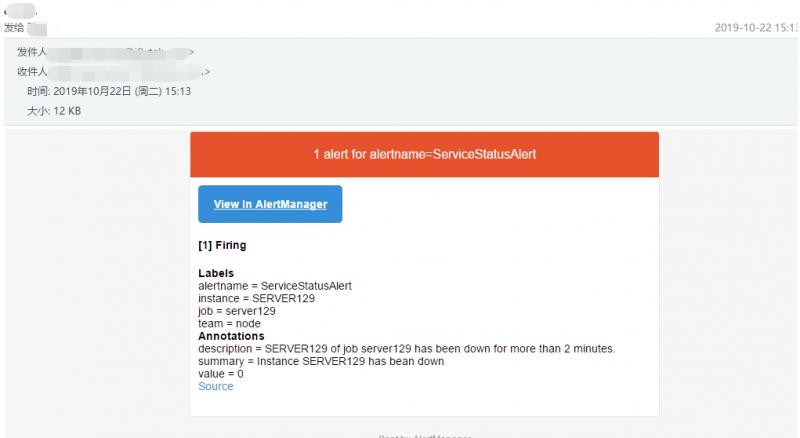
Alertmanager的告警内容支持使用模板配置,可以使用好看的模板进行渲染,感兴趣的可以试试!The More
CPU使用率(单位为percent)
(avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)内存已使用(单位为bytes)
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes内存使用量(单位为bytes/sec)
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes内存使用率(单位为percent)
((node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes)/node_memory_MemTotal_bytes) * 100server1的内存使用率(单位为percent)
((node_memory_MemTotal_bytes{instance="server1"} - node_memory_MemAvailable_bytes{instance="server1"})/node_memory_MemTotal_bytes{instance="server1"}) * 100server2的磁盘使用率(单位为percent)
((node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"} - node_filesystem_free_bytes{fstype=~"xfs|ext4",instance="server2"}) / node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"}) * 100uptime时间(单位为seconds)
time() - node_boot_timeserver1的uptime时间(单位为seconds)
time() - node_boot_time_seconds{instance="server1"}网络流出量(单位为bytes/sec)
irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0server1的网络流出量(单位为bytes/sec)
irate(node_network_transmit_bytes_total{instance="server1", device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0网络流入量(单位为bytes/sec)
irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0server1的网络流入量(单位为bytes/sec)
irate(node_network_receive_bytes_total{instance="server1", device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0磁盘读取速度(单位为bytes/sec)
irate(node_disk_read_bytes_total{device=~"sd.*"}[5m])
请关注个人公众号:JAVA日知录

基于Prometheus和Grafana的监控平台 - 运维告警的更多相关文章
- 基于Prometheus和Grafana的监控平台 - 环境搭建
相关概念 微服务中的监控分根据作用领域分为三大类,Logging,Tracing,Metrics. Logging - 用于记录离散的事件.例如,应用程序的调试信息或错误信息.它是我们诊断问题的依据. ...
- Centos7.X 搭建Prometheus+node_exporter+Grafana实时监控平台
Prometheus简介 什么是 Prometheus Prometheus是一个开源监控报警系统和时序列数据库 主要功能 多维数据模型(时序由 metric 名字和 k/v 的 labels 构成) ...
- Centos8.X 搭建Prometheus+node_exporter+Grafana实时监控平台
Prometheus Promtheus是一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,因此项目目录下需要一个data目录,需要我们自己创建,下面会讲到 下载 下载好的.tar.gz包放 ...
- Docker监控平台prometheus和grafana,监控redis,mysql,docker,服务器信息
Docker监控平台prometheus和grafana,监控redis,mysql,docker,服务器信息 一.通过redis_exporter监控redis 1.1 下载镜像 1.2 运行服务 ...
- 理解OpenShift(7):基于 Prometheus 的集群监控
理解OpenShift(1):网络之 Router 和 Route 理解OpenShift(2):网络之 DNS(域名服务) 理解OpenShift(3):网络之 SDN 理解OpenShift(4) ...
- 基于Ansible实现Apache Doris快速部署运维指南
Doris Ansible 使用指南 Apache Doris 介绍 Apache Doris是一个现代化的MPP分析型数据库产品.仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析.Apac ...
- 1+X云计算平台运维与开发(中级)eNSP A~E卷 试题+答案
1+X云计算平台运维与开发(中级)eNSP A~E卷 试题+答案 A卷 路由器管理(40分) 41 配置R1和R2路由器(路由器使用R2220),R1路由器配置端口g0/0/1地址为192.168.1 ...
- 远见而明察近观若明火|Centos7.6环境基于Prometheus和Grafana结合钉钉机器人打造全时监控(预警)Docker容器服务系统
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_181 我们知道,奉行长期主义的网络公司,势必应在软件开发流程管理体系上具备规范意识,即代码提交有CR(CodeReview),功能 ...
- 借助Docker搭建JMeter+Grafana+Influxdb监控平台
我们都知道Jmeter提供了原生的结果查看,既然有原生的查看结果,为什么还要多此一举使用其他工具进行查看呢,除了查看内容丰富外还有最主要的原因:Jmeter提供的查看结果插件本身是比较消耗性能的,所以 ...
随机推荐
- PTA A1015
A1015 Reversible Primes (20 分) 题目内容 A reversible prime in any number system is a prime whose "r ...
- FourAndSix2 靶机渗透
0x01 简介 FourAndSix2是易受攻击的一个靶机,主要任务是通过入侵进入到目标靶机系统然后提权,并在root目录中并读取flag.tx信息 FourAndSix2.镜像下载地址: https ...
- Vue学习之vue中的计算属性和侦听器
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 从零开始OpenGL—— 一、 环境配置
前言 高考完之后填志愿,当时想以后去做游戏,所以选择了计算机这个专业,之前捣鼓过U3D,这学期也开始了计算机图形学的学习,最近学习了OpenGL相关的一些内容,将在博客中记录这系列的学习.这篇开篇博客 ...
- Mac配置环境变量path
查看当前配置的path有哪些: 1. echo $PATH 当前所有的 2. cat /etc/paths 这个文件是操作系统自带的 mac系统环境变量的加载顺序(优先级): /etc/profi ...
- Docker service endpoint with name xxx already exist问题
这是因为利用docker compose启的容器再用docker rm命令删除后,网络仍然被占用,需要手动清理 解决办法: 先用docker rm -f xxx删除容器 再输入docker netwo ...
- Hadoop点滴-Hadoop的IO
Hadoop自带一套原子操作用于数据的I/O操作. 如果系统中需要处理的数据量达到Hadoop的处理极限时,数据被损害的概率还是很高的 检测数据是否被损害的常见措施是,在数据第一次被引进系统时,计算校 ...
- 十分钟快速学会Matplotlib基本图形操作
在学习Python的各种工具包的时候,看网上的各种教程总是感觉各种方法很多很杂,参数的种类和个数也十分的多,理解起来需要花费不少的时间. 所以我在这里通过几个例子,对方法和每个参数都进行详细的解释,这 ...
- Navicat使用常见的两个问题及解决方法,提高开发效率
Navicat使用常见问题 在我们日常开发过程中,一般不会直接使用命令行来操作 MYSQL 数据库,而会选择一些图形化界面去帮助我们来进行此类操作,常用的有:SQLyog(Logo也是小海豚),Nav ...
- Java 学习笔记之 Error和Exception的联系
Error和Exception的联系: Error和Exception的联系 继承结构:Error和Exception都是继承于Throwable,RuntimeException继承自Excepti ...