python批量处理压缩文件
python批量处理压缩文件
博客小序:在数据的处理中,下载的数据很有可能是许多个压缩文件,自己一个一个解压较为麻烦,最近几日自己在处理一次下载的数据时,遇到大量的压缩数据需要处理,于是利用python进行了处理,特撰此博文以记之。
参考博客:
https://blog.csdn.net/qq_38697681/article/details/79424259
https://blog.csdn.net/brucewong0516/article/details/79064384
1.脚本处理情况说明
本实例中,需要处理的压缩数据是分省的数据,每个省由若干数量不同的压缩包构成,数据具体情况见截图,本脚本主要的任务有两个:
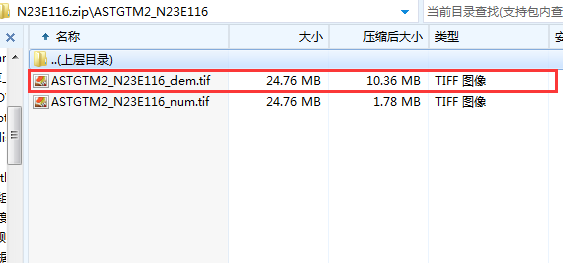
1.将压缩文件中需要的(xxxxxdem.tif)数据解压提取出来
2.将提取出来的数据仍按照省份进行存储

2.脚本代码
#添加一个计时器
import time
start = time.time()
import os
import shutil
import glob
import zipfile
def un_zip(all_o_files,new_folder_dir,key_words):
# 读取原文件夹下的压缩文件
for i in all_o_files:
new_file = new_folder_dir + "\\" + os.path.basename(i)
if os.path.exists(new_file):
shutil.rmtree(new_file)
os.mkdir(new_file)
else:
os.mkdir(new_file)
all_zip_files = glob.glob(i + "\\*.zip")
# 对于每个压缩文件
for z in all_zip_files:
# 对没有损毁的压缩包进行解压
try:
zip_data = zipfile.ZipFile(z)
a_name = zip_data.namelist()
for name in a_name:
if (name.find(key_words)) > -1:
try:
zip_data.extract(name, new_file)
except:
print(z + "解压失败")
pass
print(z + "解压完成!!!!!!!!")
zip_data.close()
except:
bad_file.append(z)
print(z + "文件已损毁")
tif_file = glob.glob(new_file + "\\" + "*")
for file in tif_file:
tif_datas = glob.glob(file + "\\"+ "*.tif")
for tif_data in tif_datas:
shutil.move(tif_data, new_file)
shutil.rmtree(file)
o_folder_dir = "D:\\cnblogs\\data\\china"
all_o_files = glob.glob(o_folder_dir + "\\*")
#选择新文件存储的位置,如果在源文件的目录下则不要自己手动创建,
new_folder_dir = "D:\\cnblogs\\data\\china_unzip"
if os.path.exists(new_folder_dir):
shutil.rmtree(new_folder_dir)
os.mkdir(new_folder_dir)
else:
os.mkdir(new_folder_dir)
bad_file = []
#需要解压的出来的文件名称中通有的名字特征,最好是名称结尾的,如.tif等表示文件类型的
key_words = "dem.tif"
un_zip(all_o_files,new_folder_dir,key_words)
print("全部解压完毕!!!!!!!")
print("损毁的压缩文件包括如下:")
print(bad_file)
end = time.time()
print ("程序运行时间{:.2f}分钟".format((end-start)/60.0))
3.问题总结
1.由于开始时没有考虑压缩文件存在损毁的情况,所以第一次写出来的脚本存在一定的问题,也提醒自己要注意脚本编写过程中可能遇到的异常情况,适当的使用try,except来捕获可能出现的问题
2.本代码只考虑了.zip类型的压缩文件,还有其他形式的压缩文件暂未考虑,未来有机会遇到再补充。
本文作者:DQTDQT
限于作者水平有限,如文中存在任何错误,欢迎不吝指正、交流。
联系方式:
QQ:1426097423
E-mail:duanquntaoyx@163.com
本文版权归作者和博客园共有,欢迎转载、交流,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,如果觉得本文对您有益,欢迎点赞、探讨。
python批量处理压缩文件的更多相关文章
- python批量运行py文件
import os path="E:\\python" #批量的py文件路径 for root,dirs,files in os.walk(path): #进入文件夹目录 for ...
- Python脚本破解压缩文件口令(zipfile)
环境:Windows python版本2.7.15 Python中操作zip压缩文件的模块是 zipfile . 相关文章:Python中zipfile压缩文件模块的使用 我们破解压缩文件的口令也是用 ...
- Python中zipfile压缩文件模块的使用
目录 zipfile 压缩一个文件 解压文件 高级应用 利用 zipfile 模块破解压缩文件口令:Python脚本破解压缩文件口令 zipfile Python 中 zipfile 模块提供了对 z ...
- python批量改动指定文件夹文件名称
这小样例仅仅要是说明用python怎么批量改动指定文件夹的文件名称: 记得要把脚本跟改动的文件放在同一个文件夹下 #encoding:utf-8 import os import sys files ...
- python批量读取txt文件为DataFrame
我们有时候会批量处理同一个文件夹下的文件,并且希望读取到一个文件里面便于我们计算操作.比方我有下图一系列的txt文件,我该如何把它们写入一个txt文件中并且读取为DataFrame格式呢? 首先我们要 ...
- python批量处理excel文件数据
https://www.zhihu.com/question/39299070?sort=created 作者:水中柳影链接:https://www.zhihu.com/question/392990 ...
- 【Python】zlib压缩文件
import zlib import os ss = 's' * 1024 * 1024 #写入原始文件 file = open("src.dat", "wb" ...
- day6学python 生成器迭代器+压缩文件
生成器迭代器+压缩文件 readme的规范 1软件定位,软件的基本功能2运行代码的方法:安装环境,启动命令3简要的使用说明4代码目录结构说明,更详细点可以说明软件的基本原理5常见问题说明 ====== ...
- python批量创建txt文件,以demo.txt内的内容为文件名
#批量创建txt文件import sys,osa=open("demo.txt")n=0aList=[]for line in a.readlines(): aList.appen ...
随机推荐
- bootstrap-treeview后台Json数据的封装及前台的显示
1.bootStrap-treeview是我们常用的树形结构,页面风格也比较清新,但是后台数据的封装比较麻烦,经过研究终于解决,和大家分享一下. 2.前端代码如下 <script> var ...
- tornado并发性能测试
1.带server2.0装饰器 接口访问数据库查询 并发100 平均每秒处理11.8次请求 平均响应时间6944ms 接口不做任何处理 并发100 平均每秒处理99.9次请求 平均响应时间3ms 并发 ...
- MyBatis 框架 基础应用
1.ORM的概念和优势 概念: 对象关系映射(Object Relational Mapping,简称ORM)是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据 ...
- css3系列之transform详解translate
translate translate这个参数的,是transform 身上的,那么它有什么用呢? 其实他的作用很简单,就是平移,参考自己的位置来平移 translate() translateX() ...
- PID算法 旋转倒立摆与平衡车的区别。此贴后边会更新。
我做PID算法的背景和经历:本人之前电子信息科学与技术专业,对控制方向颇感兴趣,刚上大学时听到实验室老师说PID算法,那年在暑假集训准备全国电子设计竞赛,我正在练习做一个以前专科的题目,帆板角度控制系 ...
- Docker:跨主机通信
修改主机docker默认的虚拟网段,然后在各自主机上分别把对方的docker网段加入到路由表中,配合iptables即可实现docker容器夸主机通信.配置方法如下: 设有三台虚拟机 v1: 10.1 ...
- 用HTML5的canvas做一个时钟
对于H5来说,canvas可以说是它最有特色的一个地方了,有了它之后我们可以随意的在网页上画各种各样的图形,做一些小游戏啊什么的.canvas这个标签的用法,在网上也有特别多的教程了,这里就不作介绍了 ...
- SDS模块
早上花了一点时间读了下sds的相关源码,其实sds就是构造了两个字段用来记录len和free的状态,然后还有一个char[]用来记录字符串的值. 然后sds模块的函数都是在模拟str的操作. 比较,追 ...
- Android使用com.google.android.cameraview.CameraView进行拍照
import android.Manifest;import android.annotation.SuppressLint;import android.content.Context;import ...
- 9、数组中删除元素(test6.java)
前文讲到,通过函数,进行数组元素的添加,这里同样通过这个函数,进行数组的删除. 举个例子,代码如下: //导入输入所需要的包 import java.util.Scanner; public clas ...