Spark学习之路(十二)—— Spark SQL JOIN操作
一、 数据准备
本文主要介绍Spark SQL的多表连接,需要预先准备测试数据。分别创建员工和部门的Datafame,并注册为临时视图,代码如下:
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")
两表的主要字段如下:
emp员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金
dept部门表
|-- DEPTNO: 部门编号
|-- DNAME: 部门名称
|-- LOC: 部门所在城市
注:emp.json,dept.json可以在本仓库的resources目录进行下载。
二、连接类型
Spark中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉(或笛卡尔)连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
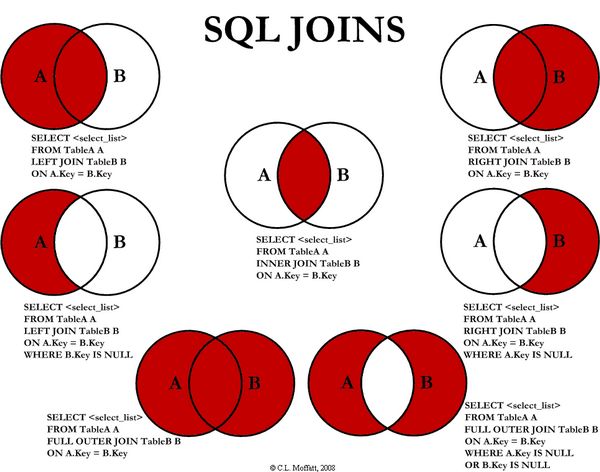
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的IN和NOT IN字句:
-- LEFT SEMI JOIN
SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的IN语句
SELECT * FROM emp WHERE deptno IN (SELECT deptno FROM dept)
-- LEFT ANTI JOIN
SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的IN语句
SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept)
所有连接类型的示例代码如下:
2.1 INNER JOIN
// 1.定义连接表达式
val joinExpression = empDF.col("deptno") === deptDF.col("deptno")
// 2.连接查询
empDF.join(deptDF,joinExpression).select("ename","dname").show()
// 等价SQL如下:
spark.sql("SELECT ename,dname FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
2.2 FULL OUTER JOIN
empDF.join(deptDF, joinExpression, "outer").show()
spark.sql("SELECT * FROM emp FULL OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.3 LEFT OUTER JOIN
empDF.join(deptDF, joinExpression, "left_outer").show()
spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.4 RIGHT OUTER JOIN
empDF.join(deptDF, joinExpression, "right_outer").show()
spark.sql("SELECT * FROM emp RIGHT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.5 LEFT SEMI JOIN
empDF.join(deptDF, joinExpression, "left_semi").show()
spark.sql("SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno").show()
2.6 LEFT ANTI JOIN
empDF.join(deptDF, joinExpression, "left_anti").show()
spark.sql("SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno").show()
2.7 CROSS JOIN
empDF.join(deptDF, joinExpression, "cross").show()
spark.sql("SELECT * FROM emp CROSS JOIN dept ON emp.deptno = dept.deptno").show()
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
spark.sql("SELECT * FROM emp NATURAL JOIN dept").show()
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的dept列进行连接,其实际等价于:
spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
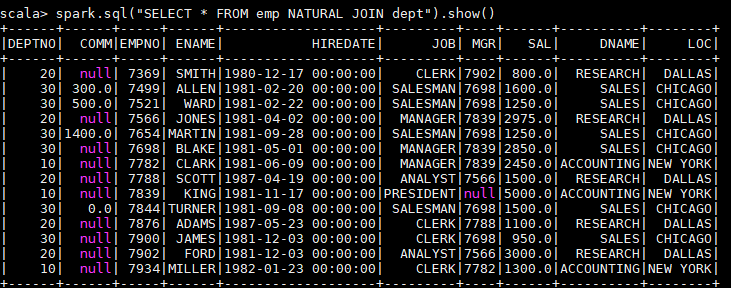
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
在对大表与大表之间进行连接操作时,通常都会触发Shuffle Join,两表的所有分区节点会进行All-to-All的通讯,这种查询通常比较昂贵,会对网络IO会造成比较大的负担。
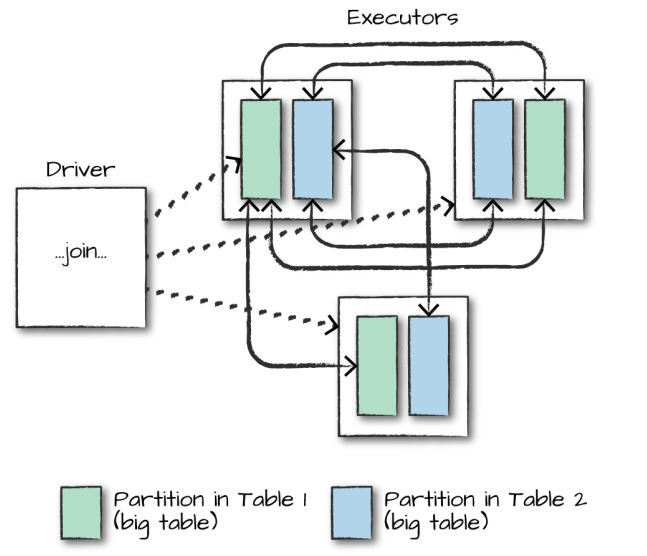
而对于大表和小表的连接操作,Spark会在一定程度上进行优化,如果小表的数据量小于Worker Node的内存空间,Spark会考虑将小表的数据广播到每一个Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的IO,但会加大每个Worker Node的CPU负担。

是否采用广播方式进行Join取决于程序内部对小表的判断,如果想明确使用广播方式进行Join,则可以在DataFrame API 中使用broadcast方法指定需要广播的小表:
empDF.join(broadcast(deptDF), joinExpression).show()
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(十二)—— Spark SQL JOIN操作的更多相关文章
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装
一.下载Spark安装包 1.从官网下载 http://spark.apache.org/downloads.html 2.从微软的镜像站下载 http://mirrors.hust.edu.cn/a ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装[转]
下载Spark安装包 从官网下载 http://spark.apache.org/downloads.html 从微软的镜像站下载 http://mirrors.hust.edu.cn/apache/ ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- Spark学习之路 (二十八)分布式图计算系统
一.引言 在了解GraphX之前,需要先了解关于通用的分布式图计算框架的两个常见问题:图存储模式和图计算模式. 二.图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式.2013年,GraphL ...
- Spark学习之路 (二十)SparkSQL的元数据
一.概述 SparkSQL 的元数据的状态有两种: 1.in_memory,用完了元数据也就丢了 2.hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿. ...
- Spark学习之路 (二十八)分布式图计算系统[转]
引言 在了解GraphX之前,需要先了解关于通用的分布式图计算框架的两个常见问题:图存储模式和图计算模式. 图存储模式 巨型图的存储总体上有边分割和点分割两种存储方式.2013年,GraphLab2. ...
- Spark学习之路 (二十)SparkSQL的元数据[转]
概述 SparkSQL 的元数据的状态有两种: 1.in_memory,用完了元数据也就丢了 2.hive , 通过hive去保存的,也就是说,hive的元数据存在哪儿,它的元数据也就存在哪儿. 换句 ...
- Spark学习之路 (二十七)图简介
一.图 1.1 基本概念 图是由顶点集合(vertex)及顶点间的关系集合(边edge)组成的一种数据结构. 这里的图并非指代数中的图.图可以对事物以及事物之间的关系建模,图可以用来表示自然发生的连接 ...
随机推荐
- numpy 辨异(二) —— np.identity()/np.eye()
import numpy as np; 两者在创建单位矩阵上,并无区别,两者的区别主要在接口上: np.identity(n, dtype=None):只能获取方阵,也即标准意义的单位阵: np.ey ...
- Gradle 1.12 翻译——第九章 Groovy高速入口
由于时间.没办法,做笔记和翻译的同时,大约Gradle用户指南.本博客不再做相关的注意事项.而仅仅翻译和本出版物中未翻译章节. 有关其他章节翻译请注意Github该项目:https://github. ...
- go与java互用的AES实现
终于实现了go与java互用的AES算法实现.基于go可以编译windows与linux下的命令行工具,十分方便. Java源码 import java.security.GeneralSecurit ...
- docker include not found: networks
启动clickhouse的docker镜像时,出现了以下错误 include not found: networks google之后发现是因为可能不支持ipv6导致的解决方法 就是通过设置 /etc ...
- iOS开发之应用首次启动显示用户引导
这个功能的重点就是在如何判断应用是第一次启动的. 其实很简单 我们只需要在一个类里面写好用户引导页面 基本上都是使用UIScrollView 来实现, 新建一个继承于UIViewController ...
- ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程 good
环境:OS X 10.10.5 + JDK 1.8 步骤: 一.下载ELK的三大组件 Elasticsearch下载地址: https://www.elastic.co/downloads/elast ...
- c# Unity依赖注入WebService
1.IOC与DI简介 IOC全称是Inversion Of Control(控制反转),不是一种技术,只是一种思想,一个重要的面相对象编程的法则,它能知道我们如何设计出松耦合,更优良的程序.传统应用程 ...
- wpf 高DPI开发
https://blog.walterlv.com/post/windows-high-dpi-development.html https://blog.csdn.net/ZslLoveMiwa/a ...
- 将QuickReport报表保存为图片(使用TMetaFile和TMetafileCanvas)
//将报表第iPageNo页存为BMP文件 procedure ReportSaveToBMPFile(sFileName :string; iPageNo :integer) ...
- Image Captioning代码复现
Image caption generation: https://github.com/eladhoffer/captionGen Simple encoder-decoder image capt ...