Sqoop 的基本使用
目录
一、Sqoop 基本命令
1. 查看所有命令
# sqoop help
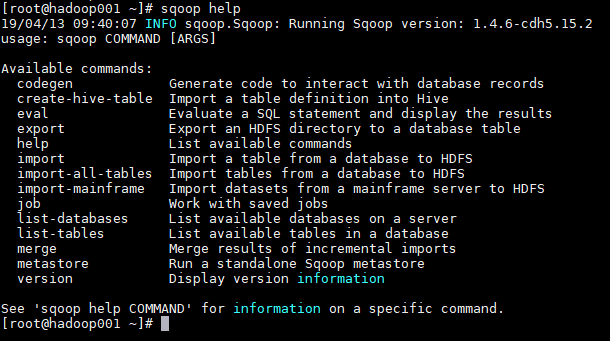
2. 查看某条命令的具体使用方法
# sqoop help 命令名
二、Sqoop 与 MySQL
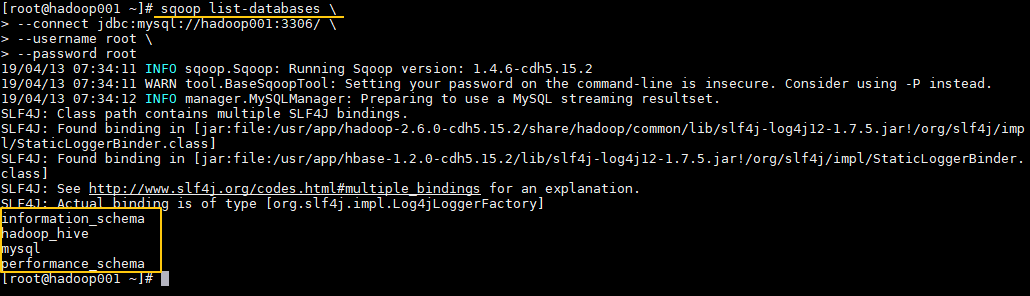
1. 查询MySQL所有数据库
通常用于Sqoop与MySQL连通测试:
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root
2. 查询指定数据库中所有数据表
sqoop list-tables \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root
三、Sqoop 与 HDFS
3.1 MySQL数据导入到HDFS
1. 导入命令
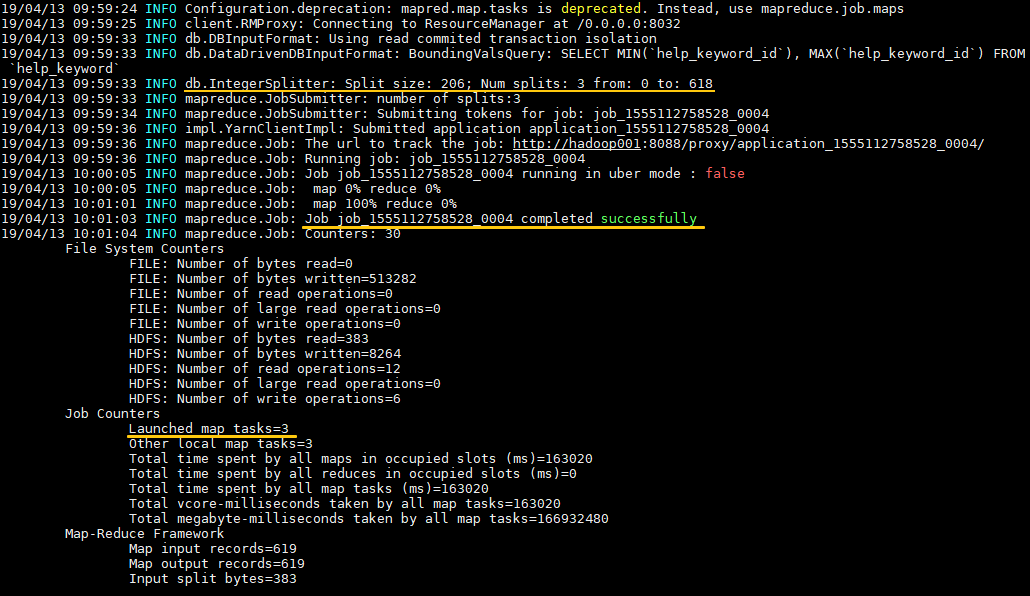
示例:导出MySQL数据库中的help_keyword表到HDFS的/sqoop目录下,如果导入目录存在则先删除再导入,使用3个map tasks并行导入。
注:help_keyword是MySQL内置的一张字典表,之后的示例均使用这张表。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 目标目录存在则先删除
--target-dir /sqoop \ # 导入的目标目录
--fields-terminated-by '\t' \ # 指定导出数据的分隔符
-m 3 # 指定并行执行的map tasks数量
日志输出如下,可以看到输入数据被平均split为三份,分别由三个map task进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
- 添加
-- autoreset-to-one-mapper参数,代表只启动一个map task,即不并行执行; - 若仍希望并行执行,则可以使用
--split-by <column-name>指明拆分数据的参考列。
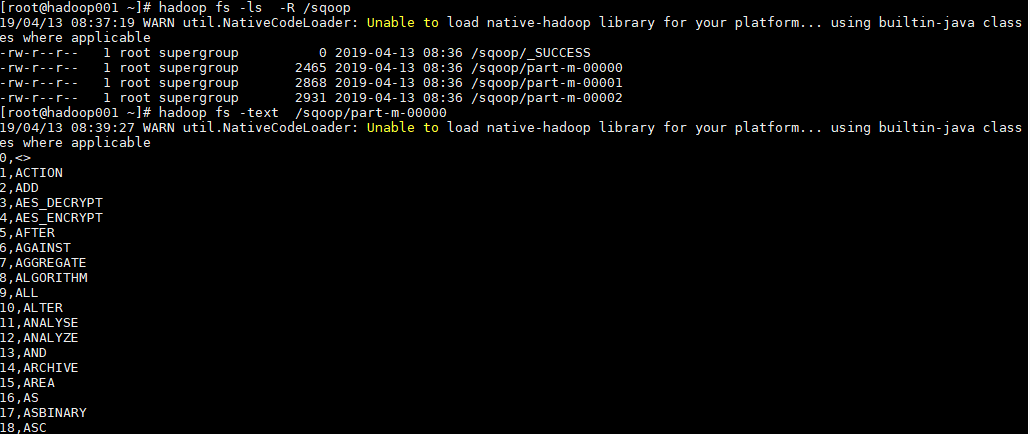
2. 导入验证
# 查看导入后的目录
hadoop fs -ls -R /sqoop
# 查看导入内容
hadoop fs -text /sqoop/part-m-00000
查看HDFS导入目录,可以看到表中数据被分为3部分进行存储,这是由指定的并行度决定的。
3.2 HDFS数据导出到MySQL
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 导出数据存储在MySQL的help_keyword_from_hdf的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3
表必须预先创建,建表语句如下:
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;
四、Sqoop 与 Hive
4.1 MySQL数据导入到Hive
Sqoop导入数据到Hive是通过先将数据导入到HDFS上的临时目录,然后再将数据从HDFS上Load到Hive中,最后将临时目录删除。可以使用target-dir来指定临时目录。
1. 导入命令
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 如果临时目录存在删除
--target-dir /sqoop_hive \ # 临时目录位置
--hive-database sqoop_test \ # 导入到Hive的sqoop_test数据库,数据库需要预先创建。不指定则默认为default库
--hive-import \ # 导入到Hive
--hive-overwrite \ # 如果Hive表中有数据则覆盖,这会清除表中原有的数据,然后再写入
-m 3 # 并行度
导入到Hive中的sqoop_test数据库需要预先创建,不指定则默认使用Hive中的default库。
# 查看hive中的所有数据库
hive> SHOW DATABASES;
# 创建sqoop_test数据库
hive> CREATE DATABASE sqoop_test;
2. 导入验证
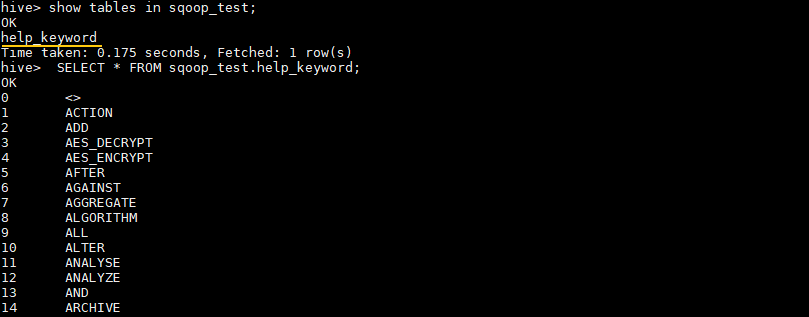
# 查看 sqoop_test 数据库的所有表
hive> SHOW TABLES IN sqoop_test;
# 查看表中数据
hive> SELECT * FROM sqoop_test.help_keyword;
3. 可能出现的问题
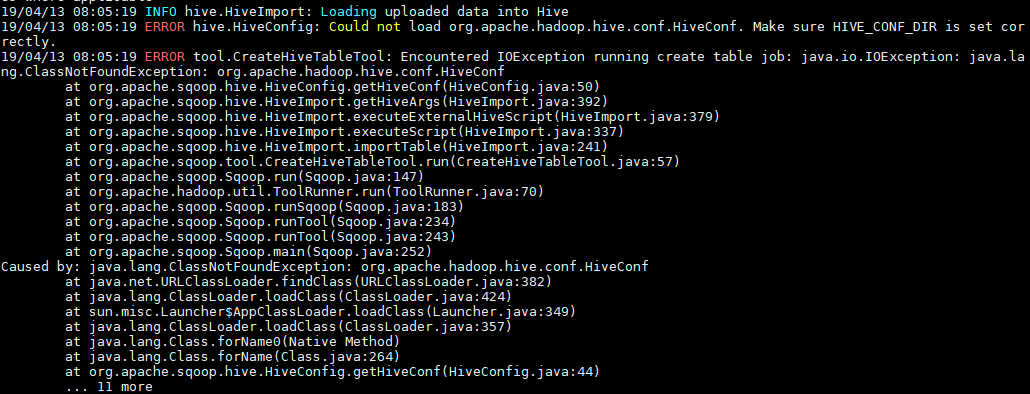
如果执行报错java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,则需将Hive安装目录下lib下的hive-exec-**.jar放到sqoop 的lib 。
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib
4.2 Hive 导出数据到MySQL
由于Hive的数据是存储在HDFS上的,所以Hive导入数据到MySQL,实际上就是HDFS导入数据到MySQL。
1. 查看Hive表在HDFS的存储位置
# 进入对应的数据库
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword;
Location属性为其存储位置:
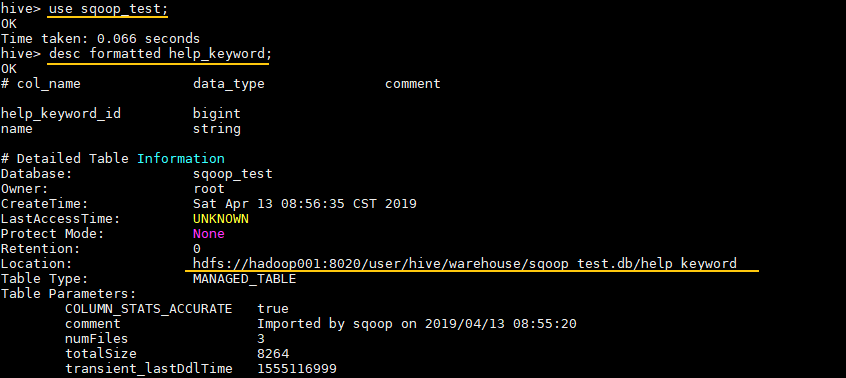
这里可以查看一下这个目录,文件结构如下:

3.2 执行导出命令
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3
MySQL中的表需要预先创建:
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;
五、Sqoop 与 HBase
本小节只讲解从RDBMS导入数据到HBase,因为暂时没有命令能够从HBase直接导出数据到RDBMS。
5.1 MySQL导入数据到HBase
1. 导入数据
将help_keyword表中数据导入到HBase上的 help_keyword_hbase表中,使用原表的主键help_keyword_id作为RowKey,原表的所有列都会在keywordInfo列族下,目前只支持全部导入到一个列族下,不支持分别指定列族。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--hbase-table help_keyword_hbase \ # hbase 表名称,表需要预先创建
--column-family keywordInfo \ # 所有列导入到 keywordInfo 列族下
--hbase-row-key help_keyword_id # 使用原表的help_keyword_id作为RowKey
导入的HBase表需要预先创建:
# 查看所有表
hbase> list
# 创建表
hbase> create 'help_keyword_hbase', 'keywordInfo'
# 查看表信息
hbase> desc 'help_keyword_hbase'
2. 导入验证
使用scan查看表数据:
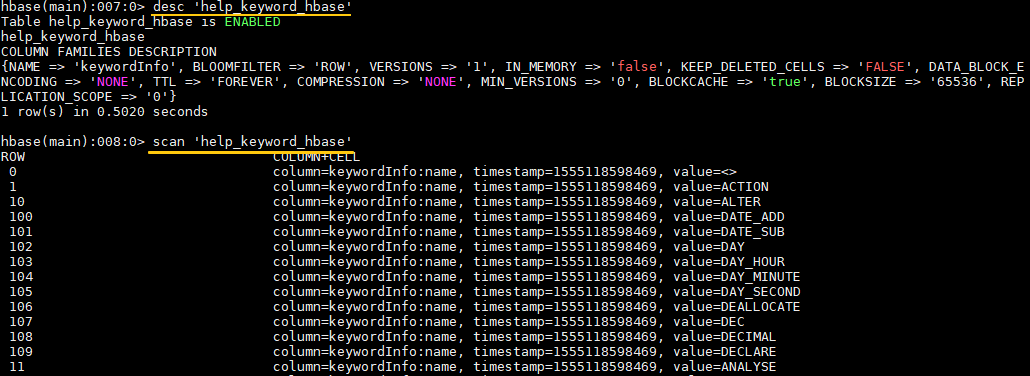
六、全库导出
Sqoop支持通过import-all-tables命令进行全库导出到HDFS/Hive,但需要注意有以下两个限制:
- 所有表必须有主键;或者使用
--autoreset-to-one-mapper,代表只启动一个map task; - 你不能使用非默认的分割列,也不能通过WHERE子句添加任何限制。
第二点解释得比较拗口,这里列出官方原本的说明:
- You must not intend to use non-default splitting column, nor impose any conditions via a
WHEREclause.
全库导出到HDFS:
sqoop import-all-tables \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--warehouse-dir /sqoop_all \ # 每个表会单独导出到一个目录,需要用此参数指明所有目录的父目录
--fields-terminated-by '\t' \
-m 3
全库导出到Hive:
sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--hive-database sqoop_test \ # 导出到Hive对应的库
--hive-import \
--hive-overwrite \
-m 3
七、Sqoop 数据过滤
7.1 query参数
Sqoop支持使用query参数定义查询SQL,从而可以导出任何想要的结果集。使用示例如下:
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \
--delete-target-dir \
--target-dir /sqoop_hive \
--hive-database sqoop_test \ # 指定导入目标数据库 不指定则默认使用Hive中的default库
--hive-table filter_help_keyword \ # 指定导入目标表
--split-by help_keyword_id \ # 指定用于split的列
--hive-import \ # 导入到Hive
--hive-overwrite \ 、
-m 3
在使用query进行数据过滤时,需要注意以下三点:
必须用
--hive-table指明目标表;如果并行度
-m不为1或者没有指定--autoreset-to-one-mapper,则需要用--split-by指明参考列;SQL的
where字句必须包含$CONDITIONS,这是固定写法,作用是动态替换。
7.2 增量导入
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /sqoop_hive \
--hive-database sqoop_test \
--incremental append \ # 指明模式
--check-column help_keyword_id \ # 指明用于增量导入的参考列
--last-value 300 \ # 指定参考列上次导入的最大值
--hive-import \
-m 3
incremental参数有以下两个可选的选项:
- append:要求参考列的值必须是递增的,所有大于
last-value的值都会被导入; - lastmodified:要求参考列的值必须是
timestamp类型,且插入数据时候要在参考列插入当前时间戳,更新数据时也要更新参考列的时间戳,所有时间晚于last-value的数据都会被导入。
通过上面的解释我们可以看出来,其实Sqoop的增量导入并没有太多神器的地方,就是依靠维护的参考列来判断哪些是增量数据。当然我们也可以使用上面介绍的query参数来进行手动的增量导出,这样反而更加灵活。
八、类型支持
Sqoop默认支持数据库的大多数字段类型,但是某些特殊类型是不支持的。遇到不支持的类型,程序会抛出异常Hive does not support the SQL type for column xxx异常,此时可以通过下面两个参数进行强制类型转换:
- –map-column-java<mapping> :重写SQL到Java类型的映射;
- –map-column-hive <mapping> : 重写Hive到Java类型的映射。
示例如下,将原先id字段强制转为String类型,value字段强制转为Integer类型:
$ sqoop import ... --map-column-java id=String,value=Integer
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Sqoop 的基本使用的更多相关文章
- sqoop:Failed to download file from http://hdp01:8080/resources//oracle-jdbc-driver.jar due to HTTP error: HTTP Error 404: Not Found
环境:ambari2.3,centos7,sqoop1.4.6 问题描述:通过ambari安装了sqoop,又添加了oracle驱动配置,如下: 保存配置后,重启sqoop报错:http://hdp0 ...
- 安装sqoop
安装sqoop 1.默认已经安装好java+hadoop 2.下载对应hadoop版本的sqoop版本 3.解压安装包 tar zxvf sqoop-1.4.6.bin__hadoop-2.0.4-a ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Oozie分布式任务的工作流——Sqoop篇
Sqoop的使用应该是Oozie里面最常用的了,因为很多BI数据分析都是基于业务数据库来做的,因此需要把mysql或者oracle的数据导入到hdfs中再利用mapreduce或者spark进行ETL ...
- [大数据之Sqoop] —— Sqoop初探
Sqoop是一款用于把关系型数据库中的数据导入到hdfs中或者hive中的工具,当然也支持把数据从hdfs或者hive导入到关系型数据库中. Sqoop也是基于Mapreduce来做的数据导入. 关于 ...
- [大数据之Sqoop] —— 什么是Sqoop?
介绍 sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具.你可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中:也可以把数据从hdfs中导出到关系型数据 ...
- Sqoop切分数据的思想概况
Sqoop通过--split-by指定切分的字段,--m设置mapper的数量.通过这两个参数分解生成m个where子句,进行分段查询.因此sqoop的split可以理解为where子句的切分. 第一 ...
- sqoop数据导出导入命令
1. 将mysql中的数据导入到hive中 sqoop import --connect jdbc:mysql://localhost:3306/sqoop --direct --username r ...
- Apache Sqoop - Overview——Sqoop 概述
Apache Sqoop - Overview Apache Sqoop 概述 使用Hadoop来分析和处理数据需要将数据加载到集群中并且将它和企业生产数据库中的其他数据进行结合处理.从生产系统加载大 ...
- sqoop使用中的小问题
1.数据库连接异常 执行数据导出 sqoop export --connect jdbc:mysql://192.168.208.129:3306/test --username hive --P - ...
随机推荐
- Poco logger 日志使用小析
Poco logger 日志使用小析 Poco logger 日志使用小析 日志 logger 库选择 Pocologger 架构简析 步骤一 生成消息 步骤二 写入logger 步骤三 导入chan ...
- moost — Last.fm's collection of C++ utility libraries(功能很多)
libmoost libmoost is a collection of C++ utility libraries, including: algorithms (set intersection, ...
- python_matplotlib cannot import name _thread on mac
最后的2行错误信息是 from six.moves import _thread ImportError: cannot import name _thread 1 2 发现是six出现了问题,用pi ...
- cocos2d-x 3.2 它 2048 —— 第三
***************************************转载请注明出处:http://blog.csdn.net/lttree************************** ...
- Spring框架:Spring安全
在传统的Web发展,安全码被分散在各个模块,这样方便管理,有时你可能会错过一个地方导致安全漏洞.为了解决这个问题,它的发明Spring Security.它是业务逻辑的有关安全代码的作用全部转移到一个 ...
- sql like N'%...%' 在C#里的写法
StringBuilder sb = new StringBuilder(); List<SqlParameter> parameters =new List<SqlParamete ...
- WPF BorderBrush BorderThickness
基本上所有的控件都可以设置BorderBrush BorderThickness 例如TextBox,Button
- 通通玩blend美工(2)——时钟
原文:通通玩blend美工(2)--时钟 谢谢大家对我上一篇Blend的支持:通通玩blend美工(1)——荧光Button 再接再厉再来一篇~~! 这篇是建立在已经看得懂上一篇为基础来写的,有些细节 ...
- 一步一步造个IoC轮子(三):构造基本的IoC容器
一步一步造个Ioc轮子目录 一步一步造个IoC轮子(一):Ioc是什么 一步一步造个IoC轮子(二):详解泛型工厂 一步一步造个IoC轮子(三):构造基本的IoC容器 定义容器 首先,我们来画个大饼, ...
- Android Camera2 拍照入门学习
原文:Android Camera2 拍照入门学习 学习资料: 肾虚将军android camera2 详解说明 极客学院android.hardware.camera2 使用指南 Android 5 ...