centos6.8下hadoop3.1.1完全分布式安装指南
前述:这篇文档是建立在三台虚拟机相互ping通,防火墙关闭,hosts文件修改,SSH 免密码登录,主机名修改等的基础上开始的。
一.传入文件
1.创建安装目录
mkdir /usr/local/soft

2.打开xftp,找到对应目录,将所需安装包传入进去

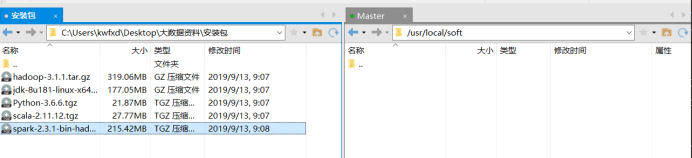

查看安装包:cd /usr/local/soft

二.安装JAVA
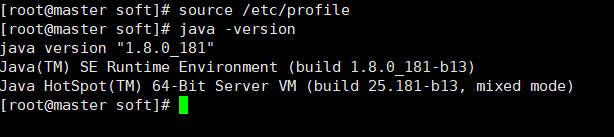
1.查看是否已安装jdk: java -version

2.未安装,解压java安装包: tar -zxvf jdk-8u181-linux-x64.tar.gz
(每个人安装包可能不一样,自己参考)


3.给jdk重命名,并查看当前位置:mv jdk1.8.0_181 java

4.配置jdk环境:vim /etc/profile.d/jdk.sh


export JAVA_HOME=/usr/local/soft/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/rt.jar
5.更新环境变量并检验:source /etc/profile
三.安装Hadoop
1.解压hadoop安装包:tar -zxvf hadoop-3.1.1.tar.gz

2.查看并重命名:mv hadoop-3.1.1 hadoop

3.配置 hadoop 配置文件
3.1修改 core-site.xml 配置文件:vim hadoop/etc/hadoop/core-site.xml

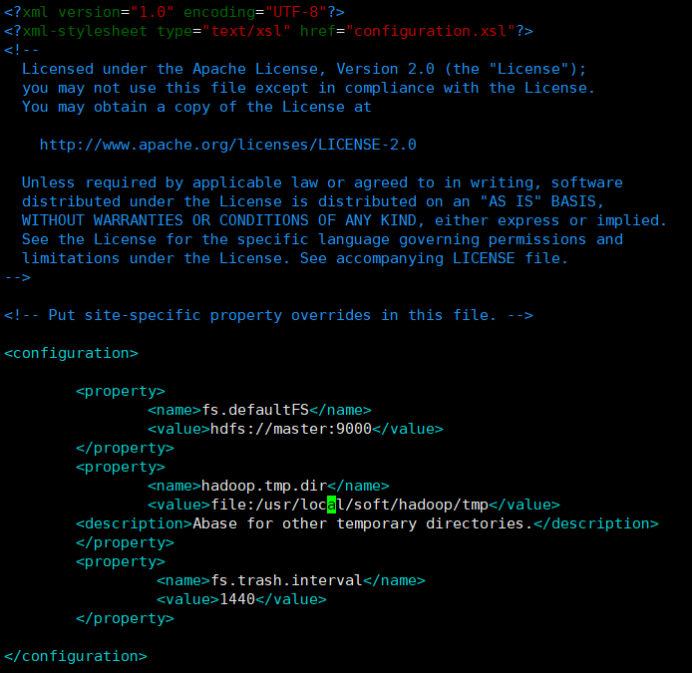
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/soft/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3.2修改 hdfs-site.xml 配置文件:vim hadoop/etc/hadoop/hdfs-site.xml
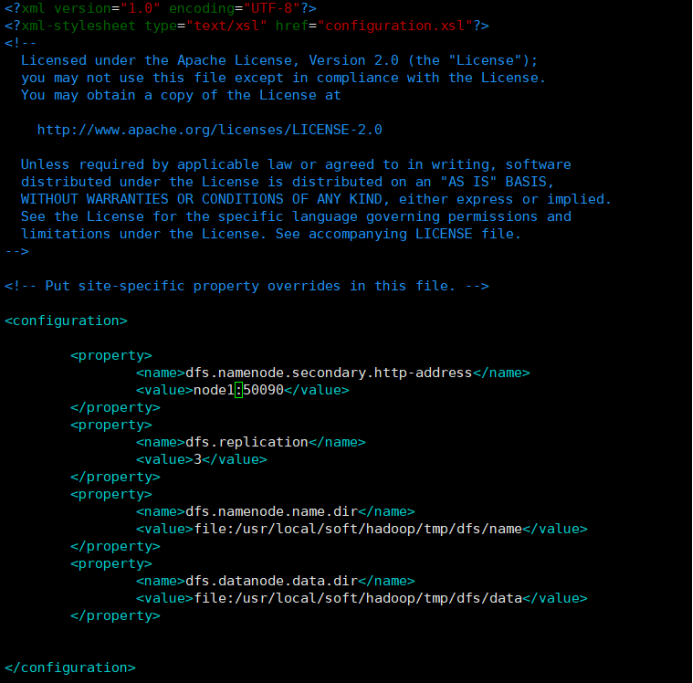
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/soft/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/soft/hadoop/tmp/dfs/data</value>
</property>
3.3修改 workers 配置文件:vim hadoop/etc/hadoop/workers

3.4修改hadoop-env.sh文件:vim hadoop/etc/hadoop/hadoop-env.sh
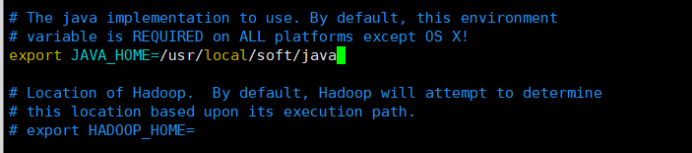
export JAVA_HOME=/usr/local/soft/java
3.5修改yarn-site.xml文件:vim hadoop/etc/hadoop/yarn-site.xml
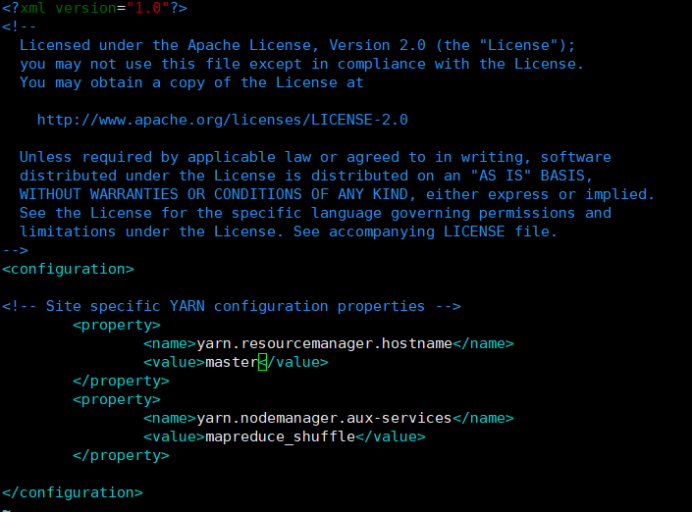
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.6更新配置文件:source hadoop/etc/hadoop/hadoop-env.sh

3.7修改 start-dfs.sh配置文件: im hadoop/sbin/start-dfs.sh


export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.8修改 stop-dfs.sh配置文件: vim hadoop/sbin/stop-dfs.sh

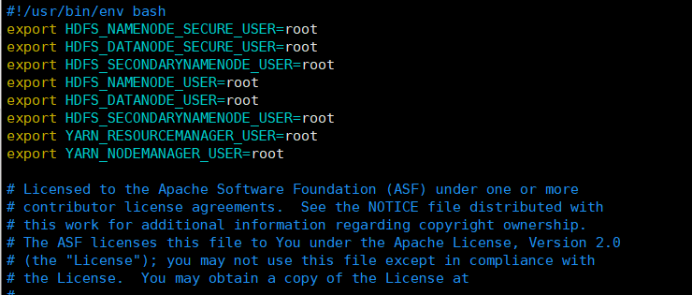
export HDFS_NAMENODE_SECURE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
3.9修改 start-yarn.sh配置文件:vim hadoop/sbin/start-yarn.sh

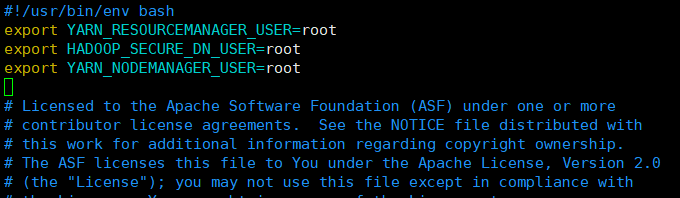
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
3.10修改 stop-yarn.sh配置文件:vim hadoop/sbin/stop-yarn.sh

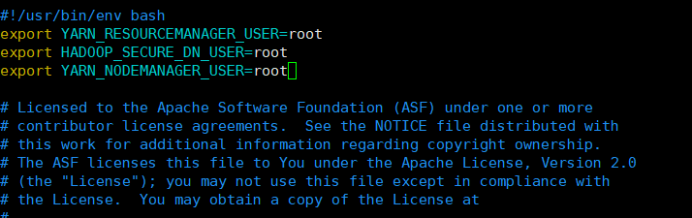
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=root
export YARN_NODEMANAGER_USER=root
3.11 取消打印警告信息:vim hadoop/etc/hadoop/log4j.properties
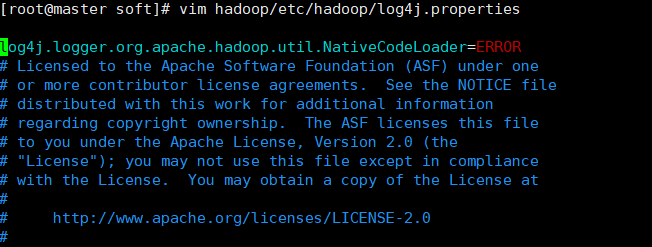
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
四.同步配置信息:
1.同步node1:scp -r soft root@node1:/usr/local/

同步node2:scp -r soft root@node2:/usr/local/

2.等待所有传输完成,配置profile文件:vim /etc/profile.d/hadoop.sh

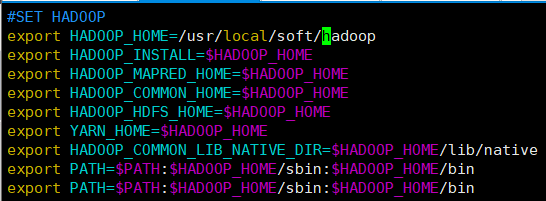
#SET HADOOP
export HADOOP_HOME=/usr/local/soft/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
3.继续传输
对node1: scp /etc/profile.d/jdk.sh root@node1:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@node1:/etc/profile.d/

对node2: scp /etc/profile.d/jdk.sh root@node2:/etc/profile.d/
scp /etc/profile.d/hadoop.sh root@node2:/etc/profile.d/

4.在三台虚拟机上都要执行
source /etc/profile
source /usr/local/soft/hadoop/etc/hadoop/hadoop-env.sh

(只显示一台)
5.格式化 HDFS 文件系统:hdfs namenode -format(只在master上)

五.启动集群
cd /usr/local/soft/hadoop/sbin/
./start-all.sh

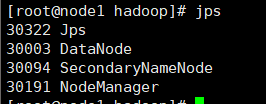
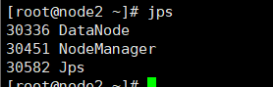
启动后在三台虚拟机上分别输入jps
结果如下:

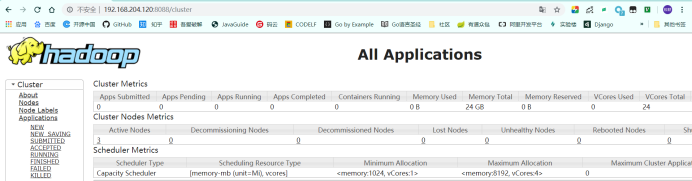
windows下谷歌浏览器检验:
http://192.168.204.120:8088/cluster(输入自己的master的ip地址)
Hadoop测试(MapReduce 执行计算测试):


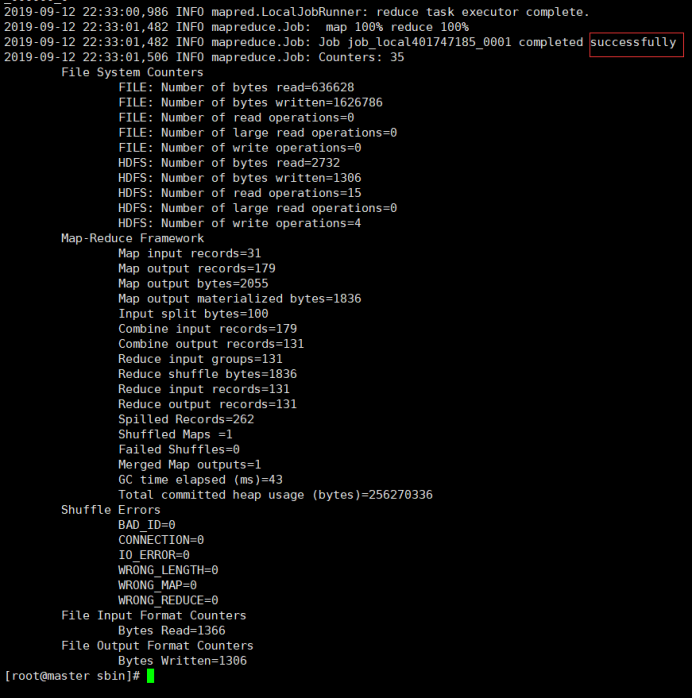
hadoop jar /usr/local/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /input /output

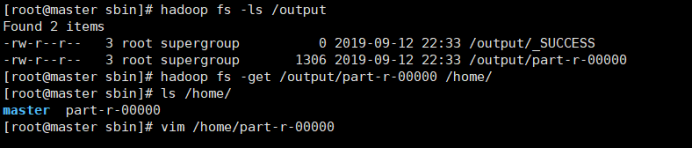
查看运行结果:
以上hadoop配置完成。
centos6.8下hadoop3.1.1完全分布式安装指南的更多相关文章
- 伪分布式下Hadoop3.2版本打不开localhost:50070,可以打开localhost:8088
一.问题描述 伪分布式下Hadoop3.2版本打不开localhost:50070,可以打开localhost:8088 二.解决办法 Hadoop3.2版本namenode的默认端口配置已经更改为9 ...
- Centos6.9下RabbitMQ集群部署记录
之前简单介绍了CentOS下单机部署RabbltMQ环境的操作记录,下面详细说下RabbitMQ集群知识,RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言, ...
- 大数据学习笔记【一】:Hadoop-3.1.2完全分布式环境搭建(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3 ...
- 【转载】CentOS6.5_X64下安装配置MongoDB数据库
[转载]CentOS6.5_X64下安装配置MongoDB数据库 2014-05-16 10:07:09| 分类: 默认分类|举报|字号 订阅 下载LOFTER客户端 本文转载自zhm&l ...
- CentOS6.8下部署Zabbix3.0
Centos6.8下部署安装zabbix3.0: 环境要求 PHP >= 5.4 (CentOS6默认为5.3.3,需要更新) curl >= 7.20 (如需支持SMTP认证,需更新) ...
- CentOS6.5下安装apache2.2和PHP 5.5.28
CentOS6.5下安装apache2.2 1. 准备程序 :httpd-2.2.27.tar.gz 下载地址:http://httpd.apache.org/download.cgi#apache2 ...
- [转] Linux学习之CentOS(十三)--CentOS6.4下Mysql数据库的安装与配置
from: http://www.cnblogs.com/xiaoluo501395377/archive/2013/04/07/3003278.html 如果要在Linux上做j2ee开发,首先得 ...
- CentOS6.5下安装配置MySQL
CentOS6.5下安装配置MySQL,配置方法如下: 安装mysql数据库:# yum install -y mysql-server mysql mysql-deve 查看mysql-server ...
- centos6.7下编译安装lnmp
很多步骤不说明了,请参照本人的centos6.7下编译安装lamp,这次的架构是nginx+php-fpm一台服务器,mysql一台服务器 (1)首先编译安装nginx: 操作命令: yum -y g ...
随机推荐
- [Go] gocron源码阅读-groutine与channel应用到信号捕获
直接使用go 函数名()可以开启一个grountine,channel可以接收信息并且如果没有数据时会阻塞住channel对应的是底层数据结构的引用,复制channel和函数传参都是拷贝的引用make ...
- (六)Amazon Lightsail 部署LAMP应用程序之升级到Amazon EC2
升级到Amazon EC2 将Amazon Lightsail实例升级为Amazon EC2 您将进行以下操作: ①创建使用 Amazon RDS的Web前端实例的快照 ②将该快照导出到 Amazon ...
- 在Rust中使用C语言的库功能
主要是了解unsafe{}语法块的作用. #[repr(C)] #[derive(Copy, Clone)] #[derive(Debug)] struct Complex { re: f32, im ...
- monkey和monkeyrunner的区别
简单来说: 1.monkey是在设备或模拟器直接运行adb shell命令生成随机事件来进行测试 2.monkeyrunner是通过API发送特定的命令和事件来控制设备 为了支持黑盒自动化测试的场景, ...
- CF915E Physical Education Lessons 珂朵莉树
问题描述 CF915E LG-CF915E 题解 \(n \le 10^9\) 看上去非常唬人. 但是这种区间操作的题,珂朵莉树随便跑啊. \(\mathrm{Code}\) #include< ...
- 设计模式-Builder模式(创建型模式)
//以下代码来源: 设计模式精解-GoF 23种设计模式解析附C++实现源码 //Product.h #pragma once class Product { public: Product(); ~ ...
- 记 2019蓝桥杯校内预选赛(JAVA组) 赛后总结
引言 好像博客好久没更新了 哈哈哈哈哈 趁现在有空更新一波 不知道还有没有人看 确实该记录一下每天做了什么了 不然感觉有些浑浑噩噩了 比赛介绍 全称: 蓝桥杯全国软件和信息技术专业人才大赛 蓝桥杯 实 ...
- Codeforces Round #554 (Div. 2) D 贪心 + 记忆化搜索
https://codeforces.com/contest/1152/problem/D 题意 给你一个n代表合法括号序列的长度一半,一颗有所有合法括号序列构成的字典树上,选择最大的边集,边集的边没 ...
- 小米笔记本pro 黑苹果系统无法进入系统,频繁重启故障解决记录
问题1:频繁重启,然后clover丢失 表现情况:开机没有选择macos 或windos的界面 解决办法:进入windows使用工具easyefi,直接添加一个clover start boot,选择 ...
- java.sql.SQLException: Could not establish connection to 192.168.8.111:10000/default: java.net.ConnectException: Connection refused: connect at org.apache.hadoop.hive.jdbc.HiveConnection.<init>(HiveC
java.sql.SQLException: Could not establish connection to 192.168.8.111:10000/default: java.net.Conne ...