分布式全局唯一ID生成策略
一、背景
分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表。因为数据量巨大一张表无法承接,就会对其进行分库分表。
但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题。
1.1 唯一ID的特性
- 整个系统
ID唯一; - ID是数字类型,而且是趋势递增;
- ID简短,查询效率快。
1.2 递增与趋势递增
| 递增 | 趋势递增 |
|---|---|
| 第一次生成的ID为12,下一次生成的ID是13,再下一次生成的ID是14。 | 什么是?如:在一段时间内,生成的ID是递增的趋势。如:再一段时间内生成的ID在【0,1000】之间,过段时间生成的ID在【1000,2000】之间。但在【0-1000】区间内的时候,ID生成有可能第一次是12,第二次是10,第三次是14。 |
二、方案
2.1 UUID
UUID全称:Universally Unique Identifier。标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:9628f6e9-70ca-45aa-9f7c-77afe0d26e05。
- 优点:
- 代码实现简单;
- 本机生成,没有性能问题;
- 因为是全球唯一的
ID,所以迁移数据容易。
- 缺点:
- 每次生成的
ID是无序的,无法保证趋势递增; UUID的字符串存储,查询效率慢;- 存储空间大;
ID本身无业务含义,不可读。
- 应用场景:
- 类似生成token令牌的场景;
- 不适用一些要求有趋势递增的ID场景,不适合作为高性能需求的场景下的数据库主键。
也有在线生成
UUID的网站,如果你的项目上用到了UUID,可以用来生成临时的测试数据。https://www.uuidgenerator.net/
2.2 MySQL主键自增
利用了MySQL的主键自增auto_increment,默认每次ID加1。
优点:
- 数字化,
ID递增; - 查询效率高;
- 具有一定的业务可读。
- 缺点:
- 存在单点问题,如果
MySQL挂了,就没法生成ID了; - 数据库压力大,高并发抗不住。
2.3 MySQL多实例主键自增
这个方案就是解决MySQL 的单点问题,在auto_increment基本上面,设置step步长

如上,每台的初始值分别为1,2,3...N,步长为N(这个案例步长为4)
- 优点:解决了单点问题;
- 缺点:一旦把步长定好后,就无法扩容;而且单个数据库的压力大,数据库自身性能无法满足高并发。
- 应用场景:数据不需要扩容的场景。
2.4 基于Redis实现
单机:
Redis的incr函数在单机上是原子操作,可以保证唯一且递增。集群:单机
Redis可能无法支撑高并发。集群情况下,可以使用步长的方式。比如有5个Redis节点组成的集群,它们生成的ID分别为:
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25
- 优点:有序递增,可读性强。
- 缺点:占用带宽,每次要向
Redis进行请求。
三、优化方案
3.1、改造数据库主键自增
数据库的自增主键的特性,可以实现分布式ID,适合做userId,正好符合如何永不迁移数据和避免热点? 但这个方案有严重的问题:
- 一旦步长定下来,不容易扩容;
- 数据库压力山大。
- 为什么压力大?
因为我们每次获取ID的时候,都要去数据库请求一次。那我们可以不可以不要每次去取?
可以请求数据库得到ID的时候,可设计成获得的ID是一个ID区间段。
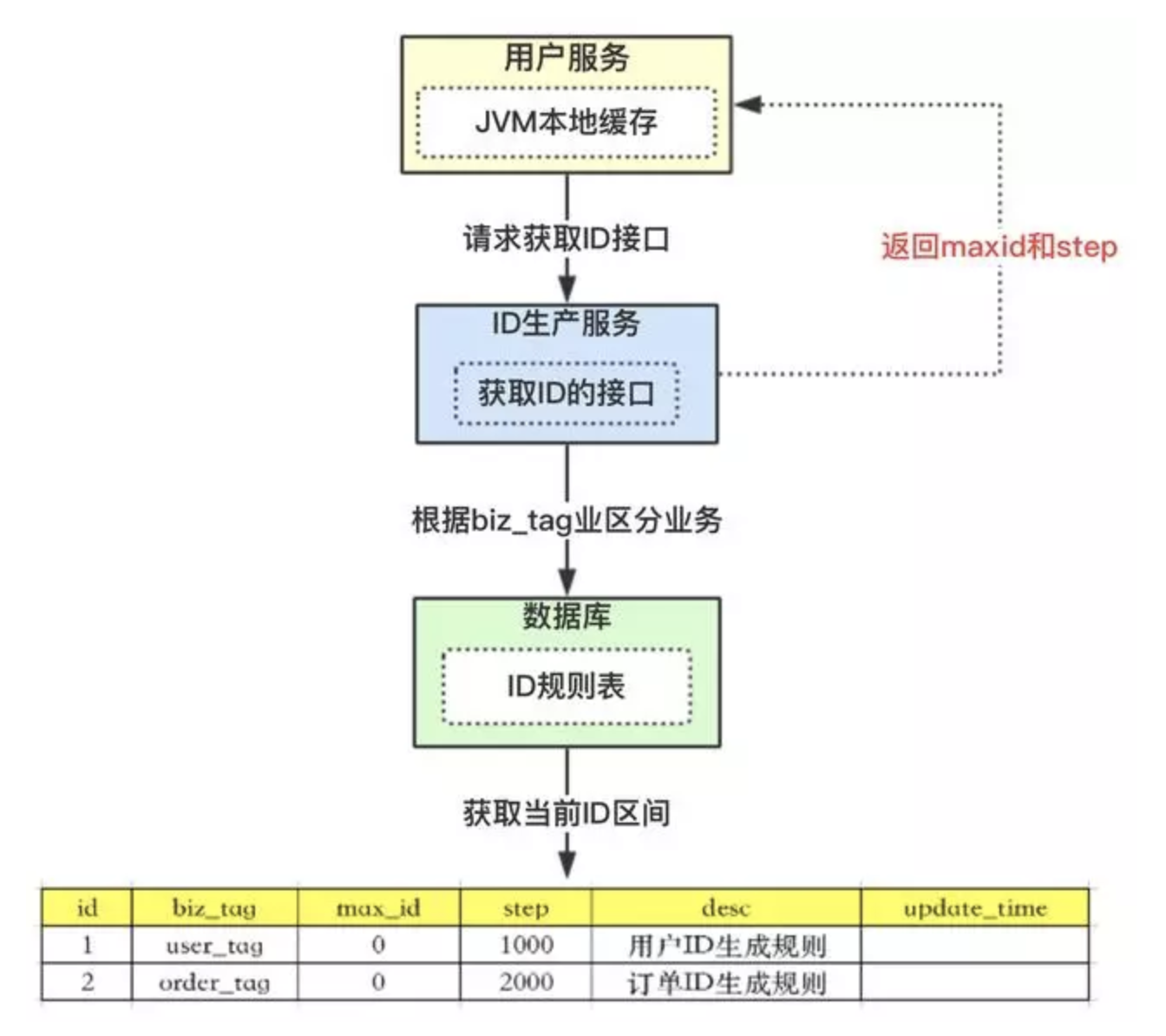
- 上图
ID规则表含义:
id表示为主键,无业务含义;biz_tag为了表示业务,因为整体系统中会有很多业务需要生成ID,这样可以共用一张表维护;max_id表示现在整体系统中已经分配的最大ID;desc描述;update_time表示每次取的ID时间;
- 整体流程:
【用户服务】在注册一个用户时,需要一个用户
ID;会请求【生成ID服务(是独立的应用)】的接口;【生成
ID服务】会去查询数据库,找到user_tag的id,现在的max_id为0,step=1000;【生成
ID服务】把max_id和step返回给【用户服务】;并且把max_id更新为max_id = max_id + step,即更新为1000;【用户服务】获得
max_id=0,step=1000;这个用户服务可以用
ID=【max_id + 1,max_id+step】区间的ID,即为【1,1000】;【用户服务】会把这个区间保存到
jvm中;【用户服务】需要用到
ID的时候,在区间【1,1000】中依次获取ID,可采用AtomicLong中的getAndIncrement方法;如果把区间的值用完了,再去请求【生产
ID服务】接口,获取到max_id为1000,即可以用【max_id + 1,max_id+step】区间的ID,即为【1001,2000】。该方案就非常完美的解决了数据库自增的问题,而且可以自行定义
max_id的起点,和step步长,非常方便扩容;也解决了数据库压力的问题,因为在一段区间内,是在
jvm内存中获取的,而不需要每次请求数据库。即使数据库宕机了,系统也不受影响,ID还能维持一段时间。
3.2 竞争问题
以上方案中,如果是多个用户服务,同时获取ID,同时去请求【ID服务】,在获取max_id的时候会存在并发问题。如:
用户服务
A,取到的max_id=1000;用户服务B取到的也是max_id=1000,那就出现了问题,ID重复了。
解决方案是:加分布式锁,保证同一时刻只有一个用户服务获取max_id。
3.3 突发阻塞问题
因为竞争问题,所有只有一个用户服务去操作数据库,其他二个会被阻塞。出现的现象就是一会儿突然系统耗时变长,怎么去解决?
- 双
buffer方案
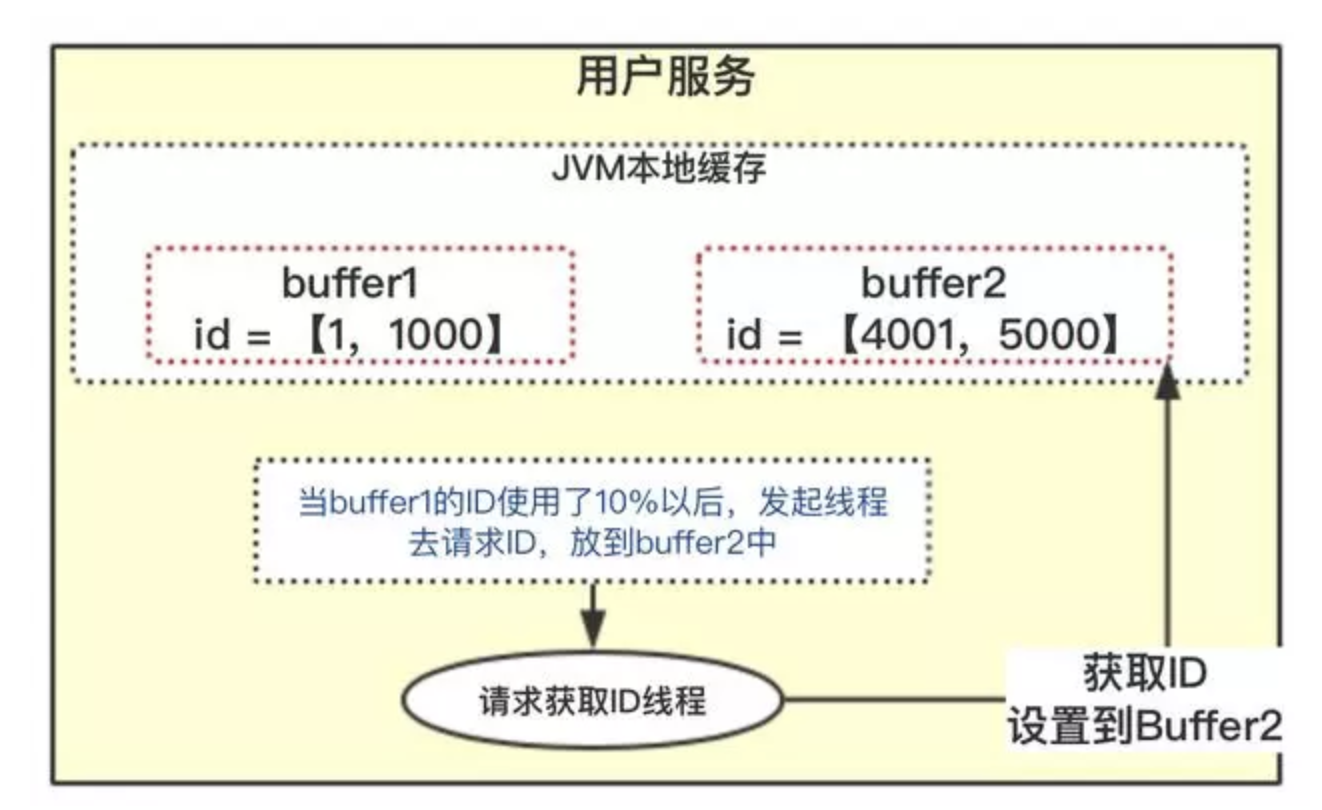
流程如下:
- 当前获取
ID在buffer1中,每次获取ID在buffer1中获取; - 当
buffer1中的ID已经使用到了100,也就是达到区间的10%; - 达到了
10%,先判断buffer2中有没有去获取过,如果没有就立即发起请求获取ID线程,此线程把获取到的ID,设置到buffer2中; - 如果
buffer1用完了,会自动切换到buffer2; buffer2用到10%了,也会启动线程再次获取,设置到buffer1中;- 依次往返。
3.4 总结
- 双
buffer的方案就达到了业务场景用的ID,都是在jvm内存中获得的,从此不需要到数据库中获取了,数据库宕机时长长点儿也没太大影响了。 - 因为会有一个线程,会观察什么时候去自动获取。两个
buffer之间自行切换使用,就解决了突发阻塞的问题。
四、其他方式
还有一些其他的ID生成方案,比如:
- 滴滴:时间+起点编号+车牌号;
- 淘宝订单:时间戳+用户
ID - 其他电商:时间戳+下单渠道+用户
ID,有的会加上订单第一个商品的ID; MongoDB的ID:通过时间+机器码+pid+inc共12个字节,4+3+2+3的方式最终标识成一个24长度的十六进制字符。
分布式全局唯一ID生成策略的更多相关文章
- 分布式全局唯一ID生成策略
为什么分布式系统需要用到ID生成系统 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据库的分库分表后需要有 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- (4.24)【mysql、sql server】分布式全局唯一ID生成方案
参考:分布式全局唯一ID生成方案:https://blog.csdn.net/linzhiqiang0316/article/details/80425437 分表生成唯一ID方案 sql serve ...
- 分布式全局唯一ID的实现
分布式全局唯一ID的实现 前言 上周末考完试,这周正好把工作整理整理,然后也把之前的一些素材,整理一番,也当自己再学习一番. 一方面正好最近看到几篇这方面的文章,另一方面也是正好工作上有所涉及,所以决 ...
- 框架篇:分布式全局唯一ID
前言 每一次HTTP请求,数据库的事务的执行,我们追踪代码执行的过程中,需要一个唯一值和这些业务操作相关联,对于单机的系统,可以用数据库的自增ID或者时间戳加一个在本机递增值,即可实现唯一值.但在分布 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
- 分布式全局唯一ID与自增序列
包含时间顺序的ID 此场景最简单的实现方案,就是采用 twitter 的 Snowflake 算法.ID总长64位,第1位不可用,41位表示时间戳,10位表示生成机器的id,后12位表示序列号. 为什 ...
- 关于全局唯一ID生成方法
引:最近业务开发过程中需要涉及到全局唯一ID生成.之前零零总总的收集过一些相关资料,特此整理以便后用 本博客已经迁移至:http://cenalulu.github.io/ 本篇博文已经迁移,阅读全文 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
随机推荐
- SX1276/SX1278和SXSX1262的详细参数对比
SX1276/SX1278和SX1262的对比 SX1262是Semtech公司新推出的一款sub-GHz无线收发器.SX1262芯片最大的买点是它的低功耗和超远距离的传输.SX1262接收电流 ...
- Ceph分布式存储-总
Ceph分布式存储-总 目录: Ceph基本组成及原理 Ceph之块存储 Ceph之文件存储 Ceph之对象存储 Ceph之实际应用 Ceph之总结 一.Ceph基本组成及原理 1.块存储.文件存储. ...
- redis(6)--redis集群之分片机制(redis-cluster)
Redis-Cluster 即使是使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶效应.而因为Redis是基于内存 ...
- Java做成Zip文件,Java实现压缩文件
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import ...
- HTTP响应的结构是怎么样的?
HTTP响应由三个部分组成:状态码(Status Code):描述了响应的状态.可以用来检查是否成功的完成了请求.请求失败的情况下,状态码可用来找出失败的原因.如果Servlet没有返回状态码,默认会 ...
- Linux系统基础知识
文件类型属性 '-'代表普通文件 'd'代表目录文件 'l'代表链接文件link 'b'代表块文件block 'c'代表字符设备文件 'p'代表管道文件
- 学习构建调试Linux内核网络代码的环境MenuOS系统
构建调试Linux内核网络代码的环境MenuOS系统 一.前言 这是网络程序设计的第三次实验,主要是学习自己编译linux内核,构建一个具有简易功能的操作系统,同时在系统上面进行调试linux内核网络 ...
- Vue项目无法使用局域网IP直接访问的配置方法
一般使用 vue-cli 下来的项目是可以直接访问局域网 IP 打开的,比如 192.168.1.11:8080 .但是最近公司的一个项目只可以通过 localhost 访问. 需要配置一下,才可直接 ...
- 《Java基础知识》Java类的定义及其实例化
类必须先定义才能使用.类是创建对象的模板,创建对象也叫类的实例化. 下面通过一个简单的例子来理解Java中类的定义: public class Dog { String name; int age; ...
- 原创 Hive left join 技巧总结
根据工作中经验总结出来 left join 常用的 使用注意点: A Left join B on A.id = B.id 第一种情况: 如果 A 表 ...