DAGScheduler stage 划分算法
DAGScheduler stage 划分算法
stage划分算法很重要,对于spark开发人员来说,必须对stage划分算法很清晰,知道自己编写的spark Application被划分成了几个job,每个job被划分成了几个stage,每个stage包括哪些代码,这样当发现哪个stage报错或者执行特别慢,才能针对对应代码排查问题和性能调优
stage 划分思想:
由submitStage() 和getMissingParentStage() 组成
会从触发Action操作的那个RDD开始往前,首先为最后一个RDD创建一个stage,然后在往前,如果遇到某个RDD是宽依赖,就会为宽依赖创建一个新的stage,新的RDD就是最新的stage的最后一个RDD,然后以依次类推,继续往前,根据宽依赖或者窄依赖进行stage划分,知直到最后一个RDD遍历完为止
stage划分步骤:
1、使用出发job的最后一个RDD,创建finalStage(创建一个stage对象,并且将stage加入到DAGScheduler内部的内存缓存中)
2、使用finalStage创建一个job(这个job的最后一个stage,就是 finalStage)
3、将job加入到内存缓存中
4、使用 submitStage() 提交 finalStage
提交stage的方法(stage划分算法入口):
调用 getMissingParentStage() 获取当前这个 stage 的父 stage:
往栈中推入stage的最后一个RDD
while循环对stage的最后一个RDD,调用自己定义的visit()方法
visit():如果是窄依赖,将RDD放入栈中,如果是宽依赖,使用宽依赖的那个RDD创建一个stage,将isShuffleMap设为true
提交stage,为stage创建一批task,task数量与Partition数量相同
计算每个task对应的Partition的最佳位置(就是从stage最后一个RDD开始,去找被cache或checkpoint的RDD的Partition,task的最佳位置,就是该Partition的位置,这样task就在那个节点上执行,不需要计算之前的RDD;如果从最后一个RDD到最开始的RDD,都没有被cache或checkpoint,那么最佳位置就是Nil,就是没有最佳位置)
5.、针对stage的task,创建TaskSet对象,调用TaskScheduler的submitTask方法,提交TaskSet,提交到Excutor上去执行
总结如下:
1、从finalstage倒推,
2、通过宽依赖进行新的stage划分
3、使用递归,优先提交父stage
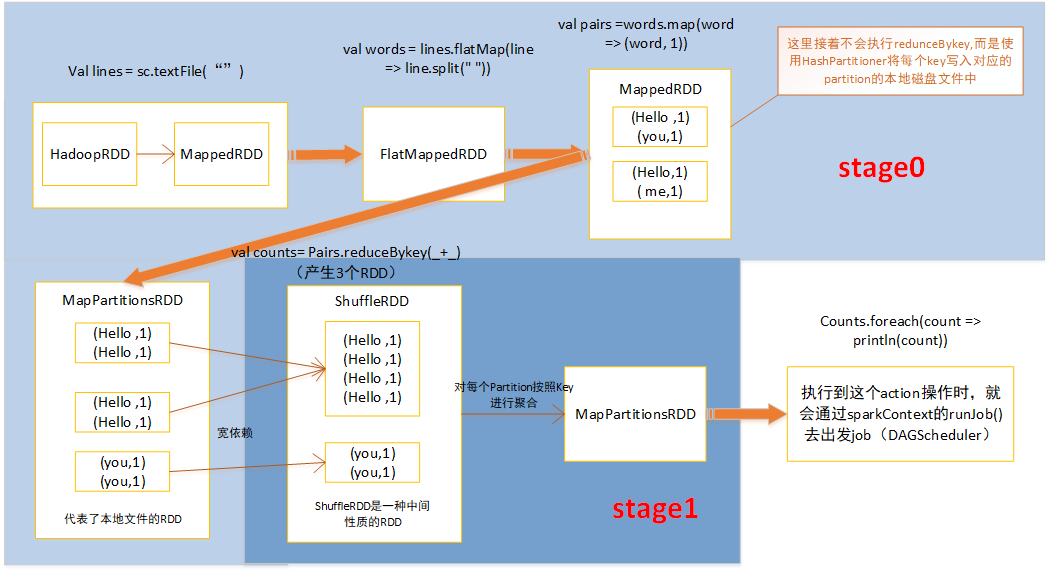
对于每一种有shuffle的操作。底层对应了三个RDD:MapPartitionsRDD、ShuffleRDD、MapPartitionsRDD
DAGScheduler stage 划分算法的更多相关文章
- 17、stage划分算法原理及DAGScheduler源码分析
一.stage划分算法原理 1.图解 二.DAGScheduler源码分析 1. ###org.apache.spark/SparkContext.scala // 调用SparkContext,之前 ...
- Spark源码剖析(八):stage划分原理与源码剖析
引言 对于Spark开发人员来说,了解stage的划分算法可以让你知道自己编写的spark application被划分为几个job,每个job被划分为几个stage,每个stage包括了你的哪些代码 ...
- [Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題 Job Stage 划分算法解密 Task 最佳位置算法實現解密 引言 作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这 ...
- Stage划分和Task最佳位置算法源码彻底解密
本课主题 Job Stage 划分算法解密 Task 最佳位置算法实现解密 引言 作业调度的划分算法以及 Task 的最佳计算位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- Spark任务提交底层原理
Driver的任务提交过程 1.Driver程序的代码运行到action操作,触发了SparkContext的runJob方法.2.SparkContext调用DAGScheduler的runJob函 ...
- 一个Spark job的生命历程
一个job的生命历程 dagScheduler.runJob //(1) --> submitJob ( eventProcessLoop.post(JobSubmitted,***) //(2 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
随机推荐
- Oracle数据库提权(dba权限执行系统命令)
0x01 提权准备 这里我们先创建一个低权限的用户test SQL> conn sys/admin123@orcl as sysdba; 已连接. SQL> create user tes ...
- CSS Grid 网格布局教程
一.概述 网格布局(Grid)是最强大的 CSS 布局方案. 它将网页划分成一个个网格,可以任意组合不同的网格,做出各种各样的布局.以前,只能通过复杂的 CSS 框架达到的效果,现在浏览器内置了. 上 ...
- 特征真的越多越好吗?从特征工程角度看“garbage in,garbage out”
1. 从朴素贝叶斯在医疗诊断中的迷思说起 这个模型最早被应用于医疗诊断,其中,类变量的不同值用于表示患者可能患的不同疾病.证据变量用于表示不同症状.化验结果等.在简单的疾病诊断上,朴素贝叶斯模型确实发 ...
- 【Python秘籍】numpy到tensor的转换
在用pytorch训练神经网络时,我们常常需要在numpy的数组变量类型与pytorch中的tensor类型进行转换,今天给大家介绍一种它们之间互相转换的方法. 一.numpy到tensor 首先我们 ...
- rem辅助式响应布局
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- json基本内容
json的基本信息和历史 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于欧洲计算机协会制定的js规范的一个子集,采用完全独立于编程语言的文本格式来 ...
- C和C++引用传递和数组传参引用
引用传递有两种传参方式,具体可参考文章 概括地讲,就是 *声明一个形参是指针,所以需要传递指针实参,对应的函数实现也应当遵循指针的语法.这种实现思路并不针对于C或者C++,因为它们都有指针,所以都可以 ...
- CSS3 变形、过渡、动画、关联属性浅析
一.变形 transform:可以对元素对象进行旋转rotate.缩放scale.移动translate.倾斜skew.矩阵变形matrix.示例: transform: rotate(90deg) ...
- python基础-流程控制(if,while,for)
今日内容总结 --流程控制(if,while,for) if:用来判断事物的对错.真假.是否执行.根据不同的情况判断,条件满足执行某条件下的语句 语法结构(3种) # 第一种,只有if结构.条件表达式 ...
- java的静态代理、jdk动态代理和cglib动态代理
Java的代理就是客户端不再直接和委托类打交道,而是通过一个中间层来访问,这个中间层就是代理.使用代理有两个好处,一是可以隐藏委托类的实现:二是可以实现客户与委托类之间的解耦,在不修改委托类代码的情况 ...