[Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密
本課主題
- Job Stage 划分算法解密
- Task 最佳位置算法實現解密
引言
作业调度的划分算法以及 Task 的最佳位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心,这也是关系到整个作业有集群中该怎么运行;其次就是数据本地性,Spark 一舨的代码都是链式表达的,这就让一个任务什么时候划分成 Stage,在大数据世界要追求最大化的数据本地性,所有最大化的数据本地性就是在数据计算的时候,数据就在内存中。最后就是 Spark 的实现算法时候的略的怎么样。希望这篇文章能为读者带出以下的启发:
- 了解 Stage 的具体是如何划分的
- 了解 数据本地性的最大化
Job Stage 划分算法解密
- Spark Application 中可以因为不同的Action 触发众多的Job,也就是一个Application 中可以有很多的Job ,每个Job 是由一个或者多个Stage 构成的,后面的Stage 依赖前面的Stage; 也就是说只有前面的依赖的Stage 计算完毕后,后面的Stage 才会运行;
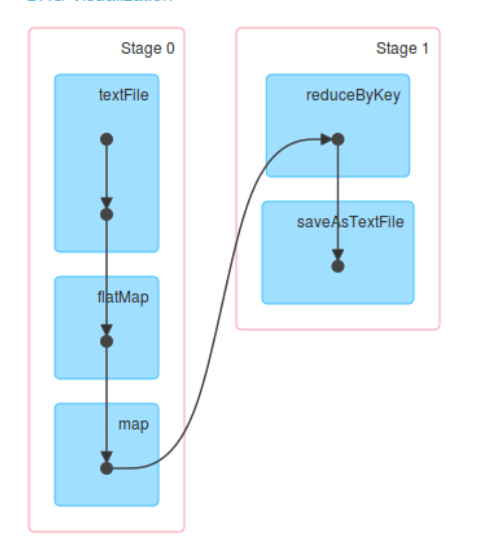
- Stage 划分的依据就是宽依赖,什么时侯产生宽依赖呢?例如 reduceByKey、groupByKey 等等;
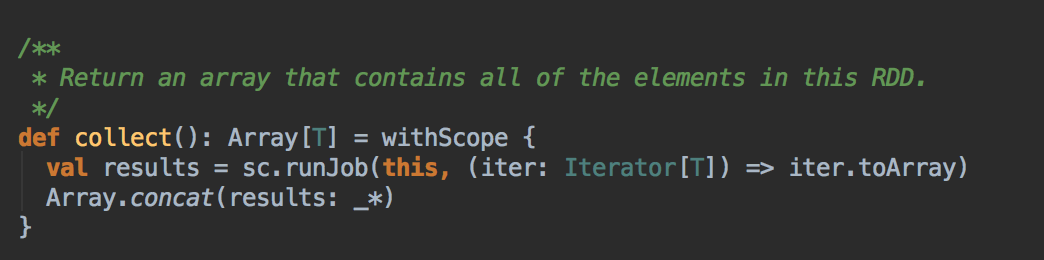
- 由 Action (例如collect) 导致了SparkContext.runJob 最终导致了 DAGScheduler 中的 submitJob 执行。

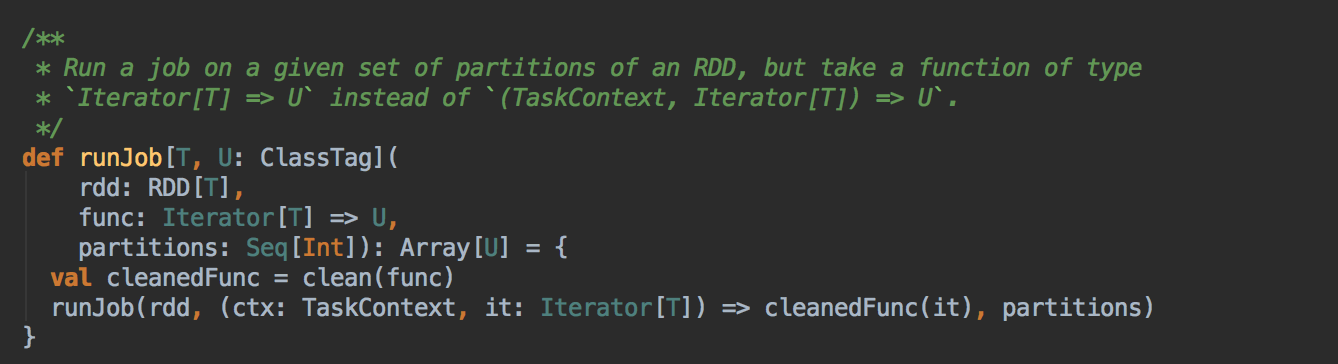
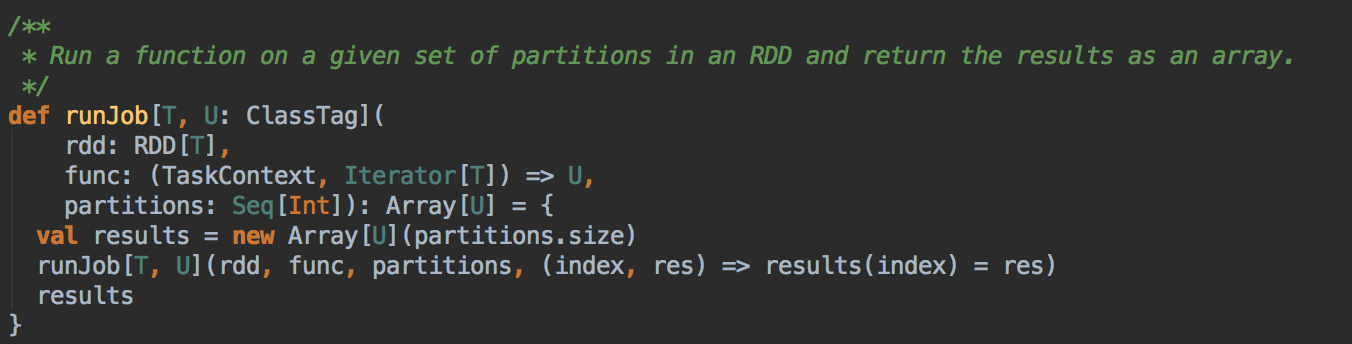
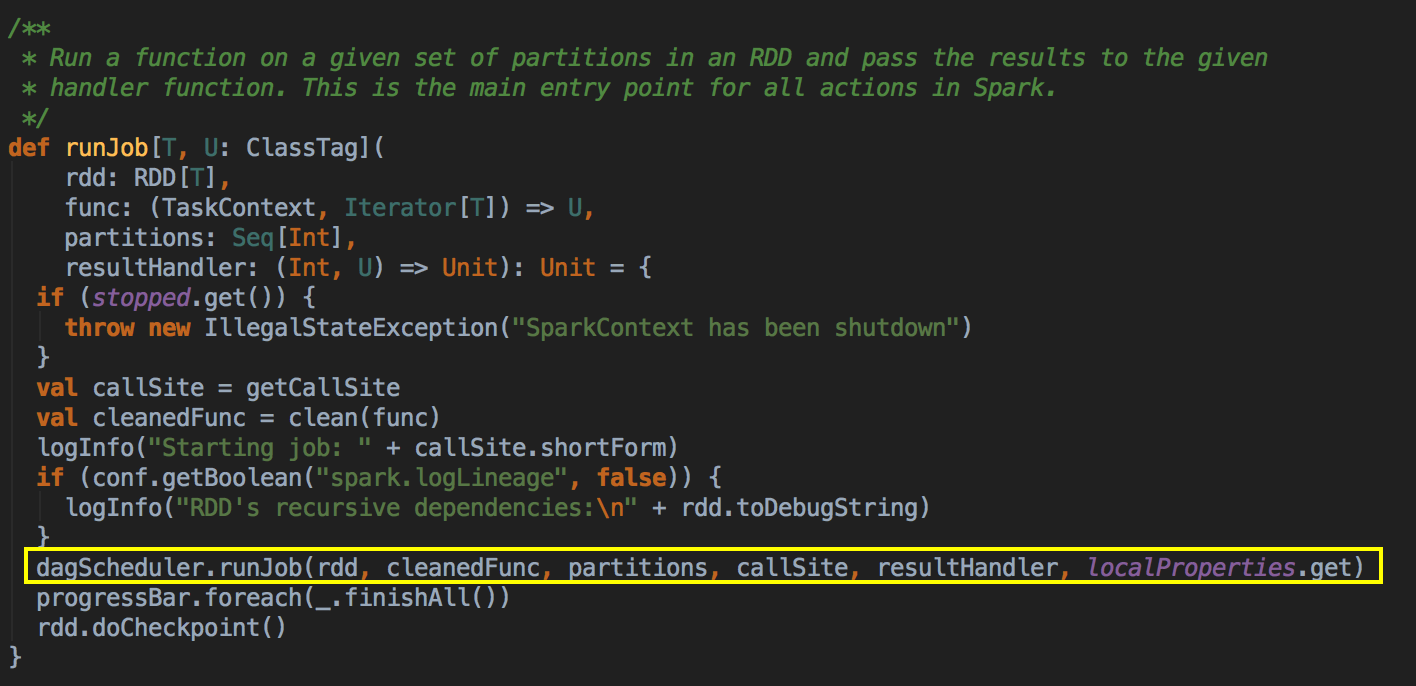
它会等待作业提交的结果,然后判断一下成功或者是失败来进行下一步操作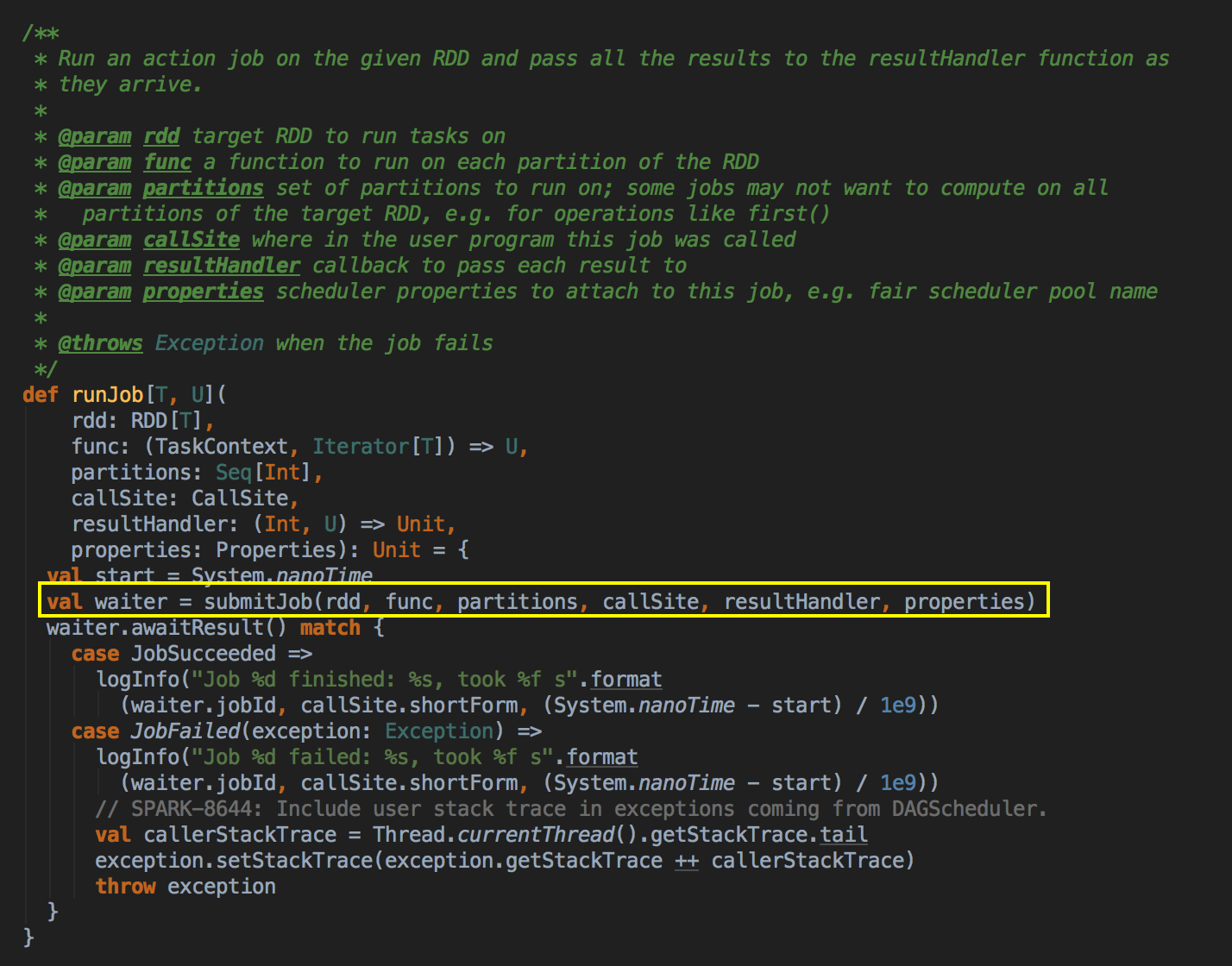
- 其核心是通过发送一个case class JobSubmitted 对象给 eventProcessLoop
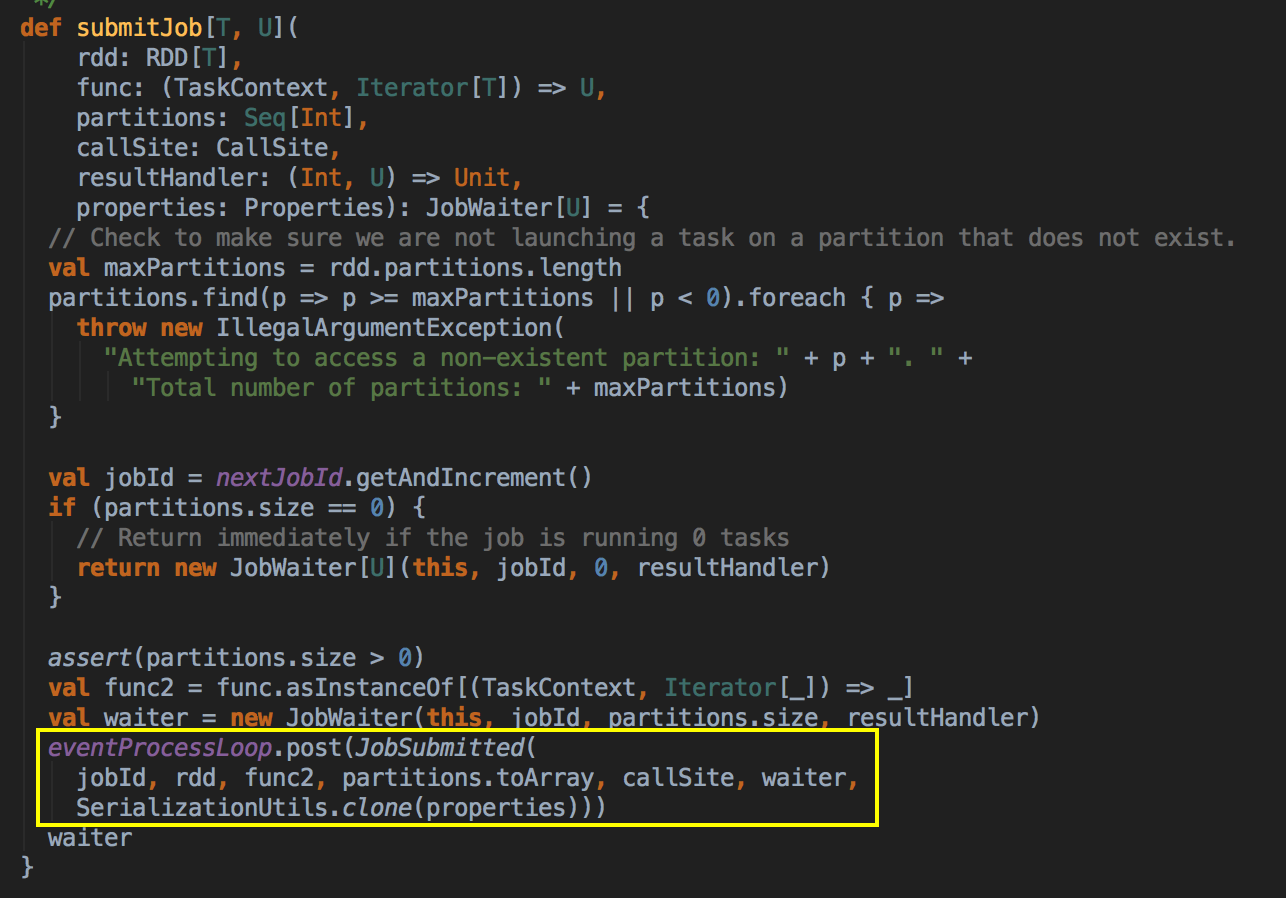
其中JobSubmitted 源码如下:因为需要创建不同的实例,所以要弄一个case class 而不是case object,case object 一般是以全区唯一的变量去使用。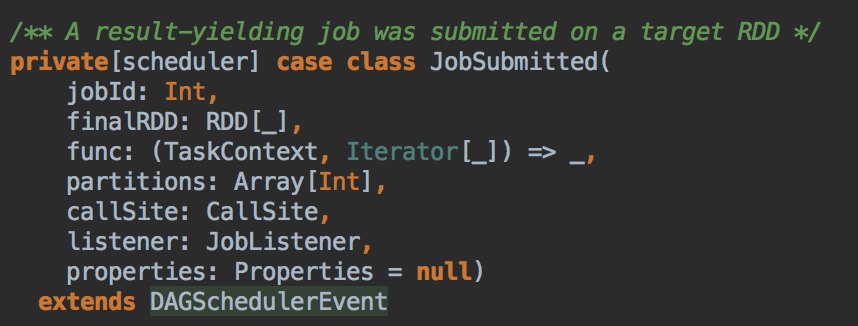
- 这里开了一条线程,用 post 的方式把消息交在队例中,由于你把它放在队例中它就会不断的循环去拿消息,它转过来就调用回调方法 onReceive( ),eventProcessLoop 是 一个消息循环器,它是 DAGSchedulerEvent 的具体实例,eventLoop 是一个 Link的blockingQueue。
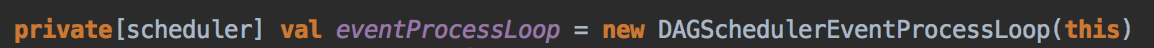

而DAGSchedulerEventProcessLoop 是 EventLoop 的子类,具体实现 eventLoop 的 onReceive 方法,onReceive方法转过来回调 doOnReceive( )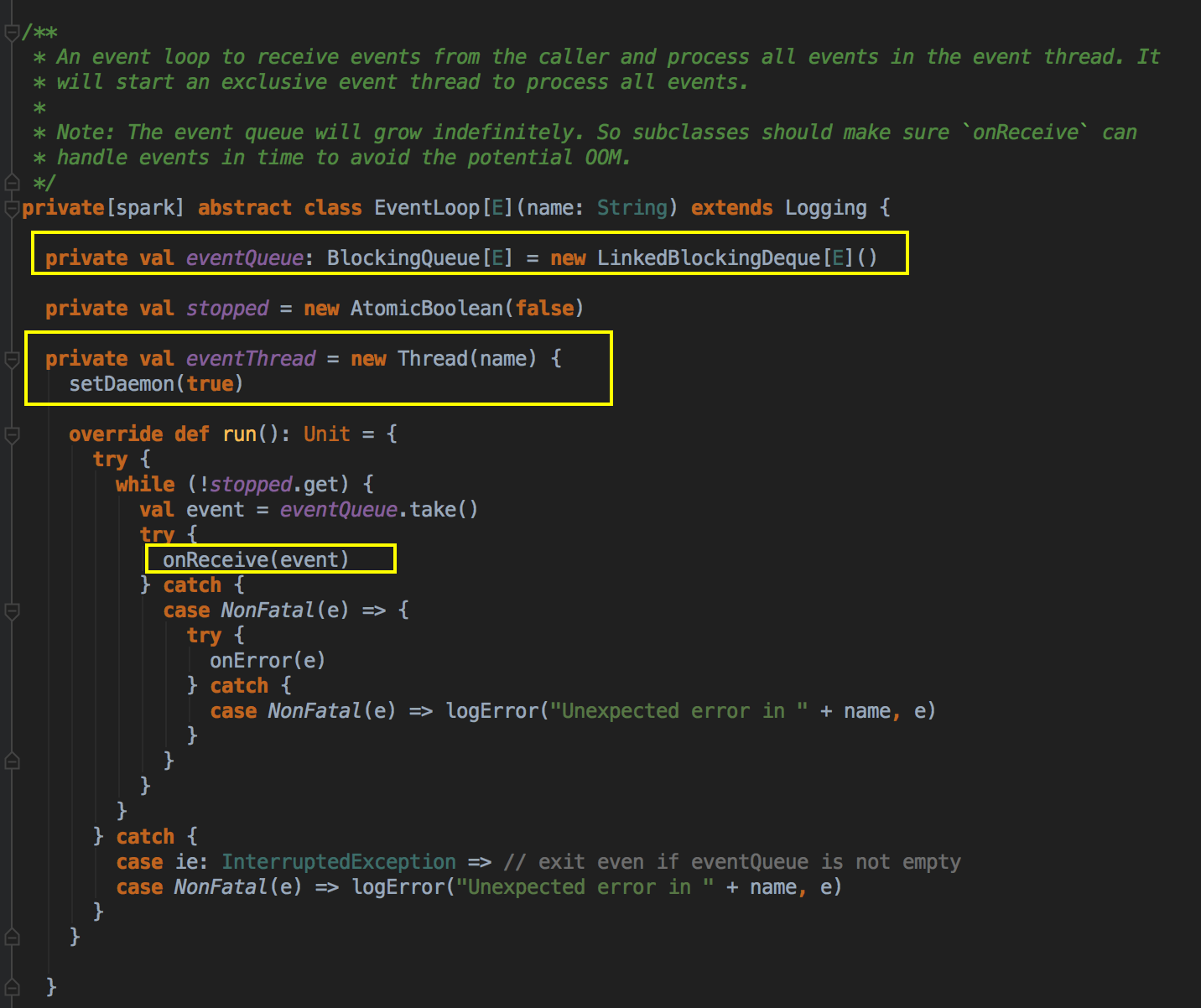
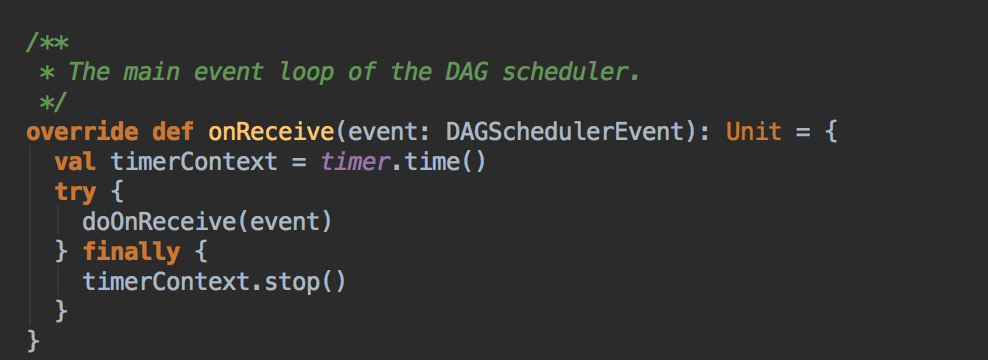
- 在 doOnReceive 这个类中有接收 JobSubmitted 的判断,转过来调用 handleJobSubmitted 的方法

思考题:为什么要再开一条线程搞一个消息循环器呢?因为有对例你就可以接受多个作业的提交,就是异步处理多 Job,这里背后有一个很重要的理念,就是如果无论是你自己发消息,还是别人发消息,你都采用一个线程去处理的话,这个时候处理的方式就是统一的,你的思路是一致的,这样你的扩展性就会非常的好,代码也会很乾净。
处理 Job 时的过程和逻辑
handleJobSubmitted( ) -->
- 调用 JobSubmitted 的方法,在这里用了一个消息循环器就可以统一对消息进行处理,在 handleJobSubmitted 中首先创建 finalStage,创建 finalStage 时会建立父 Stage 的依赖链条,这里是在这个算法里用的数据结构:

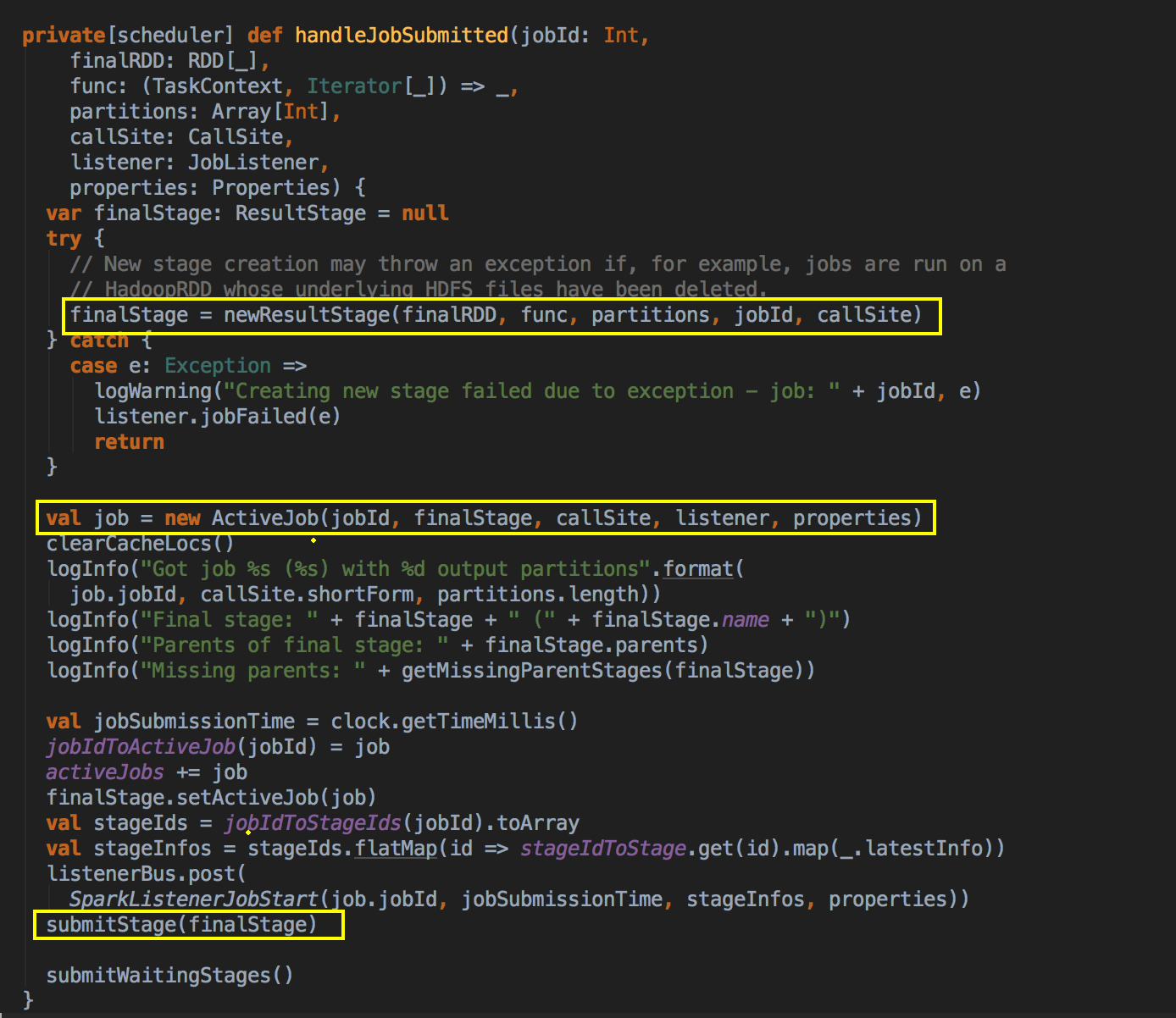

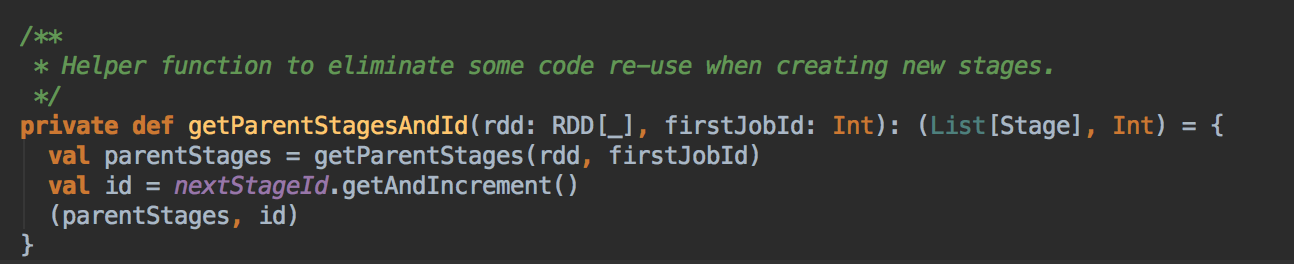
如果没有之前没有 visited 就把放在 visited 的数据结构中,然后判断一下它的依赖关系,如果是宽依赖的话就新增一个 Stage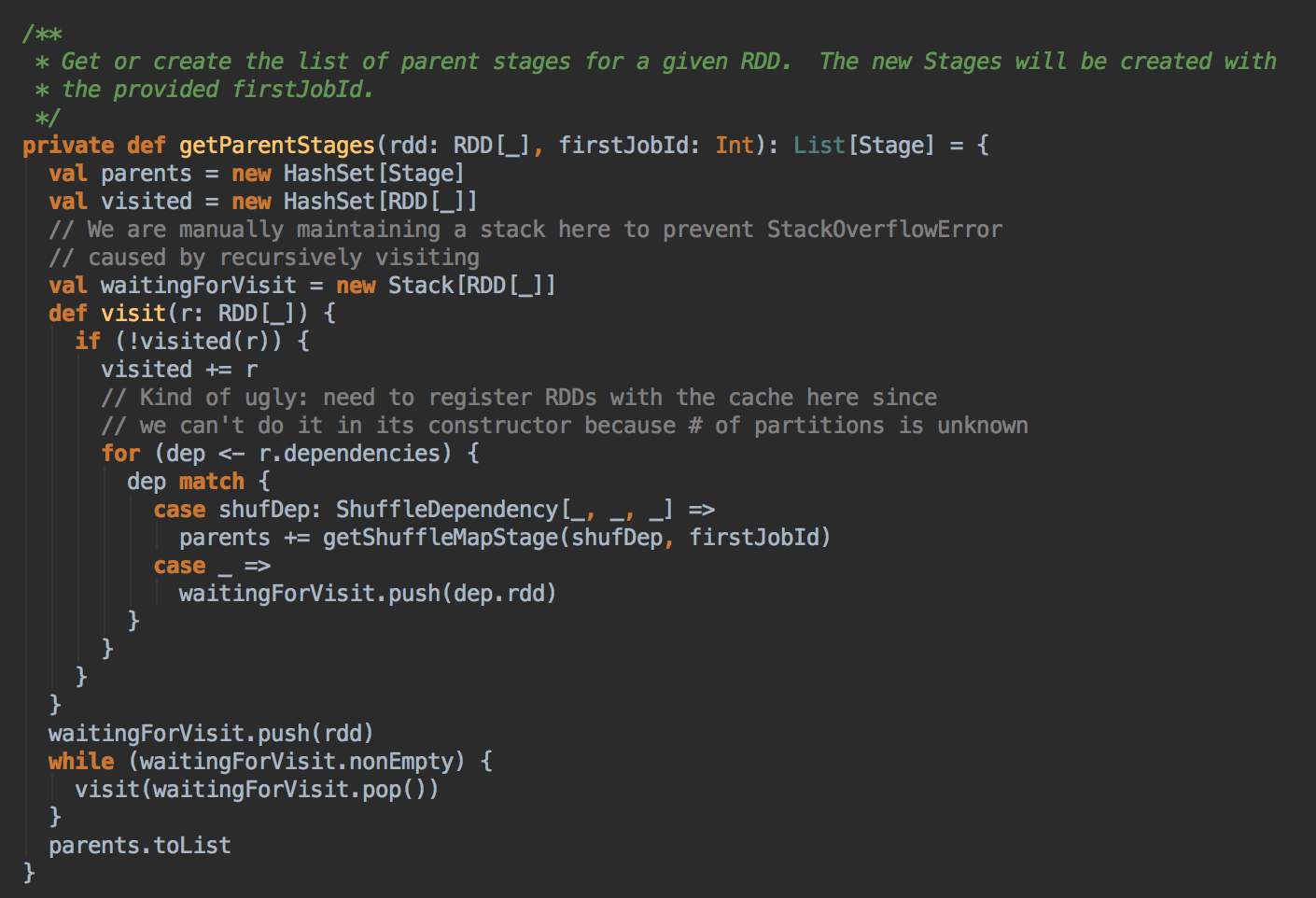
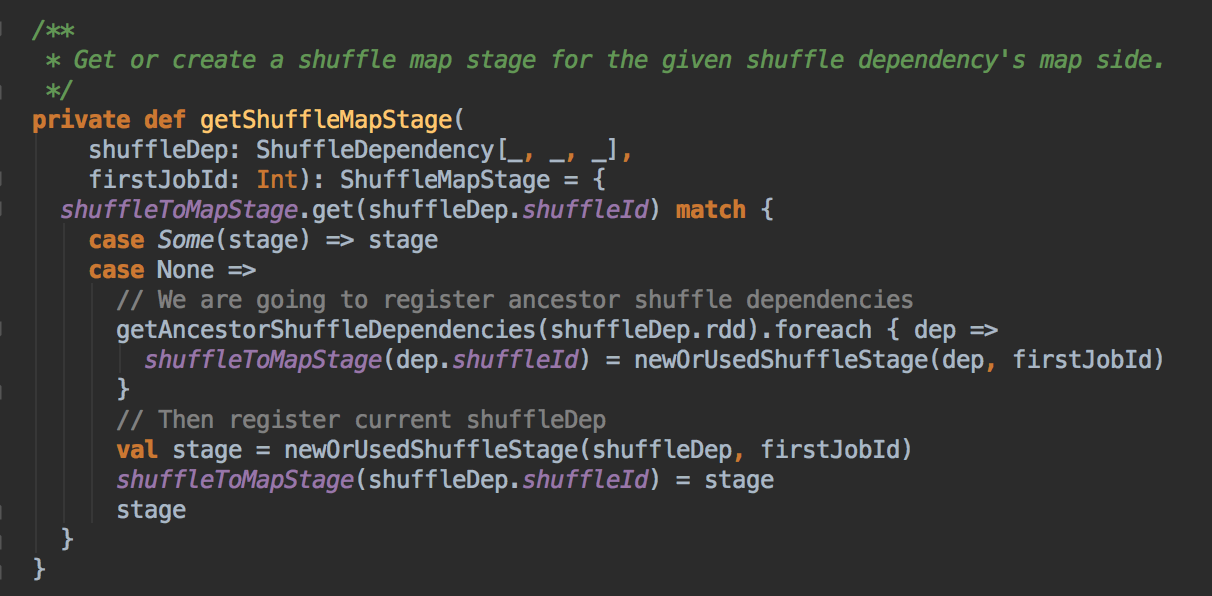
处理 missingParent
- 处理 missingParent
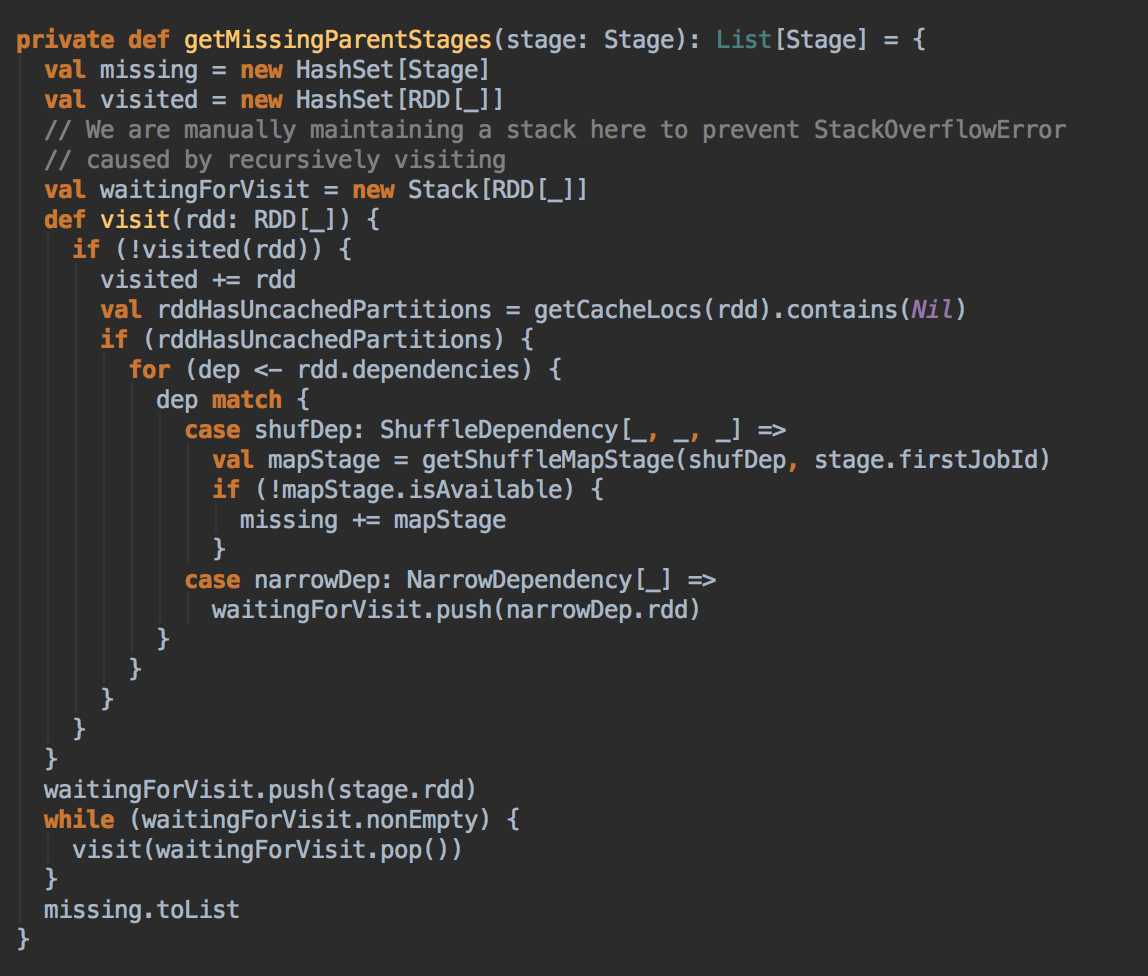
SubmitJob
- submitJob
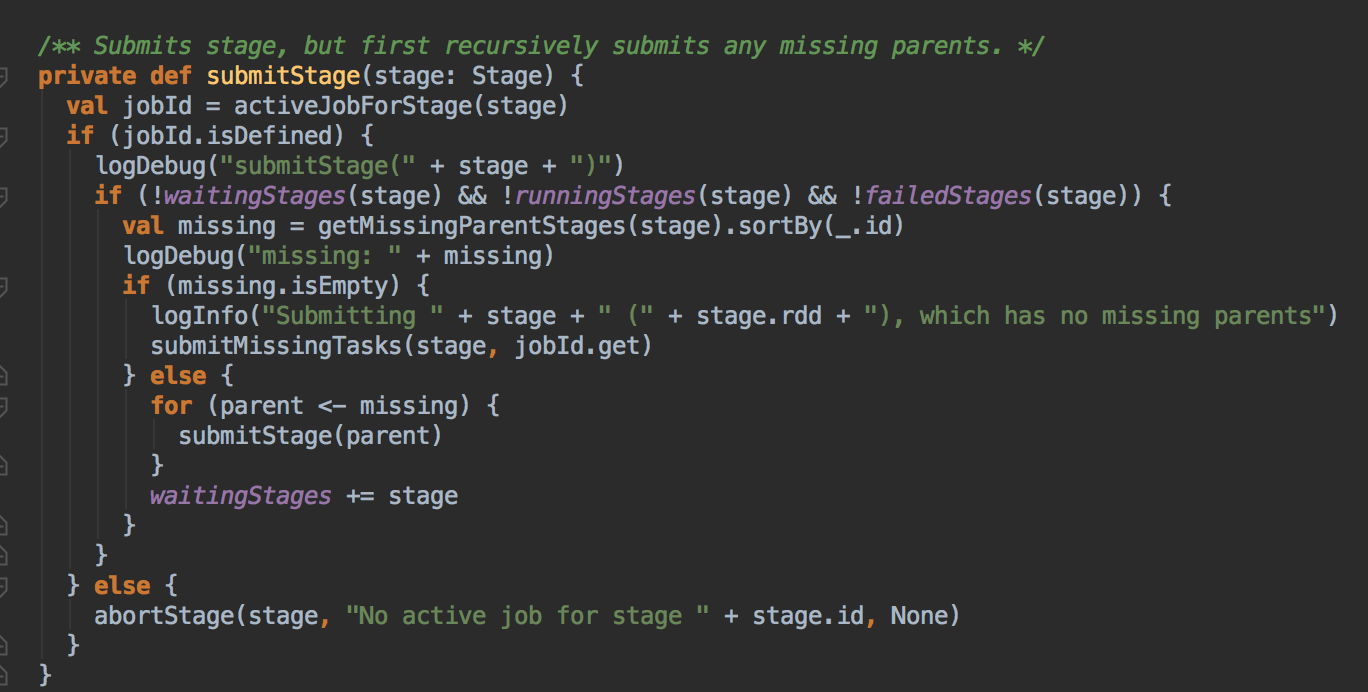
Task 最佳位置算法實現解密
- 從 submitMissingTask 开始找出它的数据本地算法
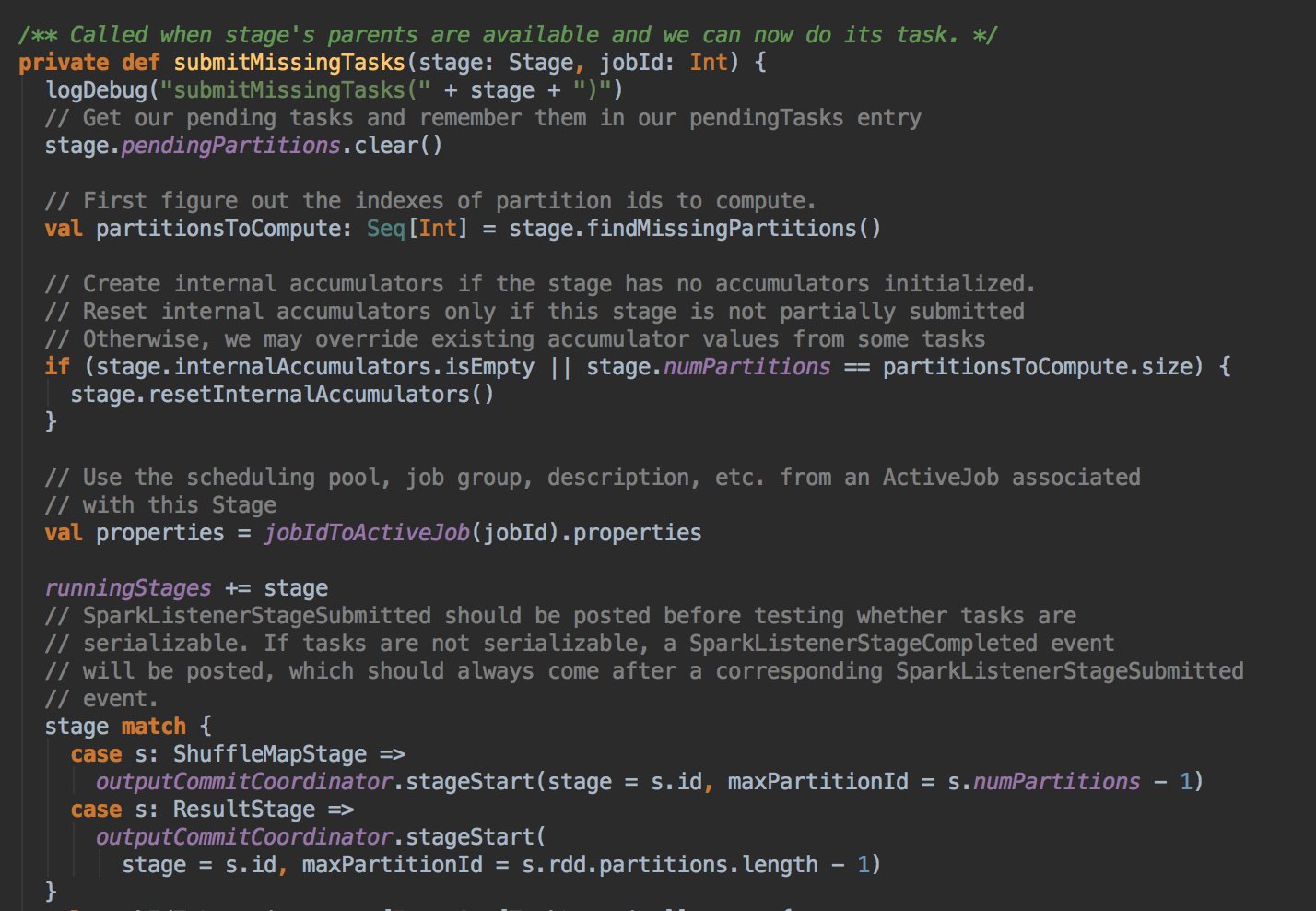
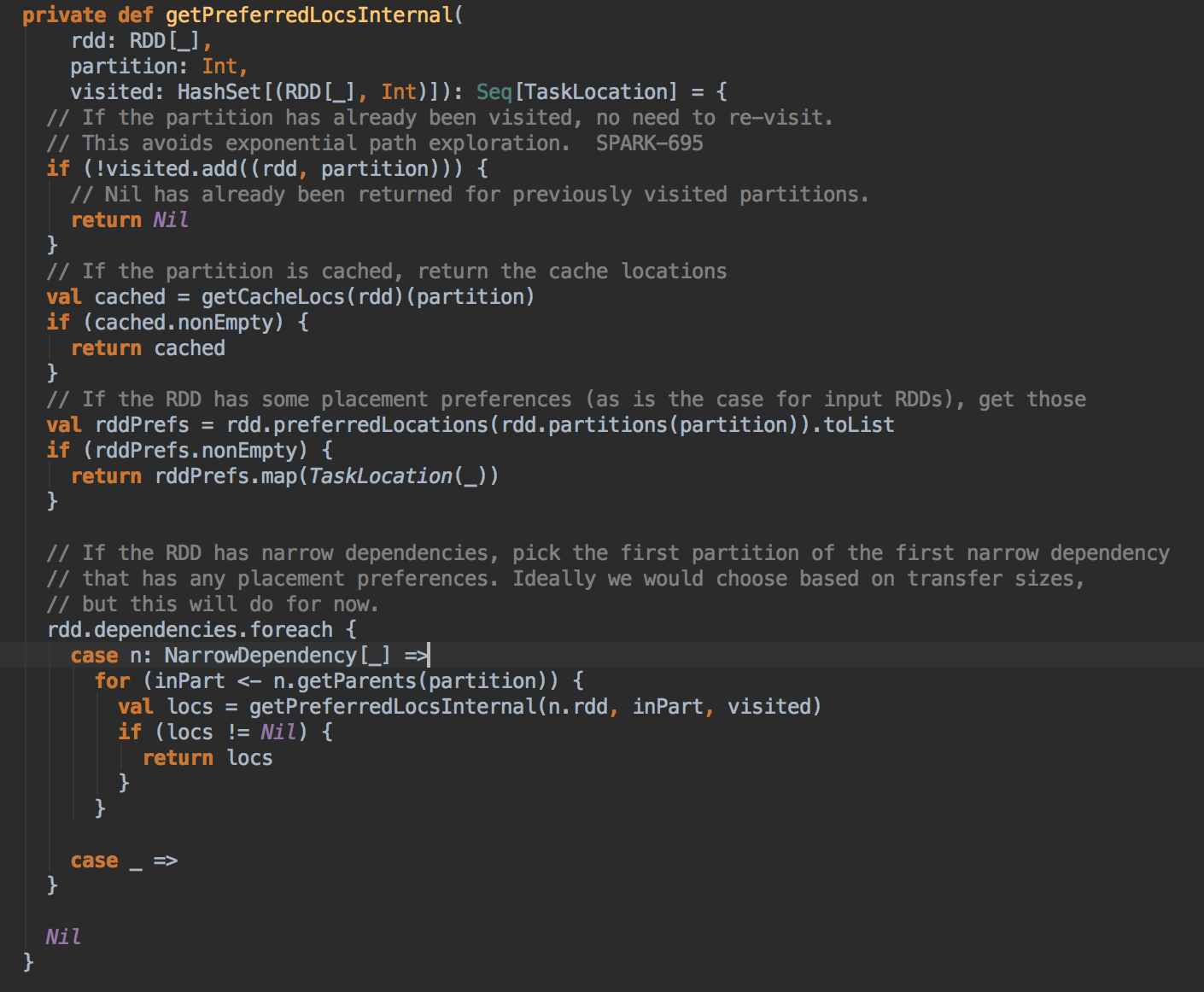
- 在具體算算法實現的時候,會首先查詢 DAGScheduler 的內存數據結構中是否存在當前 Partition 的數據本地性的信息,如果有得話就直接返回;如果沒有首先會調用 rdd.getPreferredLocations.例如想讓 Spark 運行在 HBase 上或者一種現在還沒有直接的數據庫上面,此時開發者需要自訂義 RDD,為了保証 Task 數據本地性,最為關鍵的方法就是必需實現 RDD 的 getPreferredLocations
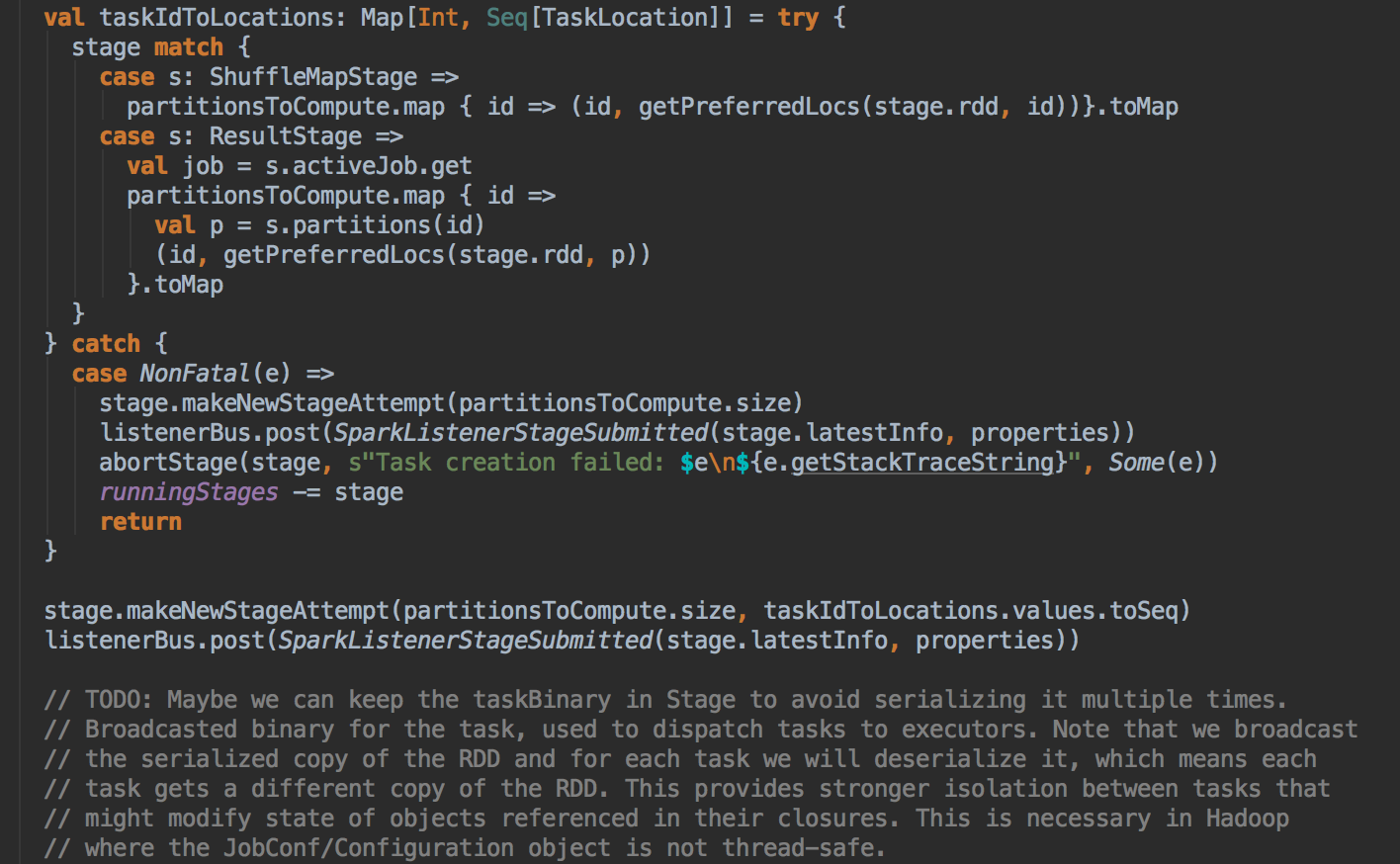
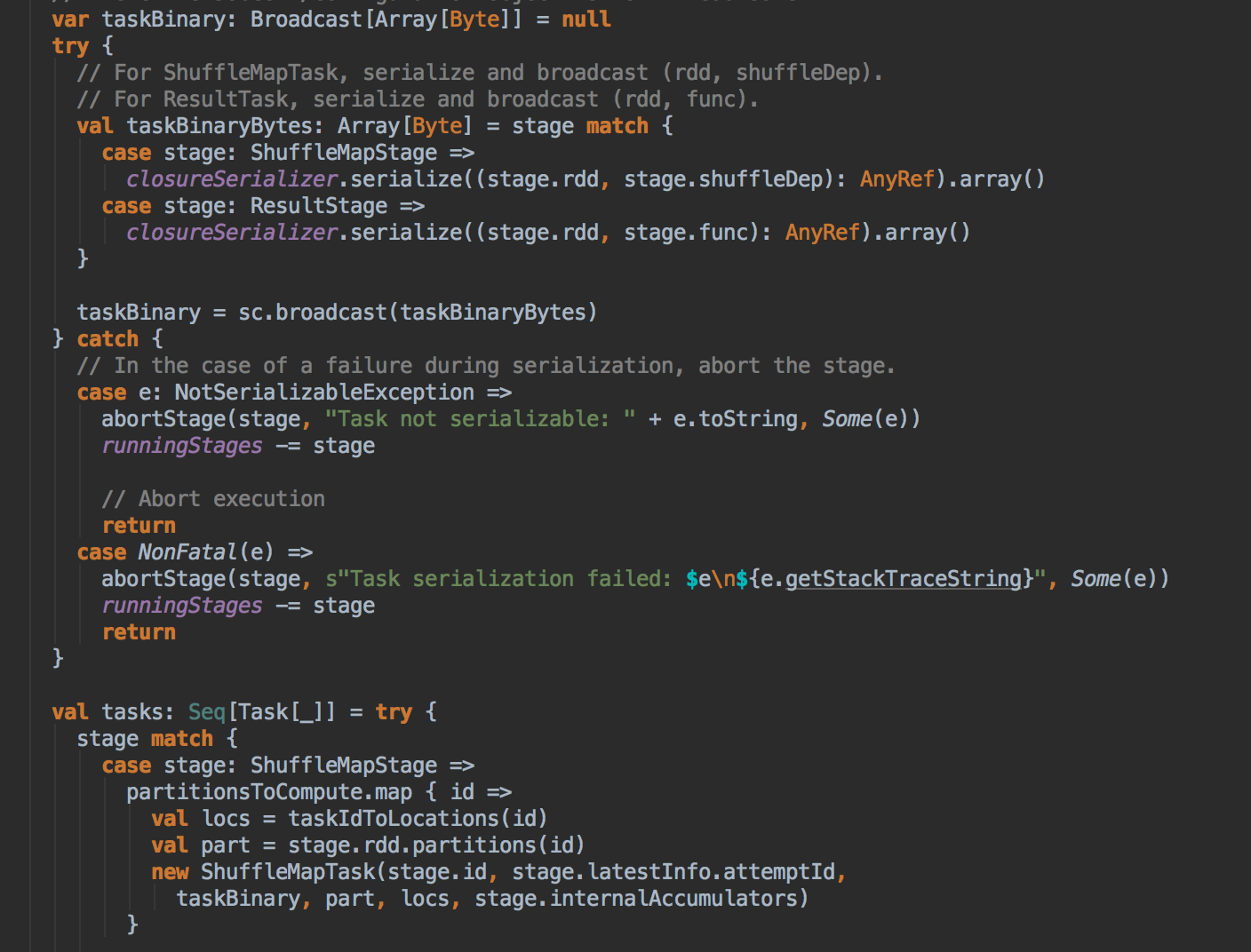
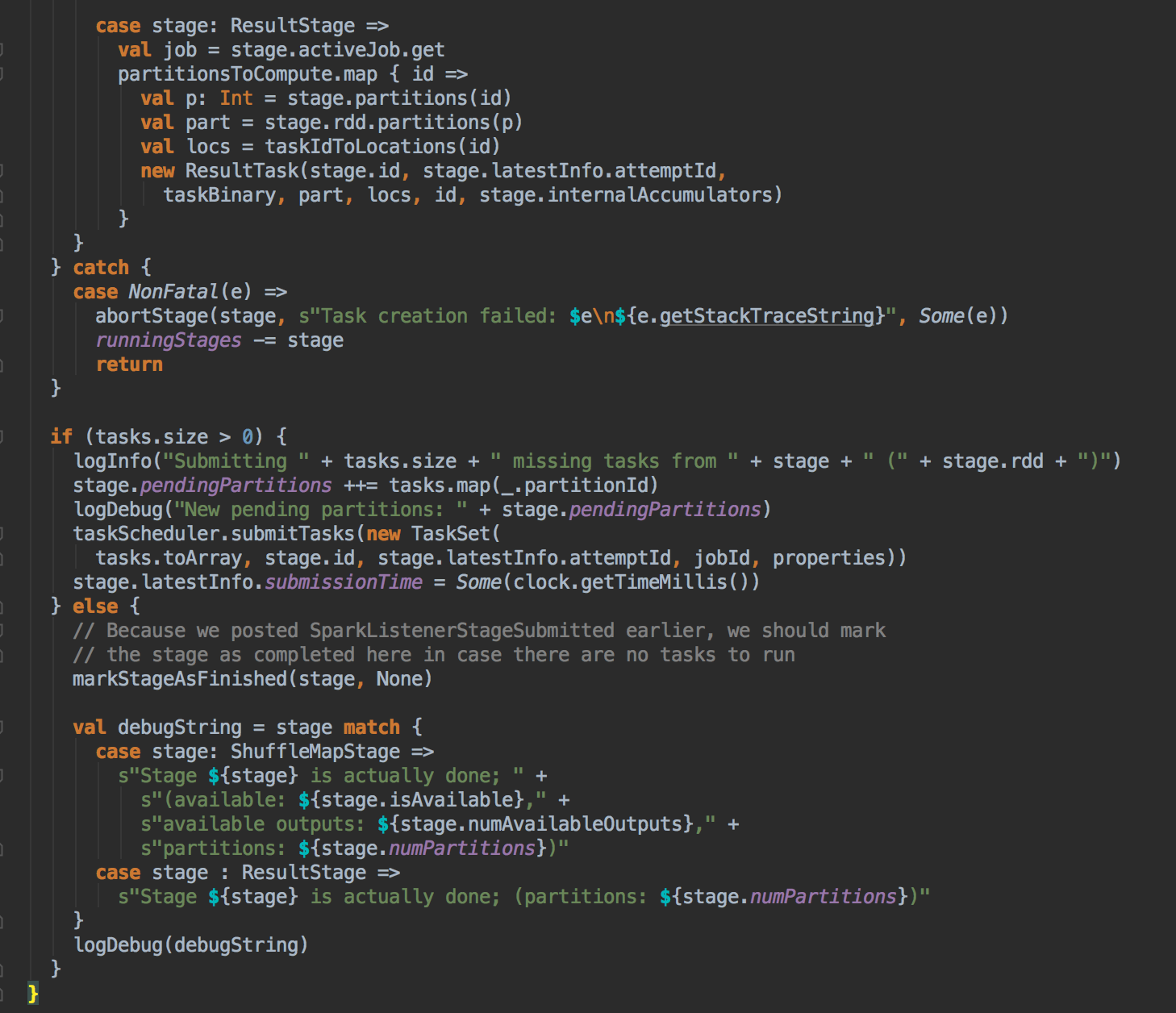

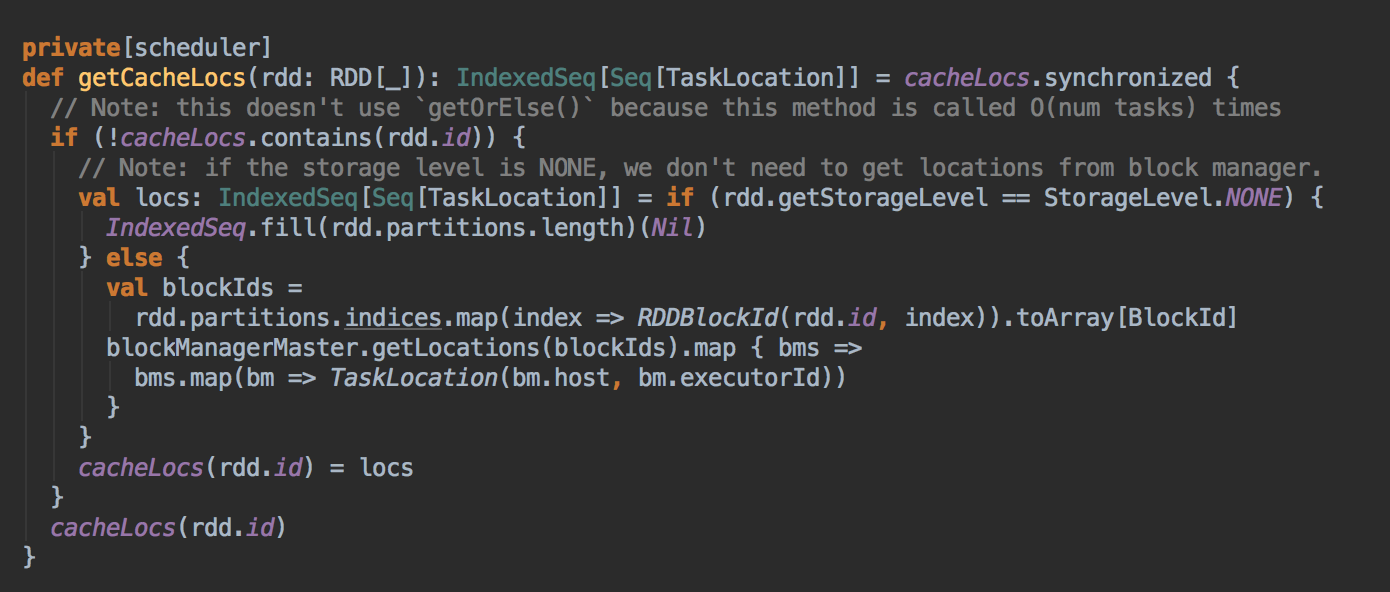
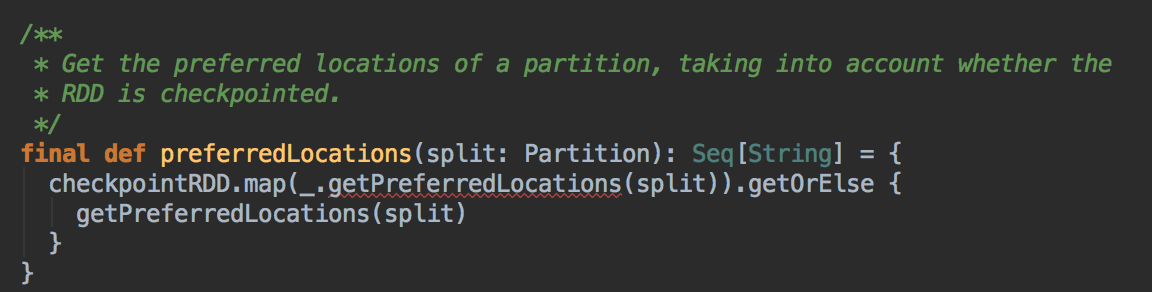
DAGScheduler 计算数据本地性的时候,巧妙的借助了RDD 自身的getPreferredLocations 中的数据,最大化的优化了效率,因为getPreferredLocations 中表明了每个Partition 的数据本地性,虽然当前Partition 可能被persists 或者是checkpoint,但是persists 或者是checkpoint默认情况下肯定是和getPreferredLocations 中的数据本地性是一致的,所以这就更大的优化了Task 的数据本地性算法的显现和效率的优化
总结
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第34课:Stage划分和Task最佳位置算法源码彻底解密
Spark源码图片取自于 Spark 1.6.0版本
[Spark内核] 第34课:Stage划分和Task最佳位置算法源码彻底解密的更多相关文章
- Stage划分和Task最佳位置算法源码彻底解密
本课主题 Job Stage 划分算法解密 Task 最佳位置算法实现解密 引言 作业调度的划分算法以及 Task 的最佳计算位置的算法,因为 Stage 的划分是DAGScheduler 工作的核心 ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Spark 源码解析:TaskScheduler的任务提交和task最佳位置算法
上篇文章< Spark 源码解析 : DAGScheduler中的DAG划分与提交 >介绍了DAGScheduler的Stage划分算法. 本文继续分析Stage被封装成TaskSet, ...
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- [Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第28课:Spark天堂之门解密
本課主題 什么是 Spark 的天堂之门 Spark 天堂之门到底在那里 Spark 天堂之门源码鉴赏 引言 我说的 Spark 天堂之门就是SparkContext,这篇文章会从 SparkCont ...
- [Spark内核] 第37课:Task执行内幕与结果处理解密
本课主题 Task执行内幕与结果处理解密 引言 这一章我们主要关心的是 Task 是怎样被计算的以及结果是怎么被处理的 了解 Task 是怎样被计算的以及结果是怎么被处理的 Task 执行原理流程图 ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
随机推荐
- C++ 函数对象
函数对象 c++中函数名后的()称为函数调用运算符.函数调用运算符也可以重载,如果某个类重载了函数调用运算符,则该类的实例就是一个函数对象.函数对象本身并不是很有用,但他们使得算法操作的参数化策略成为 ...
- 使用背景图修改radio、checkbox样式
如果觉得设置样式太麻烦,或者页面上选中的样式太复杂,也可以用背景图去修改样式<div class=""> <label><input type=&qu ...
- netty详解之reactor模型
假设在办理各种证件时分为填表,审核,制作3个过程,每个过程用时10分钟,这样一个工作人员需要30分钟办理一个证件.那么有没有办法提供效率,减少等待时间呢.可以让一个专门的工作人员,每个顾客到来时就负责 ...
- 介绍一个法国的时间戳server
特别说明: 以下介绍的法国时间戳server已经停止服务了.我曾发Email给相关站点的管理员.对方回复说他也不知道什么时候能恢复服务,有可能就是遥遥无期了.所以以下的内容仅有參考价值.没法实践了. ...
- 解决PL/SQL Developer 连接oracle 11g 64位中的问题
1.错误1:Initialization error could not initialize 电脑上原本就装有oracle 11g 64位,但是PL/SQL却怎么也连接不上,报出" Ini ...
- (转)spring aop
工作忙,时间紧,不过事情再多,学习是必须的.记得以前的部门老大说过:“开发人员不可能一天到晚只有工作,肯定是需要自我学习.第一:为了更充实自己,保持进步状态.第二:为了提升技术,提高开发能力.第三:保 ...
- 自学Zabbix3.7.2-事件Event-来源与分类
一.zabbix 事件从字面理解,就是发生了一个事情就算是一个事件.就在trigger的文章内,我们已经有用到事件,这个事件要讲概念真心不知道怎么说,就拿trigger事件来说,如果trigger从当 ...
- 《调试九法——软硬件错误的排查之道》【PDF】下载
<调试九法--软硬件错误的排查之道>[PDF]下载链接: https://u253469.ctfile.com/fs/253469-231196352 内容简介 <调试九法:软硬件错 ...
- java二维码生成代码
QRCodeUtil.encode(text, "D:/004.jpg", "D:", true, "exp");// 这个方法的第一个参数 ...
- C++各种指针辨析
1)int *p p与*结合,表明p是一个指针 然后前面int说明p是一个整形的指针 2)int *p[n] 因为[]比*优先级高,所以p先与[]结合,表明p是个数组,然后这个数组在与*结合,说明数组 ...