用go语言爬取珍爱网 | 第二回


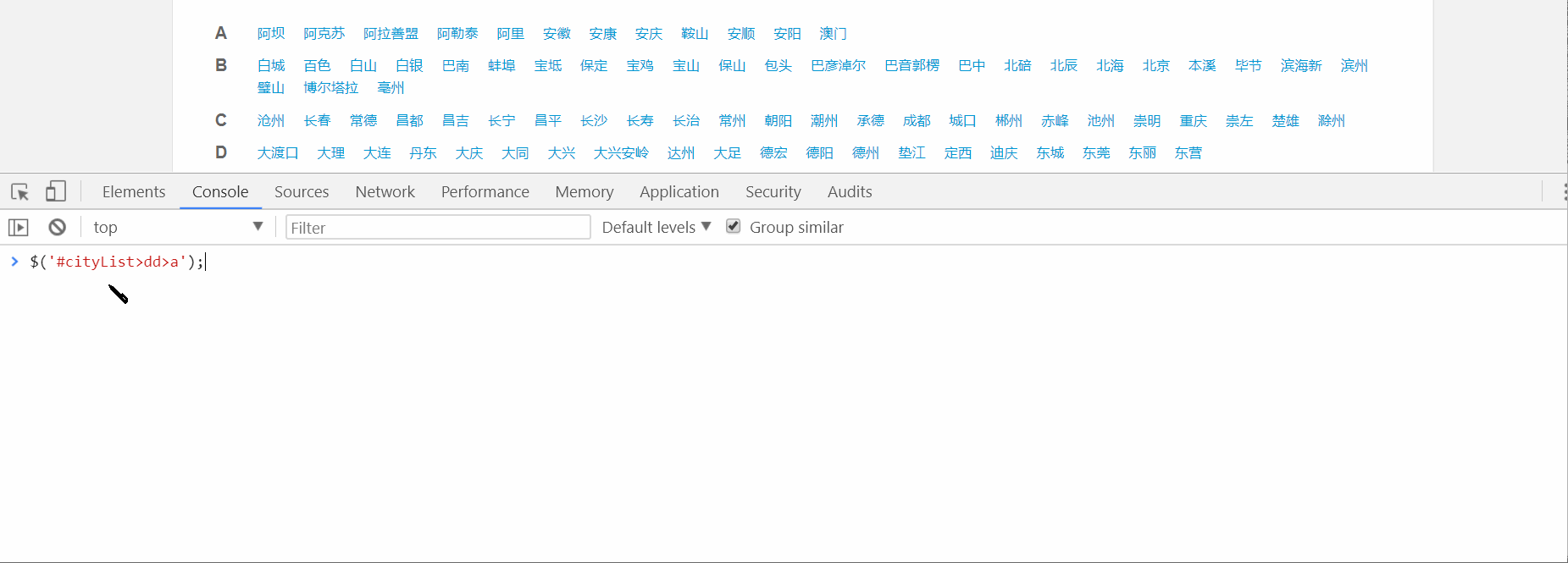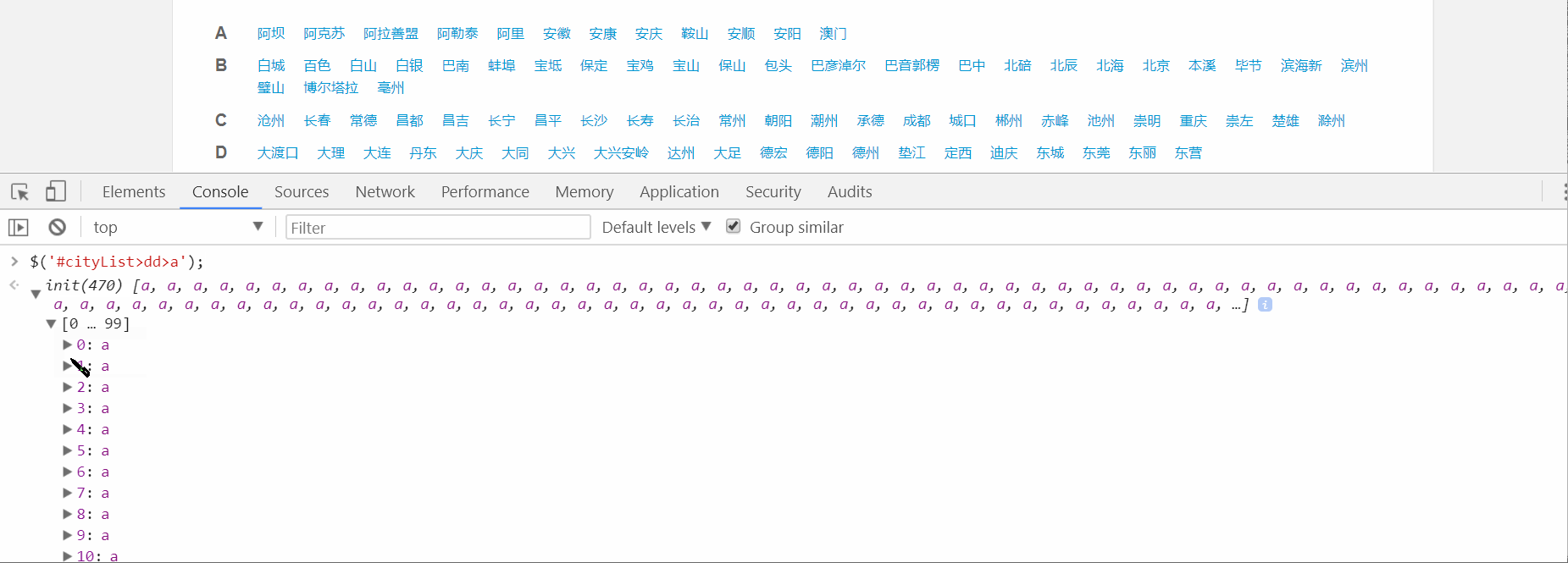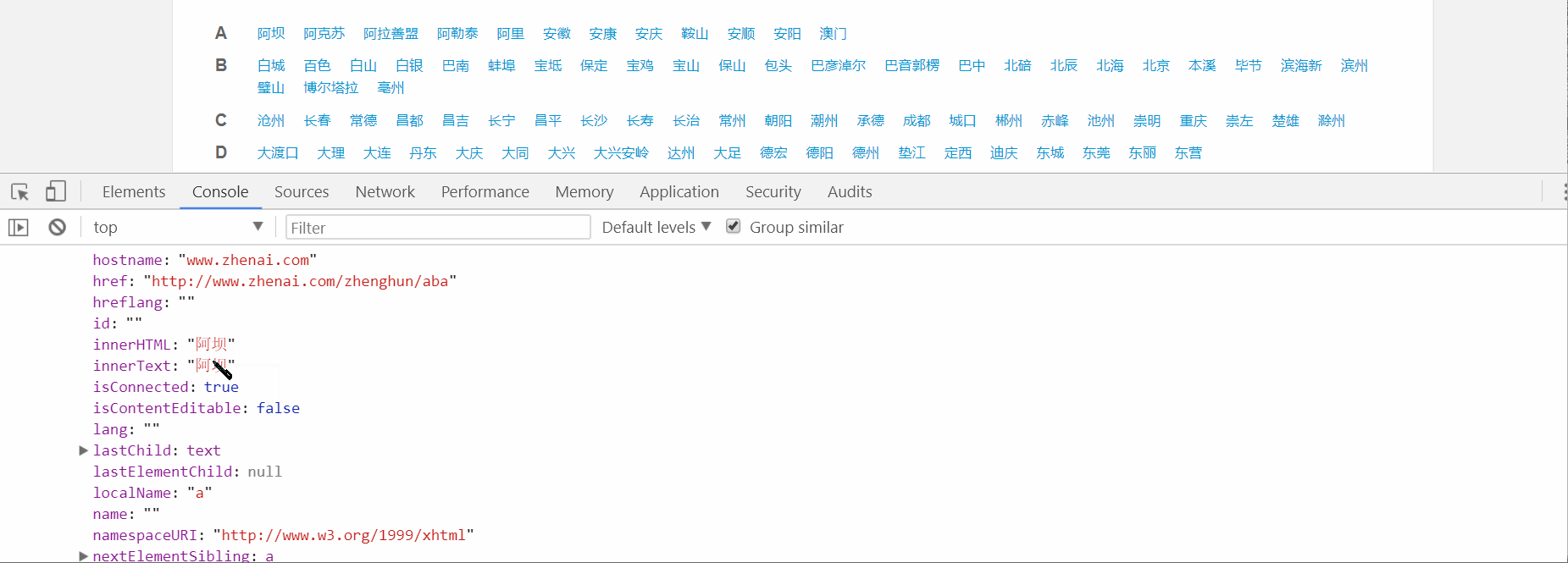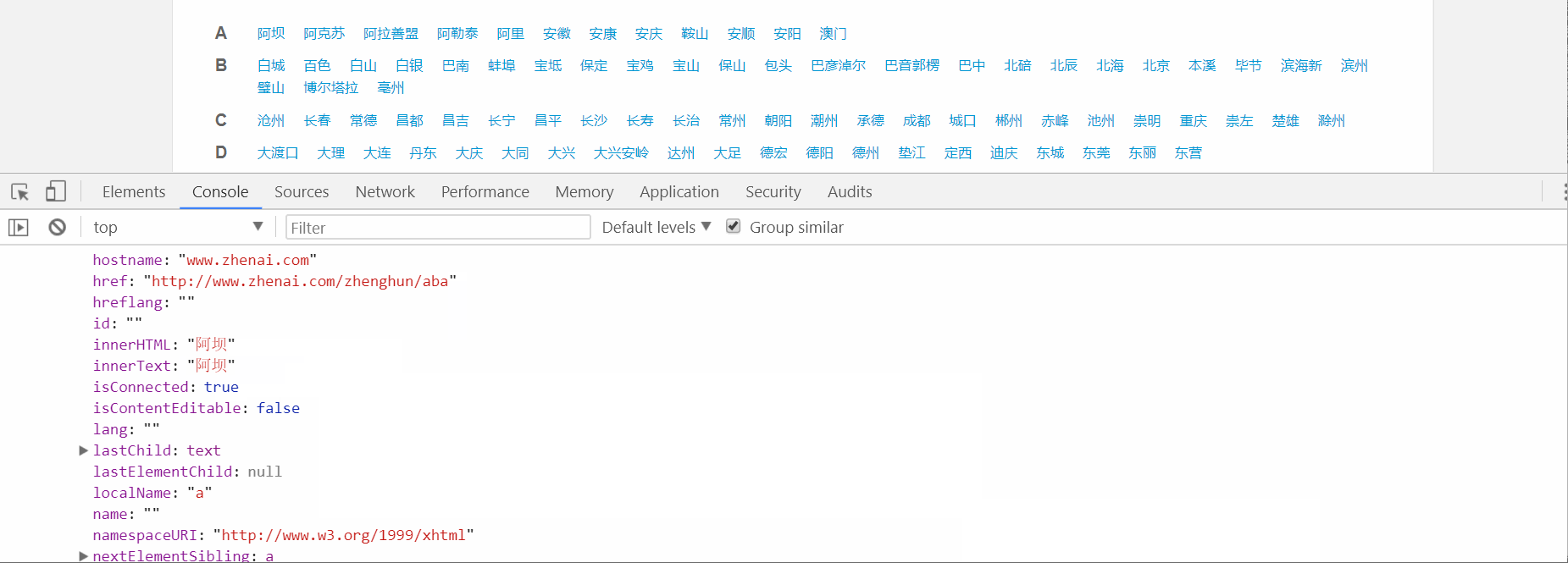
昨天我们一起爬取珍爱网首页,拿到了城市列表页面,接下来在返回体城市列表中提取城市和url,即下图中的a标签里的href的值和innerText值。
提取a标签,可以通过CSS选择器来选择,如下:
$('#cityList>dd>a');就可以获取到470个a标签:
这里只提供一个思路,go语言标准库里没有CSS解析库,通过第三方库可以实现。具体可以参考文章:
https://my.oschina.net/2xixi/blog/488811
http://liyangliang.me/posts/2016/03/zhihu-go-insight-parsing-html-with-goquery/
这两篇文章都是用goquery解析 HTML,用到了库:
https://github.com/PuerkitoBio/goquery
也可以用xpath去解析html,可以参考:
https://github.com/antchfx/xquery
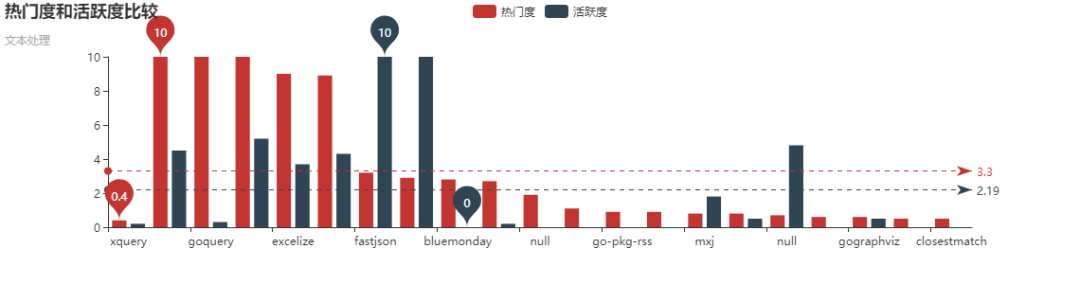
xpath和goquery相比还是比较麻烦的,通过以下这张图可以看出来goquery要活跃的多:
我们这里不用xpath,也不用goquery提取,用更加通用的正则表达式来提取。
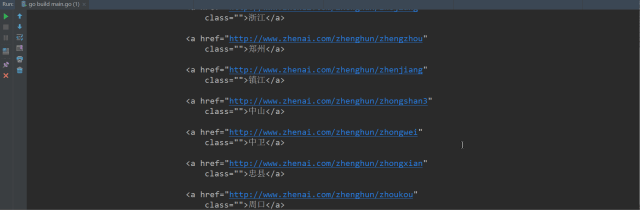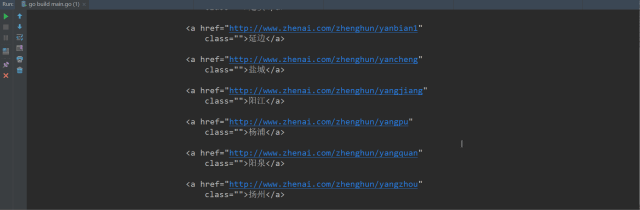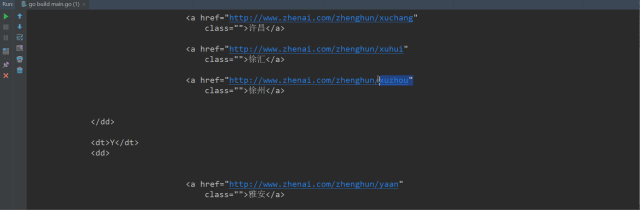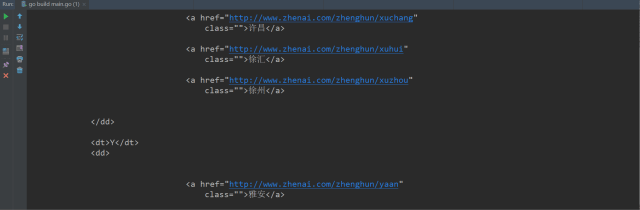
从上图可以看出,返回体中的a标签里都是这种形式,XXX表示城市拼音,XX表示城市中文,其他的都一样。
<a href="http://www.zhenai.com/zhenghun/XXX"
class="">XX</a>
所以可以写出以下的正则表达式来匹配:
compile := regexp.MustCompile(`<a href="http://www.zhenai.com/zhenghun/[0-9a-z]+"[^>]*>[^<]+</a>`)
正则表达式说明:
1、href的值都类似http://www.zhenai.com/zhenghun/XX
2、XX可以是数字和小写字母,所以[0-9a-z],+表示至少有一个
3、[^>]*表示匹配不是>的其他字符任意次
4、[^<]+表示匹配不是<的其他字符至少一次
然后利用分组获取url和城市,代码如下:
func printAllCityInfo(body []byte){
//href的值都类似http://www.zhenai.com/zhenghun/XX
//XX可以是数字和小写字母,所以[0-9a-z],+表示至少有一个
//[^>]*表示匹配不是>的其他字符任意次
//[^<]+表示匹配不是<的其他字符至少一次
compile := regexp.MustCompile(`<a href="(http://www.zhenai.com/zhenghun/[0-9a-z]+)"[^>]*>([^<]+)</a>`)
submatch := compile.FindAllSubmatch(body, -1)
for _, matches := range submatch {
//打印
fmt.Printf("City:%s URL:%s\n", matches[2], matches[1])
}
//可以看到匹配个数为470个
fmt.Printf("Matches count: %d\n", len(submatch))
}
那么提取URL和City的完整代码如下:
package main
import (
"fmt"
"io/ioutil"
"net/http"
"golang.org/x/text/transform"
//"golang.org/x/text/encoding/simplifiedchinese"
"io"
"golang.org/x/text/encoding"
"bufio"
"golang.org/x/net/html/charset"
"regexp"
)
func main() {
//返送请求获取返回结果
resp, err := http.Get("http://www.zhenai.com/zhenghun")
if err != nil {
panic(fmt.Errorf("Error: http Get, err is %v\n", err))
}
//关闭response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Println("Error: statuscode is ", resp.StatusCode)
return
}
//utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
utf8Reader := transform.NewReader(resp.Body, determinEncoding(resp.Body).NewDecoder())
body, err := ioutil.ReadAll(utf8Reader)
if err != nil {
fmt.Println("Error read body, error is ", err)
}
printAllCityInfo(body)
//打印返回值
//fmt.Println("body is ", string(body))
}
func determinEncoding(r io.Reader) encoding.Encoding {
//这里的r读取完得保证resp.Body还可读
body, err := bufio.NewReader(r).Peek(1024)
if err != nil {
fmt.Println("Error: peek 1024 byte of body err is ", err)
}
//这里简化,不取是否确认
e, _, _ := charset.DetermineEncoding(body, "")
return e
}
func printAllCityInfo(body []byte){
//href的值都类似http://www.zhenai.com/zhenghun/XX
//XX可以是数字和小写字母,所以[0-9a-z],+表示至少有一个
//[^>]*表示匹配不是>的其他字符任意次
//[^<]+表示匹配不是<的其他字符至少一次
compile := regexp.MustCompile(`<a href="(http://www.zhenai.com/zhenghun/[0-9a-z]+)"[^>]*>([^<]+)</a>`)
/*matches := compile.FindAll(body, -1)
//matches是二维数组[][]byte
for _, m := range matches {
fmt.Printf("%s\n", m)
}
*/
submatch := compile.FindAllSubmatch(body, -1)
//submatch是三维数组[][][]byte
/* for _, matches := range submatch {
//[][]byte
for _, m := range matches {
fmt.Printf("%s ", m)
}
fmt.Println()
}*/
for _, matches := range submatch {
//打印
fmt.Printf("City:%s URL:%s\n", matches[2], matches[1])
}
//可以看到匹配个数为470个
fmt.Printf("Matches count: %d\n", len(submatch))
//打印abc
//fmt.Printf("%s\n", []byte{97,98,99})
}
运行后,可以看到输出了URL和City:

今天我们完成了URL和城市的提取,明天我们将利用URL,来进一步分析城市的男女性个人信息。
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你

用go语言爬取珍爱网 | 第二回的更多相关文章
- 用go语言爬取珍爱网 | 第一回
我们来用go语言爬取"珍爱网"用户信息. 首先分析到请求url为: http://www.zhenai.com/zhenghun 接下来用go请求该url,代码如下: packag ...
- 用go语言爬取珍爱网 | 第三回
前两节我们获取到了城市的URL和城市名,今天我们来解析用户信息. 用go语言爬取珍爱网 | 第一回 用go语言爬取珍爱网 | 第二回 爬虫的算法: 我们要提取返回体中的城市列表,需要用到城市列表解析器 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- GoLang爬取花瓣网美女图片
由于之前一直想爬取花瓣网(http://huaban.com/partner/uc/aimeinv/pins/) 的图片,又迫于没时间,所以拖了很久. 鉴于最近在学go语言,就刚好用这个练手了. 预览 ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- 基于爬取百合网的数据,用matplotlib生成图表
爬取百合网的数据链接:http://www.cnblogs.com/YuWeiXiF/p/8439552.html 总共爬了22779条数据.第一次接触matplotlib库,以下代码参考了matpl ...
随机推荐
- 谁动了我的奶酪?--java实例初始化的顺序问题
故事背景 有一天,老鼠小白发现了一个奇怪的问题,它的奶酪的生产日期被谁搞丢了,不知道奶酪是否过期,可怎么吃呀? 让我们来看看吧 import java.util.Date;public class C ...
- Nginx总结(六)nginx实现负载均衡
前面讲了如何配置Nginx虚拟主机,大家可以去这里看看nginx系列文章:https://www.cnblogs.com/zhangweizhong/category/1529997.html 今天要 ...
- [大数据学习研究] 4. Zookeeper-分布式服务的协同管理神器
本来这一节想写Hadoop的分布式高可用环境的搭建,写到一半,发现还是有必要先介绍一下ZooKeeper这个东西. ZooKeeper理念介绍 ZooKeeper是为分布式应用来提供协同服务的,而且Z ...
- Day 23 系统服务之救援模式
1.CentOS6与Centos 7启动流程 4.运行级别C6&C7 0 关机 1 单用户模式 (超级权限 必须面对实体硬件) 2 暂未使用 3 字符界面(黑框) 4 暂未使用 5 图形界面 ...
- Day 22 进程管理2之系统的平均负载
1.管理进程状态 当程序运行为进程后,如果希望停止进程,怎么办呢? 那么此时我们可以使用linux的kill命令对进程发送关闭信号.当然除了kill.还有killall,pkill 1.使用kill ...
- 视频转成在github的readme中展示项目的gif动图
本文中涉及的FastStone Capture和FFmpeg两个软件的百度网盘链接: 链接:https://pan.baidu.com/s/1D5LO9Qmjl-vwJZfnbAloyQ 提取码:56 ...
- 记一个复杂组件(Filter)的从设计到开发
此文前端框架使用 rax,全篇代码暂未开源(待开源) 原文链接地址:Nealyang/PersonalBlog 前言 貌似在面试中,你如果设计一个 react/vue 组件,貌似已经是司空见惯的问题了 ...
- Android Studio [RecyclerView/瀑布流显示]
PuRecyclerViewActivity.java package com.xdw.a122.recyclerview; import android.support.v7.app.AppComp ...
- selenium-01-简介
一.Selenium是什么? Selenium是ThroughtWorks公司一个强大的开源Web功能测试工具系列,本系列现在主要包括以下4款: 1.Selenium Core:支持DHTML的测试案 ...
- 12.Django基础十之Form和ModelForm组件
一 Form介绍 我们之前在HTML页面中利用form表单向后端提交数据时,都会写一些获取用户输入的标签并且用form标签把它们包起来. 与此同时我们在好多场景下都需要对用户的输入做校验,比如校验用户 ...