spark-2.4.0-hadoop2.7-简单操作
1. 说明
本文基于:spark-2.4.0-hadoop2.7-高可用(HA)安装部署
2. 启动Spark Shell
在任意一台有spark的机器上执行
# --master spark://mini02:7077 连接spark的master,这个master的状态为alive,而不是standby
# --total-executor-cores 总共占用2核CPU
# --executor-memory 512m 每个woker占用512m内存
[yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m
-- :: WARN NativeCodeLoader: - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://mini03:4040
Spark context available as 'sc' (master = spark://mini02:7077, app id = app-20181125120746-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information. scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@77e1b84c
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
2.1. 相关截图
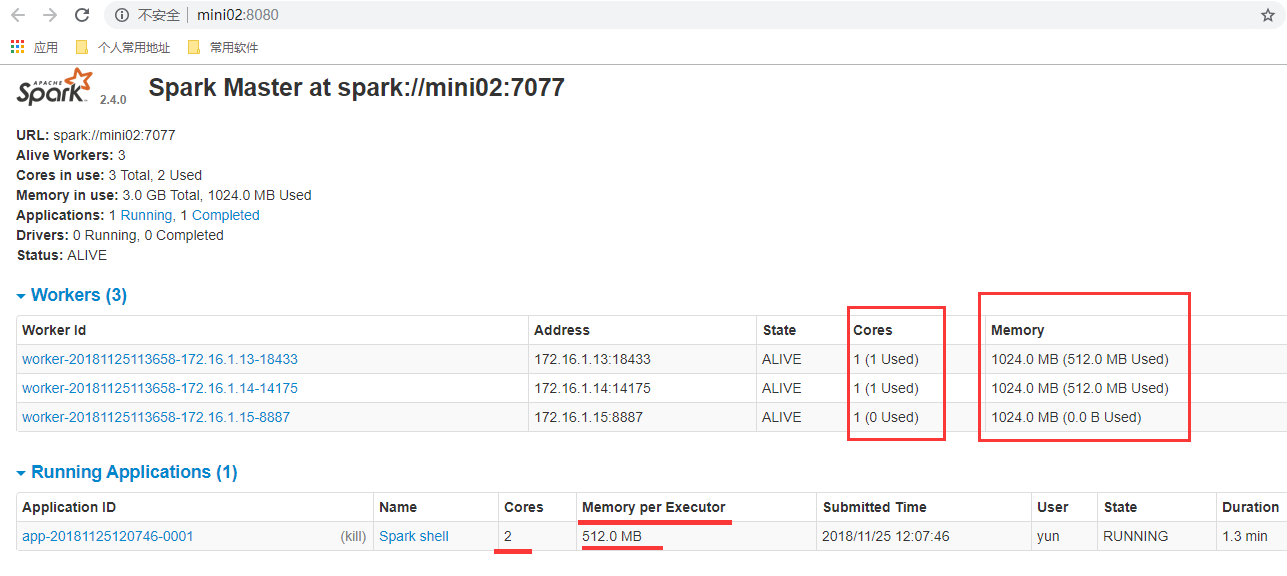
3. 执行第一个spark程序
该算法是利用蒙特•卡罗算法求PI
[yun@mini03 ~]$ spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://mini02:7077 \
--total-executor-cores \
--executor-memory 512m \
/app/spark/examples/jars/spark-examples_2.-2.4..jar
# 打印的信息如下:
-- :: WARN NativeCodeLoader: - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-- :: INFO SparkContext: - Running Spark version 2.4.
………………
-- :: INFO TaskSetManager: - Finished task 97.0 in stage 0.0 (TID ) in ms on 172.16.1.14 (executor ) (/)
-- :: INFO TaskSetManager: - Finished task 98.0 in stage 0.0 (TID ) in ms on 172.16.1.13 (executor ) (/)
-- :: INFO TaskSetManager: - Finished task 99.0 in stage 0.0 (TID ) in ms on 172.16.1.14 (executor ) (/)
-- :: INFO TaskSchedulerImpl: - Removed TaskSet 0.0, whose tasks have all completed, from pool
-- :: INFO DAGScheduler: - ResultStage (reduce at SparkPi.scala:) finished in 3.881 s
-- :: INFO DAGScheduler: - Job finished: reduce at SparkPi.scala:, took 4.042591 s
Pi is roughly 3.1412699141269913
………………
4. Spark shell求Word count 【结合Hadoop】
1、启动Hadoop
2、将文件放到Hadoop中
[yun@mini05 sparkwordcount]$ cat wc.info
zhang linux
linux tom
zhan kitty
tom linux
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /
Found items
drwxr-xr-x - yun supergroup -- : /hbase
drwx------ - yun supergroup -- : /tmp
drwxr-xr-x - yun supergroup -- : /wordcount
-rw-r--r-- yun supergroup -- : /zookeeper-3.4..tar.gz
[yun@mini05 sparkwordcount]$ hdfs dfs -mkdir -p /sparkwordcount/input
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -put wc.info /sparkwordcount/input/.info
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/input
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
-rw-r--r-- yun supergroup -- : /sparkwordcount/input/.info
3、进入spark shell命令行,并计算
[yun@mini03 ~]$ spark-shell --master spark://mini02:7077 --total-executor-cores 2 --executor-memory 512m
# 计算完毕后,打印在命令行
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_).sortBy(_._2, false).collect
res6: Array[(String, Int)] = Array((linux,), (tom,), (kitty,), (zhan,), ("",), (zhang,))
# 计算完毕后,保存在HDFS【因为有多个文件组成,则有多个reduce,所以输出有多个文件】
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output")
# 计算完毕后,保存在HDFS【将reduce设置为1,输出就只有一个文件】
scala> sc.textFile("hdfs://mini01:9000/sparkwordcount/input").flatMap(_.split(" ")).map((_, )).reduceByKey(_+_, ).sortBy(_._2, false).saveAsTextFile("hdfs://mini01:9000/sparkwordcount/output1")
4、在HDFS的查看结算结果
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/
Found items
drwxr-xr-x - yun supergroup -- : /sparkwordcount/input
drwxr-xr-x - yun supergroup -- : /sparkwordcount/output
drwxr-xr-x - yun supergroup -- : /sparkwordcount/output1
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/_SUCCESS
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
-rw-r--r-- yun supergroup -- : /sparkwordcount/output/part-
[yun@mini05 sparkwordcount]$
[yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output/part*
(linux,)
(tom,)
(,)
(zhang,)
(kitty,)
(zhan,)
###############################################
[yun@mini05 sparkwordcount]$ hdfs dfs -ls /sparkwordcount/output1
Found items
-rw-r--r-- yun supergroup -- : /sparkwordcount/output1/_SUCCESS
-rw-r--r-- yun supergroup -- : /sparkwordcount/output1/part-
[yun@mini05 sparkwordcount]$ hdfs dfs -cat /sparkwordcount/output1/part-
(linux,)
(tom,)
(,)
(zhang,)
(kitty,)
(zhan,)
spark-2.4.0-hadoop2.7-简单操作的更多相关文章
- spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0
1.准备: centos 6.5 jdk 1.7 Java SE安装包下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- spark sql的简单操作
测试数据 sparkStu.text zhangxs chenxy wangYr teacher wangx teacher sparksql { ,"job":"che ...
- moloch1.8.0简单操作手册
moloch1.8.0简单操作手册 Sessions 页面:Sessions主要通过非常简单的查询语言来构建表达式追溯数据流量,以便分析. SPIView 页面: SPIGraph页面:SPIGrap ...
- spark 1.1.0 单机与yarn部署
环境:ubuntu 14.04, jdk 1.6, scala 2.11.4, spark 1.1.0, hadoop 2.5.1 一 spark 单机模式 部分操作参考:http://www.cnb ...
- Spark快速入门 - Spark 1.6.0
Spark快速入门 - Spark 1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 快速入门(Quick Start) 本文简单介绍了Spark的使用方式.首 ...
- Apache Spark 2.2.0 中文文档 - Spark 编程指南 | ApacheCN
Spark 编程指南 概述 Spark 依赖 初始化 Spark 使用 Shell 弹性分布式数据集 (RDDs) 并行集合 外部 Datasets(数据集) RDD 操作 基础 传递 Functio ...
- Apache Spark 2.2.0 中文文档 - Spark Streaming 编程指南 | ApacheCN
Spark Streaming 编程指南 概述 一个入门示例 基础概念 依赖 初始化 StreamingContext Discretized Streams (DStreams)(离散化流) Inp ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
随机推荐
- scala中spark运行内存不足
用 bash spark-submit 在spark上跑代码的时候出现错误: ERROR executor.Executor: Exception in task 9.0 in stage 416.0 ...
- CentOS开发ASP.NET Core入门教程
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9891346.html 因为之前一直没怎么玩过CentOS,大多数时间都是使用Win10进行开发,然后程序 ...
- 并发编程(一)—— volatile关键字和 atomic包
本文将讲解volatile关键字和 atomic包,为什么放到一起讲呢,主要是因为这两个可以解决并发编程中的原子性.可见性.有序性,让我们一起来看看吧. Java内存模型 JMM(java内存模型) ...
- Unity实现c#热更新方案探究(三)
转载请标明出处:http://www.cnblogs.com/zblade/ 前面两篇文章从头到尾讲解了C#热更新的一些方案,从程序域来加载和卸载DLL,到使用ILRuntime来实现安卓和IOS平台 ...
- ELK-ElasticSearch索引详解
1.使用_cat API检测集群是否健康,确保9200端口号可用: curl 'localhost:9200/_cat/health?v' 注意:绿色表示一切正常,黄色表示所有的数据可用但是部分副本还 ...
- 一起来看 rxjs
更新日志 2018-05-26 校正 2016-12-03 第一版翻译 过去你错过的 Reactive Programming 的简介 你好奇于这名为Reactive Programming(反应式编 ...
- Spring Boot 2.x(十四):整合Redis,看这一篇就够了
目录 Redis简介 Redis的部署 在Spring Boot中的使用 Redis缓存实战 寻找组织 程序员经典必备枕头书免费送 Redis简介 Redis 是一个开源的使用 ANSI C 语言编写 ...
- Python面向对象:杂七杂八的知识点
为什么有这篇"杂项"文章 实在是因为python中对象方面的内容太多.太乱.太杂,在写相关文章时比我所学过的几种语言都更让人"糟心",很多内容似独立内容.又似相 ...
- 记录:C++类内存分布(虚继承与虚函数)
工具:VS2013 先说一下VS环境下查看类内存分布的方法: 先选择左侧的C/C++->命令行,然后在其他选项这里写上/d1 reportAllClassLayout,它可以看到所有相关类的内存 ...
- 第56章 Client - Identity Server 4 中文文档(v1.0.0)
该Client模型的OpenID Connect或OAuth 2.0 客户端-例如,本地应用,Web应用程序或基于JS的应用程序. 56.1 Basics Enabled 指定是否启用客户端.默认为t ...