运用jieba库 寻找高频词
一、准备
1.首先 先用cmd 安装 jieba库,输入 pip install jieba
2.其次 本次要用到wordcloud库和 matplotlib库,也在cmd输入pip install matplotlib和pip install wordcloud
二、安装完之后,输入如下代码
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
def create_word_cloud(filename):
text = open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding='GBK').read() #打开自己想要的文本
wordlist = jieba.cut(text, cut_all=True) # 结巴分词
wl = " ".join(wordlist)
wc = WordCloud( #设置词云
background_color="white", # 设置背景颜色
max_words=20, # 设置最大显示的词云数
font_path='C:/Windows/Fonts/simfang.ttf', # 索引在C盘上的字体库
height=500,
width=500,
max_font_size=150, # 设置字体最大值
random_state=150, # 设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl) # 生成词云
plt.imshow(myword) # 展示词云图
plt.axis("off")
plt.show()
wc.to_file('img_book.png') # 把词云保存下
txt=open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding='GBK').read() #打开自己想要的文本
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1: #排除单个字符的分词结果
continue
else :
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
word,count=items[i]
print ("{0:<20}{1:>5}".format(word,count))
if __name__ == '__main__':
create_word_cloud('[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上]')

输入之后的界面按下F5
三、运行完毕出现的效果图
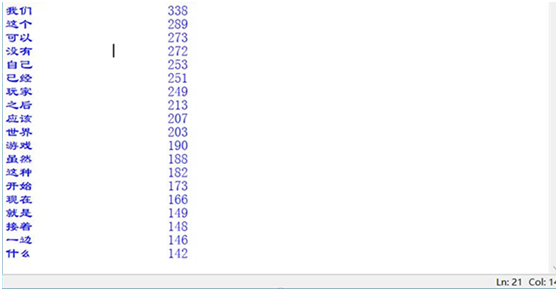
这里是搜索全文的前20个高频词

云词展示 完毕
运用jieba库 寻找高频词的更多相关文章
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- 数字、字符串、列表、字典,jieba库,wordcloud词云
一.基本数据类型 什么是数据类型 变量:描述世间万物的事物的属性状态 为了描述世间万物的状态,所以有了数据类型,对数据分类 为什么要对数据分类 针对不同的状态需要不同的数据类型标识 数据类型的分类 二 ...
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- Jieba库使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- jieba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- jieba库与词云的使用——以孙子兵法为例
1.打开cmd安装jieba库和 matplotlib. 2.打开python,输入代码.代码如下: from wordcloud import WordCloud import matplotlib ...
随机推荐
- redis知识点汇总
1. redis是什么 2. 为什么用redis 3. redis 数据结构 4. redis中的对象类型 5. redis都能做什么?怎么实现的的? 6. redis使用过程中需要注意什么 7. 数 ...
- MariaDB与MySQL
一.MariaDB安装部署 tar zxvf mariadb-5.5.31-linux-x86_64.tar.gz mv mariadb-5.5.31-linux-x86_64 /usr/local/ ...
- parse
import Parse from 'parse'; import { AsyncStorage } from 'react-native'; // 创建新的子类 var GameScore = Pa ...
- PL/SQL数据类型
在定义变量或常量时,必须要指定一个数据类型,PL/SQL是一种静态类型化的程序设计语言,静态类型化又称为强类型化,也就是说类型会在编译时而不是在运行时被检查,这样在编译时便能发现类型错误,以便增强程序 ...
- 算法(第四版)C# 习题题解——2.2
写在前面 整个项目都托管在了 Github 上:https://github.com/ikesnowy/Algorithms-4th-Edition-in-Csharp 查找更为方便的版本见:http ...
- C# 无法将类型为“__DynamicallyInvokableAttribute”的对象强制转换为类型...
错误代码: //遍历方法特性 foreach (MethodInfo m in type.GetMethods()) { foreach(Attribute a in m.GetCustomAttri ...
- Windows 7远程桌面设置
1. 开启防火墙 可在”计算机管理“中,打开"服务和应用程序"-"服务",找到"Windows Firewall",双击"Wind ...
- python文件读书笔记
一.打开文件 1 f=open('text.txt',r) 二.读取文件 print(f.read) 三.关闭文件 f.close() 比较好用的是运用with with open('text.tx ...
- etcd 启动错误
Apr 26 16:17:25 ceph-0 etcd: f281dc69fb4dd3d8 became candidate at term 3574Apr 26 16:17:25 ceph-0 et ...
- Java 基础知识点小结
小知识点 所有的程序,都要定义在类里面: 异常 定义方法时,使用 throws 可以用来捕获方法体内没有捕获的异常,然后以 SomeException 抛出异常 java是解释型语言.java虚拟机能 ...