运用jieba库 寻找高频词
一、准备
1.首先 先用cmd 安装 jieba库,输入 pip install jieba
2.其次 本次要用到wordcloud库和 matplotlib库,也在cmd输入pip install matplotlib和pip install wordcloud
二、安装完之后,输入如下代码
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
def create_word_cloud(filename):
text = open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding='GBK').read() #打开自己想要的文本
wordlist = jieba.cut(text, cut_all=True) # 结巴分词
wl = " ".join(wordlist)
wc = WordCloud( #设置词云
background_color="white", # 设置背景颜色
max_words=20, # 设置最大显示的词云数
font_path='C:/Windows/Fonts/simfang.ttf', # 索引在C盘上的字体库
height=500,
width=500,
max_font_size=150, # 设置字体最大值
random_state=150, # 设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl) # 生成词云
plt.imshow(myword) # 展示词云图
plt.axis("off")
plt.show()
wc.to_file('img_book.png') # 把词云保存下
txt=open("[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上].txt","r",encoding='GBK').read() #打开自己想要的文本
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1: #排除单个字符的分词结果
continue
else :
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
word,count=items[i]
print ("{0:<20}{1:>5}".format(word,count))
if __name__ == '__main__':
create_word_cloud('[轻之国度][川原砾][刀剑神域][01][艾恩葛朗特 上]')

输入之后的界面按下F5
三、运行完毕出现的效果图
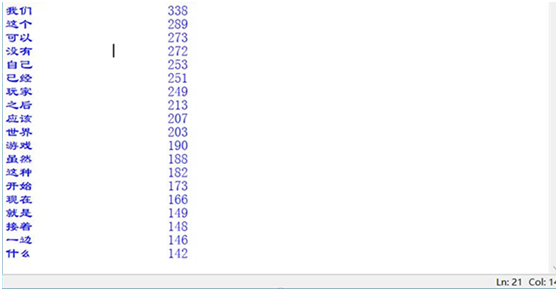
这里是搜索全文的前20个高频词

云词展示 完毕
运用jieba库 寻找高频词的更多相关文章
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- 数字、字符串、列表、字典,jieba库,wordcloud词云
一.基本数据类型 什么是数据类型 变量:描述世间万物的事物的属性状态 为了描述世间万物的状态,所以有了数据类型,对数据分类 为什么要对数据分类 针对不同的状态需要不同的数据类型标识 数据类型的分类 二 ...
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- Jieba库使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- jieba库的使用和好玩的词云
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
- jieba库与词云的使用——以孙子兵法为例
1.打开cmd安装jieba库和 matplotlib. 2.打开python,输入代码.代码如下: from wordcloud import WordCloud import matplotlib ...
随机推荐
- centos安装mariadb
一 配置mariadb官方的yum源 1.进入yum仓库 /etc/yum.repos.d/目录下 手动创建一个 mariadb.repo 写入如下内容 [mariadb] name = Maria ...
- ORA-12557协议适配器不可加载
背景:以前电脑没有装ORACLE,仅是安装了简易客户端,此次想安装一个11g数据库,安装完成后用PLSQL登录,发现报错. 解决方案A:使用免安装的oracle客户端(instantclient_11 ...
- es7,es8
ES7新特性 ES7在ES6的基础上添加了三项内容:求幂运算符(**).Array.prototype.includes()方法.函数作用域中严格模式的变更. Array.prototype.incl ...
- 使用OGG添加唯一标识字段到目标表
利用GoldenGate,可以获取到变更记录在源端对应的redo日志序号,redo中的地址RBA,如果源端是RAC,还可以拿到源端节点的编号,通过这3个值,可以定位该变更记录的唯一性. 这些信息,在G ...
- 基于OpenCV做“三维重建”(0)-- OpenCV3.2+VIZ6.3.0在vs2012下的编译和使用
一.问题提出 ViZ对于显示3维的效果图来说,非常有帮助:我在使用OpenCV进行双目测距的过程中,有一些参数希望能够通过可视化的方法显示出来,所以参考了这方面相关的资料.做了一些实验 ...
- writeup
``` #签到题``` 请打开微信关注,发送give me flag,即可获得.```Encode````1.ACSCLL首先看到这类题,我们肯定是要使用ASCLL的(这么明显的提示大家肯定一眼就能看 ...
- loadrunner常用函数集锦
一.三个复制函数的区别: strcpy 原型:extern char *strcpy(char *dest,char *src);用法:#i nclude功能:把src所指由NULL结束的字符串复制到 ...
- .net core 运行时事件(Runtime Events)
.Net Core 2.2.0 .Net Core 2.2.0已经发布有一段时间了,很多新鲜功能已经有博主介绍了,今天给大家介绍一下运行时事件并附上demo. 运行时事件 通常需要监视运行时服务(如当 ...
- 20165306 Exp6 信息搜集与漏洞扫描
Exp6 信息搜集与漏洞扫描 一.实践内容概述 1.实践目标 掌握信息搜集的最基础技能与常用工具的使用方法. 2.实践内容 (1)各种搜索技巧的应用 搜索网址目录结构 搜索特定类型的文件 搜索E-Ma ...
- 日常安装chocolatey报错此系统上禁止运行脚本
查看计算机上的现用执行策略get-executionpolicy ( 默认:Restricted ) 若要在本地计算机上运行您编写的未签名脚本和来自其他用户的签名脚本,使用以下命令将计算机上的 执行 ...