简单的C#网络爬虫
Source Code: http://download.csdn.net/download/qdalong/10271880
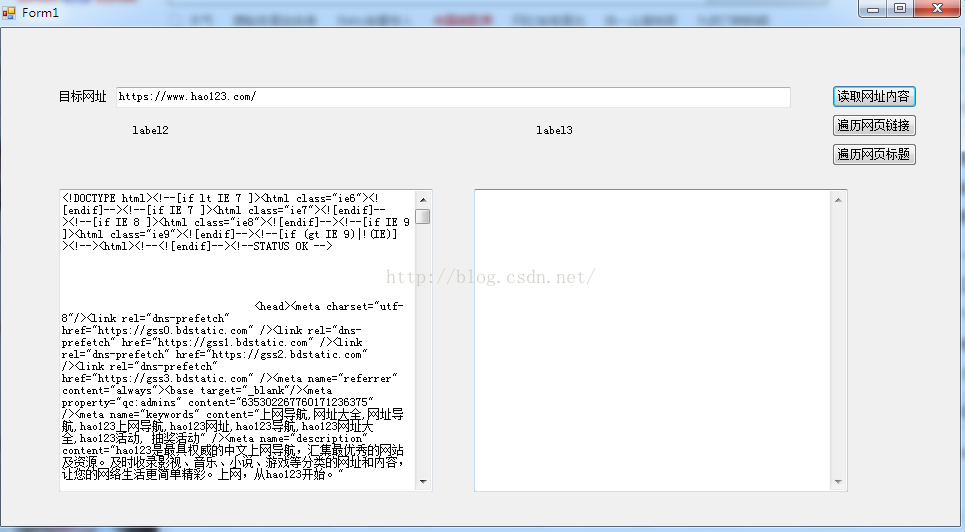
这是爬取网页内容,像是这对大家来说都是不难得,但是在这里有一些小改动,代码献上,大家参考

1 private string GetHttpWebRequest(string url)
2 {
3 HttpWebResponse result;
4 string strHTML = string.Empty;
5 try
6 {
7 Uri uri = new Uri(url);
8 WebRequest webReq = WebRequest.Create(uri);
9 WebResponse webRes = webReq.GetResponse();
10
11 HttpWebRequest myReq = (HttpWebRequest)webReq;
12 myReq.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
13 myReq.Accept = "*/*";
14 myReq.KeepAlive = true;
15 myReq.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5");
16 result = (HttpWebResponse)myReq.GetResponse();
17 Stream receviceStream = result.GetResponseStream();
18 StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("utf-8"));
19 strHTML = readerOfStream.ReadToEnd();
20 readerOfStream.Close();
21 receviceStream.Close();
22 result.Close();
23 }
24 catch
25 {
26 Uri uri = new Uri(url);
27 WebRequest webReq = WebRequest.Create(uri);
28 HttpWebRequest myReq = (HttpWebRequest)webReq;
29 myReq.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
30 myReq.Accept = "*/*";
31 myReq.KeepAlive = true;
32 myReq.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5");
33 //result = (HttpWebResponse)myReq.GetResponse();
34 try
35 {
36 result = (HttpWebResponse)myReq.GetResponse();
37 }
38 catch (WebException ex)
39 {
40 result = (HttpWebResponse)ex.Response;
41 }
42 Stream receviceStream = result.GetResponseStream();
43 StreamReader readerOfStream = new StreamReader(receviceStream, System.Text.Encoding.GetEncoding("gb2312"));
44 strHTML = readerOfStream.ReadToEnd();
45 readerOfStream.Close();
46 receviceStream.Close();
47 result.Close();
48 }
49 return strHTML;
50 }
这是根据url爬取网页远吗,有一些小改动,很多网页有不同的编码格式,甚至有些网站做了反爬取的防范,这个方法经过能够改动也能爬去
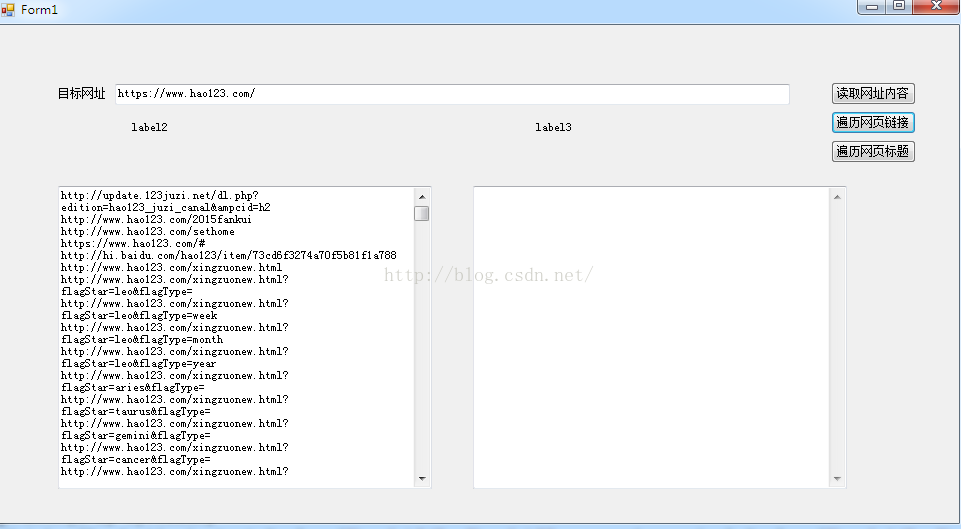
以下是爬取网页所有的网址链接
/// <summary>
/// 提取HTML代码中的网址
/// </summary>
/// <param name="htmlCode"></param>
/// <returns></returns>
private static List<string> GetHyperLinks(string htmlCode, string url)
{
ArrayList al = new ArrayList();
bool IsGenxin = false;
StringBuilder weburlSB = new StringBuilder();//SQL
StringBuilder linkSb = new StringBuilder();//展示数据
List<string> Weburllistzx = new List<string>();//新增
List<string> Weburllist = new List<string>();//旧的
string ProductionContent = htmlCode;
Regex reg = new Regex(@"http(s)?://([\w-]+\.)+[\w-]+/?");
string wangzhanyuming = reg.Match(url, 0).Value;
MatchCollection mc = Regex.Matches(ProductionContent.Replace("href=\"/", "href=\"" + wangzhanyuming).Replace("href='/", "href='" + wangzhanyuming).Replace("href=/", "href=" + wangzhanyuming).Replace("href=\"./", "href=\"" + wangzhanyuming), @"<[aA][^>]* href=[^>]*>", RegexOptions.Singleline);
int Index = 1;
foreach (Match m in mc)
{
MatchCollection mc1 = Regex.Matches(m.Value, @"[a-zA-z]+://[^\s]*", RegexOptions.Singleline);
if (mc1.Count > 0)
{
foreach (Match m1 in mc1)
{
string linkurlstr = string.Empty;
linkurlstr = m1.Value.Replace("\"", "").Replace("'", "").Replace(">", "").Replace(";", "");
weburlSB.Append("$-$");
weburlSB.Append(linkurlstr);
weburlSB.Append("$_$");
if (!Weburllist.Contains(linkurlstr) && !Weburllistzx.Contains(linkurlstr))
{
IsGenxin = true;
Weburllistzx.Add(linkurlstr);
linkSb.AppendFormat("{0}<br/>", linkurlstr);
}
}
}
else
{
if (m.Value.IndexOf("javascript") == -1)
{
string amstr = string.Empty;
string wangzhanxiangduilujin = string.Empty;
wangzhanxiangduilujin = url.Substring(0, url.LastIndexOf("/") + 1);
amstr = m.Value.Replace("href=\"", "href=\"" + wangzhanxiangduilujin).Replace("href='", "href='" + wangzhanxiangduilujin);
MatchCollection mc11 = Regex.Matches(amstr, @"[a-zA-z]+://[^\s]*", RegexOptions.Singleline);
foreach (Match m1 in mc11)
{
string linkurlstr = string.Empty;
linkurlstr = m1.Value.Replace("\"", "").Replace("'", "").Replace(">", "").Replace(";", "");
weburlSB.Append("$-$");
weburlSB.Append(linkurlstr);
weburlSB.Append("$_$");
if (!Weburllist.Contains(linkurlstr) && !Weburllistzx.Contains(linkurlstr))
{
IsGenxin = true;
Weburllistzx.Add(linkurlstr);
linkSb.AppendFormat("{0}<br/>", linkurlstr);
}
}
}
}
Index++;
}
return Weburllistzx;
}
这块的技术其实就是简单的使用了正则去匹配!接下来献上获取标题,以及存储到xml文件的方法
1 /// <summary>
2 /// // 把网址写入xml文件
3 /// </summary>
4 /// <param name="strURL"></param>
5 /// <param name="alHyperLinks"></param>
6 private static void WriteToXml(string strURL, List<string> alHyperLinks)
7 {
8 XmlTextWriter writer = new XmlTextWriter(@"D:\HyperLinks.xml", Encoding.UTF8);
9 writer.Formatting = Formatting.Indented;
10 writer.WriteStartDocument(false);
11 writer.WriteDocType("HyperLinks", null, "urls.dtd", null);
12 writer.WriteComment("提取自" + strURL + "的超链接");
13 writer.WriteStartElement("HyperLinks");
14 writer.WriteStartElement("HyperLinks", null);
15 writer.WriteAttributeString("DateTime", DateTime.Now.ToString());
16 foreach (string str in alHyperLinks)
17 {
18 string title = GetDomain(str);
19 string body = str;
20 writer.WriteElementString(title, null, body);
21 }
22 writer.WriteEndElement();
23 writer.WriteEndElement();
24 writer.Flush();
25 writer.Close();
26 }
27 /// <summary>
28 /// 获取网址的域名后缀
29 /// </summary>
30 /// <param name="strURL"></param>
31 /// <returns></returns>
32 private static string GetDomain(string strURL)
33 {
34 string retVal;
35 string strRegex = @"(\.com/|\.net/|\.cn/|\.org/|\.gov/)";
36 Regex r = new Regex(strRegex, RegexOptions.IgnoreCase);
37 Match m = r.Match(strURL);
38 retVal = m.ToString();
39 strRegex = @"\.|/$";
40 retVal = Regex.Replace(retVal, strRegex, "").ToString();
41 if (retVal == "")
42 retVal = "other";
43 return retVal;
44 }
45 /// <summary>
46 /// 获取标题
47 /// </summary>
48 /// <param name="html"></param>
49 /// <returns></returns>
50 private static string GetTitle(string html)
51 {
52 string titleFilter = @"<title>[\s\S]*?</title>";
53 string h1Filter = @"<h1.*?>.*?</h1>";
54 string clearFilter = @"<.*?>";
55
56 string title = "";
57 Match match = Regex.Match(html, titleFilter, RegexOptions.IgnoreCase);
58 if (match.Success)
59 {
60 title = Regex.Replace(match.Groups[0].Value, clearFilter, "");
61 }
62
63 // 正文的标题一般在h1中,比title中的标题更干净
64 match = Regex.Match(html, h1Filter, RegexOptions.IgnoreCase);
65 if (match.Success)
66 {
67 string h1 = Regex.Replace(match.Groups[0].Value, clearFilter, "");
68 if (!String.IsNullOrEmpty(h1) && title.StartsWith(h1))
69 {
70 title = h1;
71 }
72 }
73 return title;
74 }
简单的C#网络爬虫的更多相关文章
- 简单的Java网络爬虫(获取一个网页中的邮箱)
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; impo ...
- 一个简单的Python网络爬虫(抓图),针对某论坛.
#coding:utf-8 import urllib2 import re import threading #图片下载 def loadImg(addr,x,y,artName): data = ...
- 网络爬虫(java)
陆陆续续做了有一个月,期间因为各种技术问题被多次暂停,最关键的一次主要是因为存储容器使用的普通二叉树,在节点权重相同的情况下导致树高增高,在进行遍历的时候效率大大降低,甚至在使用递归的时候导致栈 ...
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- 网络爬虫与搜索引擎优化(SEO)
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引. ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- 13. Go 语言网络爬虫
Go 语言网络爬虫 本章将完整地展示一个应用程序的设计.编写和简单试用的全过程,从而把前面讲到的所有 Go 知识贯穿起来.在这个过程中,加深对这些知识的记忆和理解,以及再次说明怎样把它们用到实处.由本 ...
- python网络爬虫进入(一)——简单的博客爬行动物
最近.对于图形微信公众号.互联网收集和阅读一些疯狂的-depth新闻和有趣,发人深思文本注释,并选择最佳的发表论文数篇了.但看着它的感觉是一个麻烦的一人死亡.寻找一个简单的解决方案的方法,看看你是否可 ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
随机推荐
- linux ps aux 各列内容说明
[root@zabbix3 ~]# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot ...
- flutter-开发总结
### 上拉加载下拉刷新 ``` import 'dart:async'; import 'package:flutter_easyrefresh/easy_refresh.dart'; import ...
- 2018年NGINX最新版高级视频教程
2018年NGINX最新版高级视频教程,想要的联系我,QQ:1844912514
- LVS结合keepalive
LVS可以实现负载均衡,但是不能够进行健康检查,比如一个rs出现故障,LVS 仍然会把请求转发给故障的rs服务器,这样就会导致请求的无效性.keepalive 软件可以进行健康检查,而且能同时实现 L ...
- linux定时备份学习笔记
1.iterm2链接远程中文乱码 shh端vi ~/.bash_profile export LC_CTYPE=en_US.UTF-8 source ~/.bash_profile 2.WARNI ...
- 在Asp.Net Core中集成Kafka
在我们的业务中,我们通常需要在自己的业务子系统之间相互发送消息,一端去发送消息另一端去消费当前消息,这就涉及到使用消息队列MQ的一些内容,消息队列成熟的框架有多种,这里你可以读这篇文章来了解这些MQ的 ...
- windows编程 进程的创建销毁和分析
Windows程序设计:进程 进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动,在Windows编程环境下,主要由两大元素组成: • 一个是操作系统用来管理进程的内核对象.操作系统使用内 ...
- Spring 框架中注释驱动的事件监听器详解
事件交互已经成为很多应用程序不可或缺的一部分,Spring框架提供了一个完整的基础设施来处理瞬时事件.下面我们来看看Spring 4.2框架中基于注释驱动的事件监听器. 1.早期的方式 在早期,组件要 ...
- VBS 备份文件
http://www.cnblogs.com/top5/archive/2009/11/17/1604767.html 参考上面的博客 ' =============== 局域网文件自动备份 VBS ...
- docker报错:Get https://registry-1.docker.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
在github上开到这样一条 于是 这两个选项换着来 具体怎么回事,咱也不知道,咱也不敢问 改完后蹭蹭的