第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
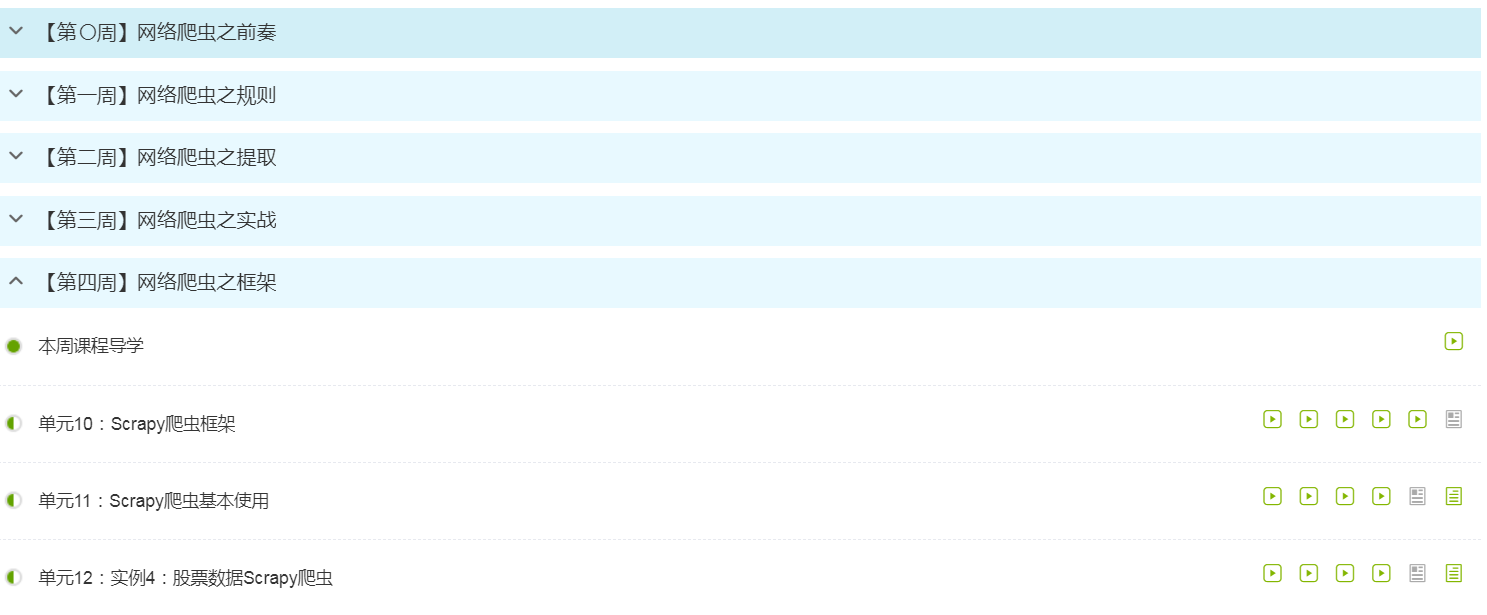
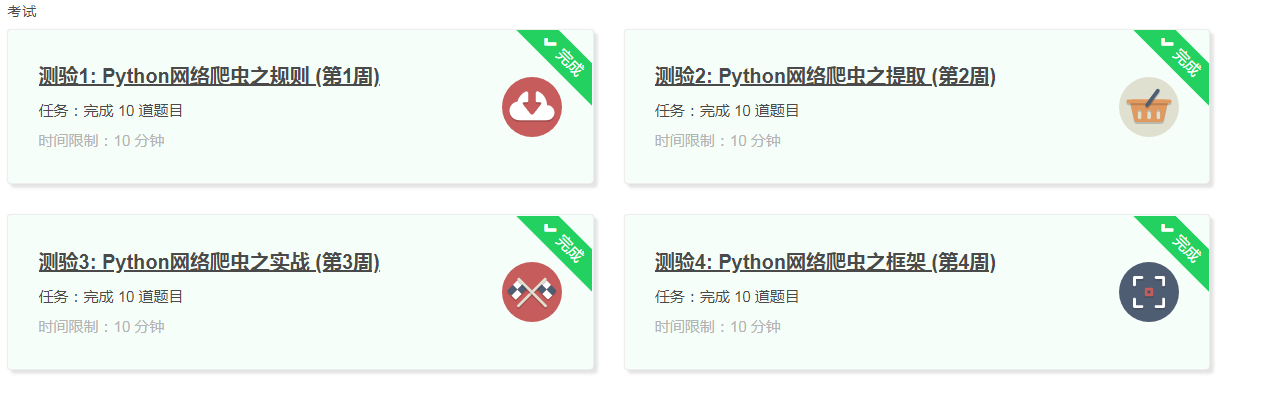
3.学习完成第0周至第4周的课程内容,并完成各周作业
 过程。
过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过学习python网络爬虫与信息提取,对于python的了解更多了,这个网课上的很详细,老师讲的也很细致。通过这个课程我也知道了很多以前没有接触到的知识,我知道了什么是网络爬虫以及爬虫有什么作用,我都有去做了下功课。网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。爬虫可以作为通用搜索引擎网页收集器,做垂直搜索引擎,并且科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
Python网络爬虫是可以跨平台,对对Linux和windows都有不错的支持;科学计算,数值拟合:Numpy,Scipy;可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2;复杂网络:Networkx;统计:与R语言接口:Rpy。用python写爬虫是为了满足“抓数据”的需求,使用爬虫软件更为方便,不用把时间花在解析网页上、测试程序上以及处理防采集上。
python网络爬虫与信息是有五个框架,每一个都有自己的特点。Requests框架:自动爬取HTML页面与自动网络请求提交;robots.txt:网络爬虫排除标准;BeautifulSoup框架:解析HTML页面;Re框架:正则框架,提取页面关键信息;Scrapy框架:网络爬虫原理,专业爬虫框架介绍。而requests库是目前公认的爬取网页最好的python第三方库,特点是简单。Python网络爬虫的主要方法有很多,其中request()是构造一个请求,是支撑各方法的基础;get()是获取html网页的主要方法,对应的是http的get;head()是获取html网页头的信息方法,对应的是http的head ;post() 是向html网页提交post请求,对应的是http的post;put()是向html网页提交put请求,对应的是http的put;patch()是向html页面提交局部修改请求,对应的是http的patch;而delete()是向html页面提交删除请求,对应的是http的delete。
response对象的属性有五种,r.status_code是http请求返回的状态,200表示链接成功,404表示失败;r.text是http响应内容的字符串形式,即,url对应的页面内容;r.encoding是从http header中获取对应的内容编码形式 ;r.apparent_encoding是从内容中分析的响应内容编码方式;r.content是http响应的内容的二进制形式。
Python的内容多式多样,是学无止境的,要学好这门课程,是需要长时间的钻研,仅仅靠这个课程是远远不够的。在这里面我们学到了很多书本以外的知识,这都是一种收获,老师上的课也都很详细,把每一个知识点都有讲透,并且呈现出来,让我对python的兴趣多了一点。中国大学生慕课也是一个好的平台,能让更多人可以学习,通过这个平台去了解更多的知识,让自己的专业知识更加丰富。
第三次作业-Python网络爬虫与信息提取的更多相关文章
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- Python网络爬虫与信息提取(三)—— Re模块
regular expression / regex / RE 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配.Python 自1.5版本起增加了re 模块,它提供 ...
- Python网络爬虫与信息提取(二)—— BeautifulSoup
BeautifulSoup官方介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 官方 ...
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
随机推荐
- 从壹开始 [ Ids4实战 ] 之六 ║ 统一角色管理(上)
前言 书接上文,咱们在上周,通过一篇<思考> 性质的文章,和很多小伙伴简单的讨论了下,如何统一同步处理角色的问题,众说纷纭,这个我一会儿会在下文详细说到,而且我最终也定稿方案了.所以今天咱 ...
- sign in with apple后端校验(java)
最近新开发的ios平台的app在提审的时候,被拒了,原因是app上如果有接第三方登陆(比如,微信,微博,facebook等),那就必须要接apple id登陆,坑爹~苹果霸权啊!然而没办法,靠他吃饭, ...
- day 39 盒模型 display 浮动
一.盒模型 属性: width:内容的宽度 height:内容的高度 padding:内边距 内容到边框的距离 border:边框 margin:外边距 另一个边到另一个边的距离 盒模型的计算: 总结 ...
- python接口设计中的__all__和del
最近在实现python接口中遇到了一些小问题,解决后总结如下. 目的:在设计接口时,只暴露某个文件的特定方法. 例如: t.py import os import sys def a(): pass ...
- 01-tornado学习笔记-Tornado简介
01-Tornado简介 Tornado是使用Python编写的一个强大的.可扩展的Web服务器.它在处理严峻的网络流量时表现得足够强健,但却在创建和编写时有着足够的轻量级,并能够被用在大量的应用 ...
- ip地址计算
1.多少个子网? 2x个,其中x为被遮盖(取值为1)的位数.例如,在11000000(这个值是子网掩码的最后几位,例如,mask=18)中,取值为1的位数为2,因此子网数位22=4个: 2.每个子网包 ...
- 跨平台c开发库tbox:内存库使用详解
TBOX是一个用c语言实现的跨平台开发库. 针对各个平台,封装了统一的接口,简化了各类开发过程中常用操作,使你在开发过程中,更加关注实际应用的开发,而不是把时间浪费在琐碎的接口兼容性上面,并且充分利用 ...
- python的遗传算法--Hello World入门篇
本系列文章代码取材于书籍<Genetic Algorithms with Python>,本人是在校电气专业的研究生,立志从事于Python相关的代码工作,具体什么方向还有待深究. 众所周 ...
- java基础(3)--详解String
java基础(3)--详解String 其实与八大基本数据类型一样,String也是我们日常中使用非常频繁的对象,但知其然更要知其所以然,现在就去阅读源码深入了解一下String类对象,并解决一些我由 ...
- Python基础班学习笔记
本博客采用思维导图式笔记,所有思维导图均为本人亲手所画.因为本人也是初次学习Python语言所以有些知识点可能不太全. 基础班第一天学习笔记:链接 基础班第二天学习笔记:链接 基础班第三天学习笔记:链 ...