学习java23种设计模式自我总结
首先先做个广告,以前看过@maowang 这位大神转的Java开发中的23种设计模式详解(转) ,但是看了之后都忘差不多了,
所以,开个帖子边学习边自我总结(纯手敲)。一直以来像这种需要长久的运动,真得很少有坚持下来的,希望这次一定坚持下来,再此立贴为证!!!
2018-3-27
一:设计模式六大原则
1:开闭原则
总的来说对扩展开放,对修改关闭。实现热插拔。想要达到这样的效果需使用抽象类和接口。
2:里氏代换原则
里氏代换原则面向对象的基本设计原则之一(好吧我不太懂),里氏代换原则中的说,任何基类(个人理解为父类)可以出现的地方其子类一定可以出现。LSP(里氏代换原则)是继承 复用的基石,只有当子类可以替换掉父类,软件的功能不收影响时,父类才能真正的被复用,而子类能够在父类的基础上增加新的行为。LSP原则就是对“开闭”原则的补充。实现开闭原则的关键性步骤就是抽象化(就是面向接口编程),而父类和子类的继承关系就是抽象化的具体实现,所以里氏代换原则就是对实现抽象化的具体步骤的规范(好吧,摘自百度);背了一遍理解加深了好多。
3:依赖倒转原则
依赖倒转是开闭原则的基础,具体内容:真对接口编程,依赖于抽象而不依赖于具体。
4:接口隔离原则
这个原则的意思是:使用多个隔离的接口比使用单个接口要好。是一个降低类之间的耦合度的意思,所谓耦合度就是类与类代码与代码之间的关联。从这我们看出,其实设计模式就是一个软件的设计思想,从大型软件架构出发,为了升级和维护方便。所以本文中还会多次出现:降低依赖,降低耦合。
5:迪米特法则(最少知道法则)
为什么叫最少知道法则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使系统功能模块相互独立。
6:合成复用原则
原则就是尽量使用合成/复用的方式,而不是使用继承。(我真不知道什么是合成和复用QAQ)
合成/复用就是在一个新的对象里来使用一些已有的对象,使之成为新对象的一部分,新对象通过委派调用已有对象的方法以达到复用功能的目的。总之即:复用时尽量使用组合复合关系(关联关系),尽量少的减少继承关系。个人理解一下,就是说是在一个对象里面使用其他类对象的实体(也成为成员对象)。个人理解不知道是否准确,有大神看到这里希望能帮小弟解下惑。
因为组合或复合关系可以将已有的对象纳入到新对象中,使之成为新对象的一部分,因此新对象可以调用已有对象的功能,而还可以使得已有成员对象的内部实现细节对于新对象不可见,所以这种复用又称为“黑箱复用”,相对继承关系而言,其耦合度较低,成员对象的变化对新对象的影响不大。可以再新对象中有选择性的调用需要的成员对象。---来自百度
OK,明白了,进行下一步。下面是满满的干货
二: java的23种设计模式
1:工厂方法模式
工厂方法模式分为三种分别为:普通工厂模式,多个工厂方法模式,静态工厂方法模式
1.1普通工厂模式:普通工厂模式就是创建一个工厂类,对实现了同一接口的类进行实例的创建。
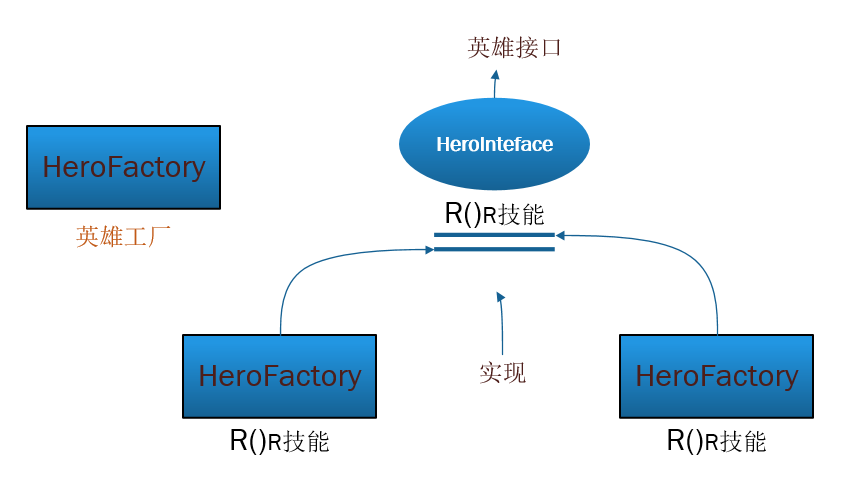
下面来段代码举例,模拟英雄联盟吧~hohoho
图画错了,下面两个方块里面分别是Hero_Catalina和Hero_Galen而不是HeroFactory
首先创建一个英雄接口Hero,有一释放大招的方法R();
[java]
1.public interface Hero {
2. public void R();
3.}
然后创建两个实现类 盖伦英雄卡特琳娜,实现该接口
public class Hero_Galen implements Hero {
@Override
public void R() {
System.out.println("释放终极必杀:德玛西亚正义");
}
}
public class Hero_Catalina implements Hero {
@Override
public void R() {
System.out.println("释放终极必杀:死亡莲华");
}
}
最后建工厂类
public class HeroFactory {
public Hero getHero(String heroName){
if("盖伦".equals(heroName)){
return new Hero_Galen();
}else if("卡塔琳娜".equals(heroName)){
return new Hero_Catalina();
}else{
System.out.println("你尚未拥有该英雄!!");
return null;
}
}
}
测试类
public static void main(String[] args) {
HeroFactory factory = new HeroFactory();
Hero hero = factory.getHero("卡特琳娜");
hero.R();
}
输出结果:释放终极必杀:死亡莲华
1.2 多个工厂方法模式:这里不是说多个工厂,重要的是工厂里的多个方法!!!我们发现在普通工厂模式中如果传入字符串错误就会出错,不能正确的创建对象。而多个工厂方法模式是对普通工厂模式的改进,在工厂类中提供多个方法分别进行对象的创建。
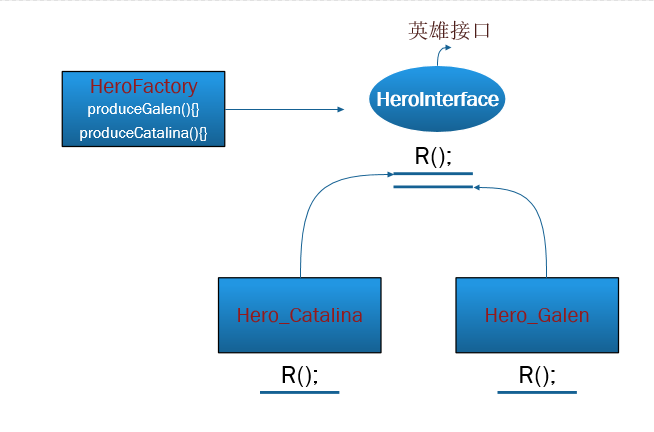
将上面的代码稍作修改,只改动HeroFactory工厂类就行了。代码如下:
public class HeroFactory {
public Hero procudeGalen(){
return new Hero_Galen();
}
public Hero procudeCatalina(){
return new Hero_Catalina();
}
}
测试类:
public class HeroTest {
public static void main(String[] args) {
HeroFactory factory = new HeroFactory();
Hero hero = factory.procudeCatalina();
Hero hero1 = factory.procudeGalen();
hero.R();
hero1.R();
}
}
输出结果:
释放终极必杀:死亡莲华
释放终极必杀:德玛西亚正义
1.3 静态工厂方法模式:顾名思义,只需将上面多个工厂方法模式中的方法改为静态的,这样不需要创建实例即可使用。
改动HeroFactory工厂类中的方法为静态方法:
public class HeroFactory {
public static Hero procudeGalen(){
return new Hero_Galen();
}
public static Hero procudeCatalina(){
return new Hero_Catalina();
}
}
测试类:
public class HeroTest {
public static void main(String[] args) {
Hero hero = HeroFactory.procudeGalen();
hero.R();
}
}
输出结果:
释放终极必杀:德玛西亚正义
好吧,昨天上班时间没有抽出来空更新,今天开始更新吧。
2:抽象工厂模式(Abstract Factory)
经过学习工厂模式我们发现工厂模式有一个弊端就是,类的创建依赖与工厂类,也就是说想要拓展程序必须对工厂类进行修改,这就违背了我们的开闭原则,那么如何解决这一问题呢?这就用到了抽象工厂模式,创建一个工厂接口,然后创建多个工厂类,每个工厂类分别创建不同的对象。这样一旦需要添加新的功能对象只需要添加一个新的工厂类来创建该对象,而不需要修改以前的代码。如图:
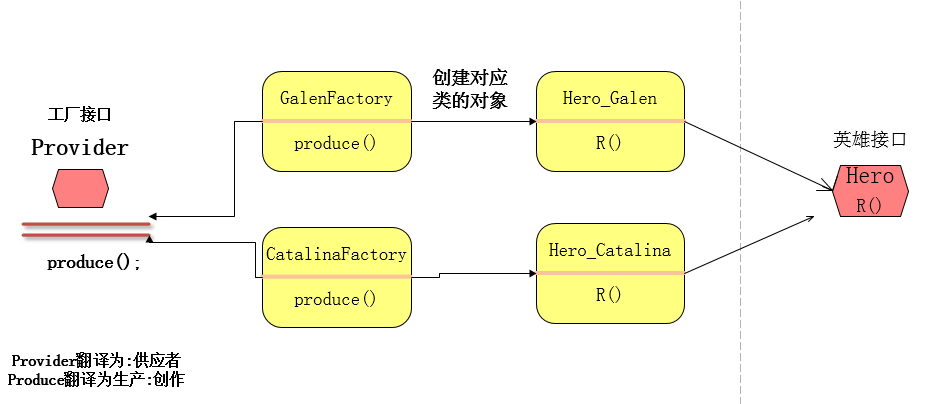
来段代码加深印象:
首先是一个英雄接口Hero:
public interface Hero {
public void R();
}
两个或N个实现类
public class Hero_Galen implements Hero {
@Override
public void R() {
System.out.println("释放终极必杀:德玛西亚正义");
}
}
//卡特琳娜
public class Hero_Catalina implements Hero {
@Override
public void R() {
System.out.println("释放终极必杀:死亡莲华");
}
}
工厂接口
public interface Provider {
public Hero produce();
}
两个工厂类实现工厂接口
public class GalenFactory implements Provider {
@Override
public Hero produce() {
return new Hero_Galen();
}
}
public class CatalinaFactory implements Provider {
@Override
public Hero produce() {
return new Hero_Catalina();
}
}
测试类:
public class HeroTest {
public static void main(String[] args) {
Provider provider = new CatalinaFactory();
Hero hero = provider.produce();
hero.R();
}
}
输出结果为:释放终极必杀:死亡莲华
经过例子,再结合之前的工厂模式我发现:1、普通工厂模式,是在一个工厂类的一个方法里面通过传入字符串的不同来创建不同的对象;
2、多个工厂方法模式/静态工厂方法模式,是通过不同的方法来创建不同的对象,不用担心字符串传错的问题;
3、抽象方法模式是把工厂类作为一个接口,由多个实现改接口的子工厂类来创建不同的对象,扩展性能更好,符合我们的开闭模式;
3:单例模式(Singleton)
单例模式是一种常用的设计模式。单例对象可以保证,在JVM运行中,但对象只有一个实力存在,这样的模式有几个好处:
1:某些类创建比较频繁,对于一些大型的对象,省去一笔很大的系统开销
2:省去 new 操作符,降低了系统内存的使用频率,减轻GC压力。
3:有些类如交易所的核心交易引哈哈0擎,控制着交易流程,如果该类可以创建多个的话,系统就完全乱了。(就像一个国家有两个皇帝,那就乱套了)所以这时候就需要使用单例模式,才能保证核心交易服务器独立控制整个流程。
常见的单例模式分为两种:
其一为:懒汉式单例模式;其二为:饿汉式单例模式
懒汉式单例模式:在类加载时不初始化。
饿汉式单例模式:在类加载时就完成实例的初始化,所以类加载比较慢,但获取对象的速度快。
首先我们先写一个简单的单例类:
懒汉式线程不安全单例类:
public class Singleton {
//静态的私有的全局变量,赋值为null,私有的是为了防止被直接调用,赋
//值为null,目的是实现延迟加载
private static Singleton instance = null;
//私有的构造方法,无法从外部直接实例化
private Singleton(){
}
//静态的工程方法用于创建实例
public static Singleton getInstance() {
if (instance == null) {
instance=new Singleton();
}
return instance;
}
这一种懒汉式基本可以满足我们的需求,但是这样毫无线程安全保护的类,如果我们把她放在多线程的环境下,那么肯定就会出现问题了。(这一点我刚看到的时候是迷茫的,多线程情况下她会出现什么样的问题呢?考虑了好久,最终用代码,来检测了出来),代码如下:
懒汉式线程不安全单例模式在多线程环境下:
单例类:
public class Singleton {
//静态的私有的全局变量,赋值为null,私有的是为了防止被直接调用,赋值为null,目的是实现延迟加载
private static Singleton instance = null;
private int i;
//私有的构造方法,无法从外部直接实例化
private Singleton(){
System.out.println("=======================注意,实例化了一次哦=======================");
}
//静态的工程方法用于创建实例
public static Singleton getInstance() {
if (instance == null) {
instance=new Singleton();
}
return instance;
}
public synchronized void init(int i){
this.i=i;
System.out.println("线程"+i);
}
}
我们在构造函数中让他输出一句话,然后写一个方法,做线程监测。然后我是在junit环境下做多线程测试。
线程类:
public class MyThread implements Runnable{
private int i;
private CountDownLatch count;
public MyThread() {
super();
}
public MyThread(int i,CountDownLatch count) {
this.i = i;
this.count=count;
}
@Override
public void run() {
try {
count.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Singleton sin = Singleton.getInstance();
sin.init(i);
}
}
测试类:
//线程发令枪,用于模拟多线程的并发,这里设置50个并发量
private CountDownLatch count = new CountDownLatch(50);
@Test
public void test(){
for(int i=0;i<50;i++){
new Thread(new MyThread(i,count)).start();
count.countDown();
}
try {
//阻塞线程,等待所有线程执行完毕
Thread.currentThread().join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
输出结果为:

我们做单例模式是为了保持JVM中只有一个该类的实力,理论上来说懒汉式单例模式也能做到。可是这里我们却看到在多个线程并发的情况下,50个线程同时怼到单例模式的类的时候,我们的单例类却被实例化的多次,这就是懒汉式在多线程下的不安全因素。
如何解决呢?我们首先会想到对getInstance()方法加synchronized关键字,如下:
public static synchronized Singleton getInstance() {
if (instance == null) {
instance=new Singleton();
}
return instance;
}

看下结果,确实达到我们的预想了。但是,synchronized关键字锁住的是这个对象,这样的用法,在性能上会有所下降,因为每次调用getInstance(),都要对对象上锁。所以我们会想到,只有在第一次创建对象的时候需要加锁,之后就不需要了,所以,这个地方需要改进。我们改成下面这个,懒汉多线程方法:
public static Singleton getInstance() {
if (instance == null) {
synchronized (instance) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
看起来似乎是解决了之前的问题,将synchronized加在了方法内部,也就是说当调用getInstance()方法的时候,是不需要加锁的,之后instance为null,且创建对象的时候需要加锁,性能也有了很大的提升。这样的情况还是会有可能出问题的,看咱们的输出结果如下:
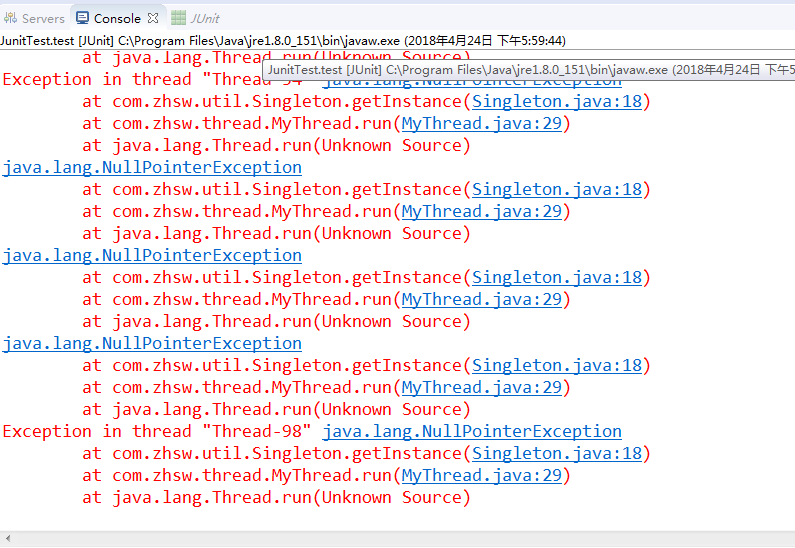
我们发现竟然报了许多空指针NullPointerException,原来java中创建对象和赋值操作是分开执行的,也就是说 instance = new Singleton();这一句代码是分两步完成的。但是jvm并不能保证这两个操作的先后顺序,也就是说执行这一句代码的时候有可能,JVM先为新的Singleton分配实例空间,然后直接赋值给instance成员,最后才去初始化化Singleton的实例,这样肯定就会出错了,举个栗子:
a> 有A、B两个线程同时进入了第一个if判断
b> A首先进入了synchronized块,由于instance为null,它执行了instance = new Singleton()
c> 由于JVM的内部优化机制,JVM先画出了一些分配给Singleton的空白内存并赋值给了instance成员,注意这时候没有初始化Singleton实例,随后A线程离开了
d> 随后B线程进入到synchronized块,由于instance块这时候并不为空,所以B线程离开了,并将结果返回个调用它的程序
e> 此时B线程打算使用Singleton实例,却发现它还没被初始化,这时错误发生了。
所以程序还是有可能发生错误,其实程序在运行过程是很复杂的,从这点我们就可以看出,尤其是在写多线程环境下的程序更有难度。
我们对该程序做进一步优化:
即:饿汉式(静态常量)[可用] 代码如下
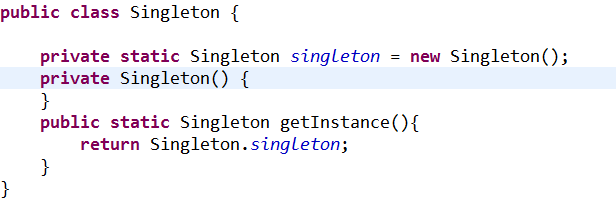
优点:这种写法比较简单、在类装在的时候就完成了Singleton的初始化,避免了线程同步的问题。
缺点:这种写法的缺点,因为在类装载时就完成了类的初始化,没有达到layz loading的效果,如果从来没有用过这个类就造成了资源的浪费
实际情况是,单例模式中我们使用内部类来维护单例的实现,JVM内部的机制能够保证当一个类被加载的时候,这个类的加载过程是线程互斥的。当我们第一次调用getInstance,JVM加载内部类,并且只创建一次,并且会保证吧赋值给instance的内存初始化完毕,这样我们就不用担心上面的问题。同时内部类只有在外部类被调用时才会加载,并且产生实例。
代码如下:
public class Singleton {
private Singleton() {
}
/**
* 创建实例方法
* @return
*/
public static Singleton getInstance(){
return Inner.SINGLETON;
}
/**
* 静态内部类,负责初始化
*/
public static class Inner{
private static final Singleton SINGLETON = new Singleton();
}
/**
* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致
* @return
*/
public Object readResolve() {
return getInstance();
}
}
静态内部类虽然保证了单例在多线程并发下的线程安全性,但是在遇到序列化对象时,默认的方式运行得到的结果就是多例的。这种情况不多做说明了,使用时请注意。
也有人这样实现:因为我们只需要在创建类的时候进行同步,所以只要将创建和getInstance()分开,单独为创建加synchronized关键字,也是可以的:
public class SingletonTest {
private static SingletonTest instance = null;
private SingletonTest() {
}
private static synchronized void syncInit() {
if (instance == null) {
instance = new SingletonTest();
}
}
public static SingletonTest getInstance() {
if (instance == null) {
syncInit();
}
return instance;
}
}
考虑性能的话,整个程序只需创建一次实例,所以性能也不会有什么影响。
补充:采用"影子实例"的办法为单例对象的属性同步更新
public class SingletonTest {
private static SingletonTest instance = null;
private Vector properties = null;
public Vector getProperties() {
return properties;
}
private SingletonTest() {
}
private static synchronized void syncInit() {
if (instance == null) {
instance = new SingletonTest();
}
}
public static SingletonTest getInstance() {
if (instance == null) {
syncInit();
}
return instance;
}
public void updateProperties() {
SingletonTest shadow = new SingletonTest();
properties = shadow.getProperties();
}
}
通过单例模式的学习告诉我们:
1、单例模式理解起来简单,但是具体实现起来还是有一定的难度。
2、synchronized关键字锁定的是对象,在用的时候,一定要在恰当的地方使用(注意需要使用锁的对象和过程,可能有的时候并不是整个对象及整个过程都需要锁)。
到这儿,单例模式基本已经讲完了,结尾处,笔者突然想到另一个问题,就是采用类的静态方法,实现单例模式的效果,也是可行的,此处二者有什么不同?
首先,静态类不能实现接口。(从类的角度说是可以的,但是那样就破坏了静态了。因为接口中不允许有static修饰的方法,所以即使实现了也是非静态的)
其次,单例可以被延迟初始化,静态类一般在第一次加载是初始化。之所以延迟加载,是因为有些类比较庞大,所以延迟加载有助于提升性能。
再次,单例类可以被继承,他的方法可以被覆写。但是静态类内部方法都是static,无法被覆写。
最后一点,单例类比较灵活,毕竟从实现上只是一个普通的Java类,只要满足单例的基本需求,你可以在里面随心所欲的实现一些其它功能,但是静态类不行。从上面这些概括中,基本可以看出二者的区别,但是,从另一方面讲,我们上面最后实现的那个单例
模式,内部就是用一个静态类来实现的,所以,二者有很大的关联,只是我们考虑问题的层面不同罢了。两种思想的结合,才能造就出完美的解决方案,就像HashMap采用数组+链表来实现一样,其实生活中很多事情都是这样,单用不同的方法来处理问题,总是有
优点也有缺点,最完美的方法是,结合各个方法的优点,才能最好的解决问题!
4:建造者模式
工厂类模式提供的是创建单个类的模式,而建造者模式则是将各种产品集中起来管理,用来创建符合对象,所谓符合对象就是指某个类具有不同的属性,其实建造者模式就是前面抽象工厂模式和最后的Test结合起来的到的,看下源代码分析吧:
首先和前面一样,一个英雄接口和一个方法,两个实现类Galen和Catalina
/**
* 功能接口
*/
public interface HeroInterface {
void R();
}
public class Catalina implements HeroInterface {
@Override
public void R() {
System.out.println("卡特琳娜:死亡莲华");
}
}
public class Galen implements HeroInterface {
@Override
public void R() {
System.out.println("盖伦:德玛西亚正义");
}
}
然后建造者类源码如下:
/**
* 建造类
*/
public class Builder {
private List<HeroInterface> heroList = new ArrayList<>();
public List<HeroInterface> getHeroList() {
return heroList;
}
public void setHeroList(List<HeroInterface> heroList) {
this.heroList = heroList;
} public void buildGalen(int num){
for(int i = 0;i<num;i++){
heroList.add(new Galen());
}
} public void buildCatalina(int num){
for(int i = 0;i<num;i++){
heroList.add(new Catalina());
}
}
}
测试类:
public class Test {
public static void main(String[] args){
Builder builder = new Builder();
builder.buildCatalina(10);
List<HeroInterface> list = builder.getHeroList();
for (HeroInterface hero:list) {
hero.R();
}
}
}
从这点可以看出,建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以建造者模式与工厂模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注创建符合对象,多个部分。因此,选择工厂模式还是建造者模式,依实际情况而定。
5.原型模式
原型模式创建性模式之一,但是与工厂模式并没有关系,从名字可以看出。在使用原型模式时我们首先需要创建一个原型对象,在通过复制这个原型对象来创建更多同类型的对象。试想,如果孙悟空的模样都不知道,又该如何拔毛变小猴子呢,哈啊哈哈!!!
原型模式的核心思想是将一个对象作为原型对其进行复制、克隆,产生一个与原对象类似的新对象。定义如下:
原型模式是使用原型实例制定创建对象的类型,并且通过这些原型创建新的对象。原型模式是一种创建型模式。
原型对象的工作原理很简单:将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求让原型对象来拷贝它自己来实现创建过程。由于在软件系统中我们经常会遇到创建多个相同或者类似对象的情况,因此原型模式在真实开发环境中的使用频率还是非常高的。原型模式是一种另类的创建型模式,创建克隆对象的工厂就是原型类自身,工厂方法由克隆方法来实现。
需要注意的是通过克隆方法clone()所创建的对象是全新的对象,他们在内存中拥有新的地址,如果我们对克隆所产生的对象修改时,对原型对象不会造成任何的影响,每一个克隆对象都是相互独立的。通过不停的方式修改可以得到一系列相似但是不完全相同的对象。
本节常用单词:
Prototype: 原型 Client :委托人 operation: 操作、经营 Concrete:具体的、具体物
原型模式结构图:
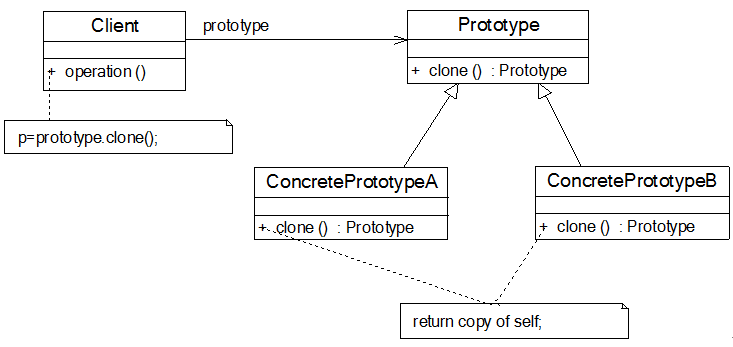
在原型模式结构图中包含如下几个角色:
●Prototype(抽象原型类):Prototype是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至还可以是具体的实现类。
●ConcretePrototype(具体原型类):ConcretePrototype实现在抽象原型类中声明的克隆方法,在克隆方法中返回一个自己的克隆对象。
●Client(客户类):让一个原型对象克隆自身从而创建一个新的对象,在客户类中只需要 直接实例化或通过工厂方法等方式创建一个原型对象,在通过调用该对象的克隆方法即可得到多个相同的对象。由于客户类中只需要直接实例化或通过工厂方法等方式创建一个原型对象,在通过调用该对象的克隆方法即可得到多个相同的对象。由于客户类针对抽象圆形类Prototype编程,因此用户可以根据需要选择具体原型类,系统具有较好的可扩展性,增加或更换具体原型类都很方便。
原型模式的核心在于如何实现克隆方法,下面将介绍两种在JAVA语言中常用的克隆实现方法:
1.通用实现方法
通用的克隆实现方法是在具体原型类的克隆方法中实例化一个与自身类型相同的对象,并将其返回,并将相关的参数传入新创建的对象中,保证他们的成员属性相同。例:
Prototype:原型接口
public interface Prototype {
void setStr(String str);
String getStr();
Prototype clone();
}
ConcretePrototype:具体原型类
实现在抽象原型类中声明的克隆方法,在克隆方法中返回一个自己的克隆对象。代码如下:
/**
* 具体原型类--通用克隆方法
*/
public class ConcretePototype implements Prototype {
private String attr;//成员属性
public String getAttr() {
return attr;
}
public void setAttr(String attr) {
this.attr = attr;
}
/**
* 克隆方法
* @return
*/
public Prototype clone(){
Prototype prototype = new ConcretePototype();
prototype.setAttr(this.attr);
return prototype;
}
}
这里给个小问题:能否将上述代码中的clone()方法写成public Prototype clone(){return this;}
答案是不能,因为原型模式创建的是一个新的对象,在内存中拥有新的地址,如果return this,返回的只是当前对象;克隆方法clone()所创建的对象是全新的对象,他们在内存中拥有新的地址,如果我们对克隆所产生的对象修改时,对原型对象不会造成任何的影响。
在客户类中我们只需要创建一个ConcretePrototype对象作为原型对象,然后调用其clone()方法即可得到对应的克隆对象,如下代码所示:
public class Client {
public static void main(String[] args){
Prototype obj1 = new ConcretePototype();
obj1.setAttr("hello world");
Prototype obj2 = obj1.clone();
System.out.println(obj2.getAttr());
}
}
这种方法可作为原型模式的通用实现,与编程语言特性无关,任何面对对象的语言均可使用这种形式实现对原型的克隆。
2.java语言提供的clone()方法
在java语言中,所有的java类都继承自java.lang.Object。事实上,Object类提供一个clone()方法,可以将一个java对象复制一份。因此在java中可以直接使用Object提供的clone()方法来实现对象的克隆,java语言中的原型模式实现很简单。
需要注意的是能够实现克隆的java类必须实现一个标识接口Cloneable,用来表示这个java类支持被复制。如果一个类没有实现这个接口但是调用了clone()方法,java编译器将抛出一个CloneNotSupportedException(克隆不被支持)异常。如下代码所示:
/**
* java中的Clone
*/
public class ConcretePototype2 implements Cloneable{
private String name;
private Integer age;
public String getName() { return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
} public Object clone(){
try {
ConcretePototype2 object = (ConcretePototype2) super.clone();
return object;
} catch (CloneNotSupportedException e) {
System.out.println("Clone Not Supported ");
return null;
}
}
在客户端创建原型对象和克隆对象也很简单,如下代码所示:
public class YuanXingTest {
public static void main(String[] args){
ConcretePototype2 obj1 = new ConcretePototype2();
ConcretePototype2 obj2 = (ConcretePototype2) obj1.clone();
}
}
一般而言,java语言中的Clone方法需要满足以下几点:
1)对任何对象X,都有x.clone() != x , 即克隆对象与原型对象不是同一个对象;
2)对任何对象X,都有x.clone().getClass() == x.getClass, 即克隆对象与原型对象的类型一样;
3)如果对象x的equals()方法定义恰当,那么x.clone().euqals(x)成立。euqals()比较的是内容,而非是地址。
为了获取对象的一份拷贝,我们可以直接利用Object类中的clone()方法,具体步骤如下:
1)在派生类(具体抽象类)中覆盖积累的clone()方法,并声明为public;
2)在派生类的clone()方法中,调用super.clone(),即是Object的clone()方法;
3)派生类需实现Cloneable接口。
此时,Object类相当于抽象原型类,所有实现了Cloneable接口的类相当于是具体原型类。
3.java语言提供的clone()方法
对于开头所讲的问题,Sunny公司开发人员决定使用原型模式来实现工作周报的快速创建,快速创建工作周报结构图如图7-3所示:

WeeklyLog充当具体原型类,Object类充当抽象原型,clone()方法为原型方法。WeeklyLog类的代码如下所示:
/**
* 周报的具体原型类
*/
public class WeeklyLog implements Cloneable{
private String name;
private String date;
private String content;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
/**
* 克隆方法
* @return
*/
public WeeklyLog clone(){
Object obj = null;
try {
obj = super.clone();
} catch (CloneNotSupportedException e) {
System.out.println("克隆不被支持");
}
return (WeeklyLog) obj;
}
}
客户端代码:
public class Client {
public static void main(String[] args){
WeeklyLog log_prototype = new WeeklyLog();
log_prototype.setName("张三丰");
log_prototype.setContent("天天加班,烦死了");
log_prototype.setDate("12");
System.out.println("******周报*******");
System.out.println("第 "+log_prototype.getDate()+"周");
System.out.println("姓名:"+log_prototype.getName());
System.out.println("总结:"+log_prototype.getContent());
System.out.println();
WeeklyLog newLog = log_prototype.clone();
newLog.setDate("13");
System.out.println("******周报*******");
System.out.println("第 "+newLog.getDate()+"周");
System.out.println("姓名:"+newLog.getName());
System.out.println("总结:"+newLog.getContent());
}
}
输出结果来一下:
******周报*******
第 12周
姓名:张三丰
总结:天天加班,烦死了 ******周报*******
第 13周
姓名:张三丰
总结:天天加班,烦死了
通过已经创建的工作周报可以快速创建新的周报,然后根据需求修改周报,无须再从头开始创建。原型模式为工作流系统中任务单的快速生成提供了一种新的解决方案。
4.java语言提供的clone()方法
通过引入原型模式,Sunny软件公司OA系统支持工作周报的快速克隆,极大的提高了工作周报的编写效率,受到员工的一致好评。但有员工又发现一个问题,有些工作周报带有附件,例如经理助理“小龙女”的周报通常附有本周项目进展报告汇总表,本周客户反馈信息汇总表等,如果使用上述原型模式来复制周报,周报虽然可以复制,但是周报的附件并不能复制,这是由于什么原因导致的呢?如何才能实现周报和附件的同时复制呢?我们在本节将讨论如何解决这些问题。在回答这些问题之前,先介绍一下两种不同的克隆方法,浅克隆(ShallowClone)和深克隆(DeepClone)。
java中数据类型分为值类型,和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制。
1.浅克隆
在浅克隆中,如果原型对象的成员变量是值类型,将复制一份给克隆对象;如果原型对象的成员变量是引用类型,则将原型对象的引用对象的地址复制一份给克隆对象,也就是说原型对象和克隆对象的成员变量指向相同的内存地址。简单来说,在浅克隆中,当原型对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员变量并没有复制。
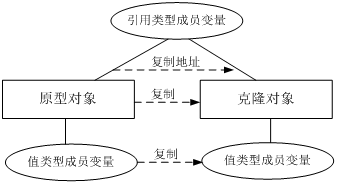
我们可以看到,并没有引用类型的成员变量被复制。
在Java语言中,通过覆盖Object类的clone()方法可以实现浅克隆。为了让大家更好地理解浅克隆和深克隆的区别,我们首先使用浅克隆来实现工作周报和附件类的复制,其结构如图7-5所示:
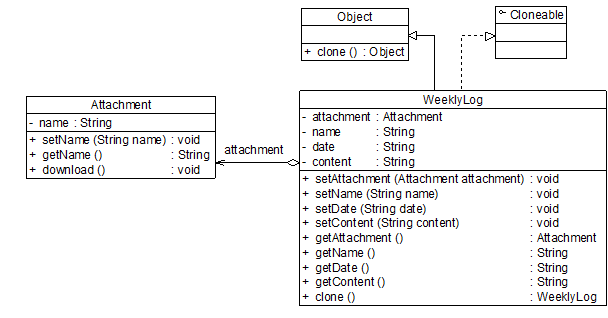
图7-5 带附件的周报结构图(浅克隆)
附件类Attachment代码如下:
|
//附件类 class Attachment { private String name; //附件名 public void setName(String name) { this.name = name; } public String getName() { return this.name; } public void download() { System.out.println("下载附件,文件名为" + name); } } |
修改工作周报类WeeklyLog,修改后的代码如下:
|
//工作周报WeeklyLog class WeeklyLog implements Cloneable { //为了简化设计和实现,假设一份工作周报中只有一个附件对象,实际情况中可以包含多个附件,可以通过List等集合对象来实现 private Attachment attachment; private String name; private String date; private String content; public void setAttachment(Attachment attachment) { this.attachment = attachment; } public void setName(String name) { this.name = name; } public void setDate(String date) { this.date = date; } public void setContent(String content) { this.content = content; } public Attachment getAttachment(){ return (this.attachment); } public String getName() { return (this.name); } public String getDate() { return (this.date); } public String getContent() { return (this.content); } //使用clone()方法实现浅克隆 public WeeklyLog clone() { Object obj = null; try { obj = super.clone(); return (WeeklyLog)obj; } catch(CloneNotSupportedException e) { System.out.println("不支持复制!"); return null; } } } |
客户端代码如下所示:
|
class Client { public static void main(String args[]) { WeeklyLog log_previous, log_new; log_previous = new WeeklyLog(); //创建原型对象 Attachment attachment = new Attachment(); //创建附件对象 log_previous.setAttachment(attachment); //将附件添加到周报中 log_new = log_previous.clone(); //调用克隆方法创建克隆对象 //比较周报 System.out.println("周报是否相同? " + (log_previous == log_new)); //比较附件 System.out.println("附件是否相同? " + (log_previous.getAttachment() == log_new.getAttachment())); } } |
编译并运行程序,输出结果如下:
|
周报是否相同? false 附件是否相同? true |
由于使用的是浅克隆技术,因此工作周报对象复制成功,通过“==”比较原型对象和克隆对象的内存地址时输出false;但是比较附件对象的内存地址时输出true,说明它们在内存中是同一个对象。
2.深克隆
在深克隆中,无论原型对象的成员变量是值类型还是引用类型,都将复制一份给克隆对象,深克隆将原型对象的所有引用对象也复制一份给克隆对象。简单来说,在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制,如图7-6所示:
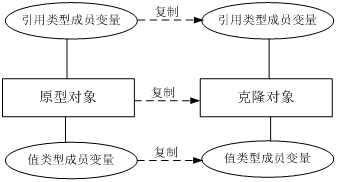
图7-6 深克隆示意图
在Java语言中,如果需要实现深克隆,可以通过序列化(Serialization)等方式来实现。序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。下面我们使用深克隆技术来实现工作周报和附件对象的复制,由于要将附件对象和工作周报对象都写入流中,因此两个类均需要实现Serializable接口,其结构如图7-7所示:
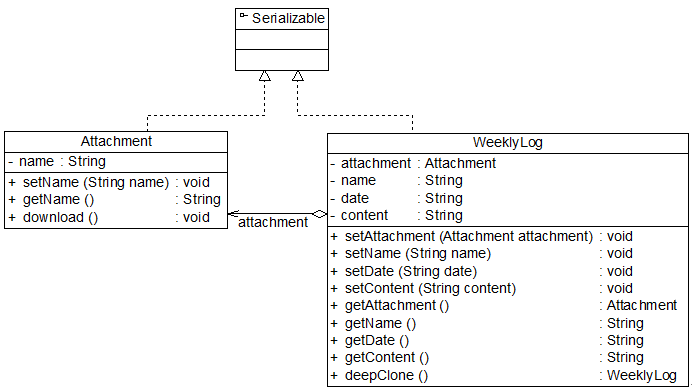
图7-7 带附件的周报结构图(深克隆)
修改后的附件类Attachment代码如下:
|
import java.io.*; //附件类 class Attachment implements Serializable { private String name; //附件名 public void setName(String name) { this.name = name; } public String getName() { return this.name; } public void download() { System.out.println("下载附件,文件名为" + name); } } |
工作周报类WeeklyLog不再使用Java自带的克隆机制,而是通过序列化来从头实现对象的深克隆,我们需要重新编写clone()方法,修改后的代码如下:
import java.io.*;
//工作周报类
class WeeklyLog implements Serializable
{
private Attachment attachment;
private String name;
private String date;
private String content;
public void setAttachment(Attachment attachment) {
this.attachment = attachment;
}
public void setName(String name) {
this.name = name;
}
public void setDate(String date) {
this.date = date;
}
public void setContent(String content) {
this.content = content;
}
public Attachment getAttachment(){
return (this.attachment);
}
public String getName() {
return (this.name);
}
public String getDate() {
return (this.date);
}
public String getContent() {
return (this.content);
}
//使用序列化技术实现深克隆
public WeeklyLog deepClone() throws IOException, ClassNotFoundException, OptionalDataException {
//将对象写入流中
ByteArrayOutputStream bao=new ByteArrayOutputStream();
ObjectOutputStream oos=new ObjectOutputStream(bao);
oos.writeObject(this);
//将对象从流中取出
ByteArrayInputStream bis=new ByteArrayInputStream(bao.toByteArray());
ObjectInputStream ois=new ObjectInputStream(bis);
return (WeeklyLog)ois.readObject();
}
}
客户端代码如下所示:
class Client
{
public static void main(String args[])
{
WeeklyLog log_previous, log_new = null;
log_previous = new WeeklyLog(); //创建原型对象
Attachment attachment = new Attachment(); //创建附件对象
log_previous.setAttachment(attachment); //将附件添加到周报中
try
{
log_new = log_previous.deepClone(); //调用深克隆方法创建克隆对象
}
catch(Exception e)
{
System.err.println("克隆失败!");
}
//比较周报
System.out.println("周报是否相同? " + (log_previous == log_new));
//比较附件
System.out.println("附件是否相同? " + (log_previous.getAttachment() == log_new.getAttachment()));
}
}
编译并运行程序,输出结果如下:
周报是否相同? false
附件是否相同? false
|
从输出结果可以看出,由于使用了深克隆技术,附件对象也得以复制,因此用“==”比较原型对象的附件和克隆对象的附件时输出结果均为false。深克隆技术实现了原型对象和克隆对象的完全独立,对任意克隆对象的修改都不会给其他对象产生影响,是一种更为理想的克隆实现方式。
5.原型管理器的引入和实现
原型管理器(Prototype Manager)是将多个原型对象存储在一个集合中供客户端使用,它是一个专门负责克隆对象的工厂,其中定义了一个集合用于存储原型对象,如果需要某个原型对象的一个克隆,可以通过复制集合中对应的原型对象来获得。在原型管理器中针对抽象原型类进行编程,以便扩展。其结构如图7-8所示:
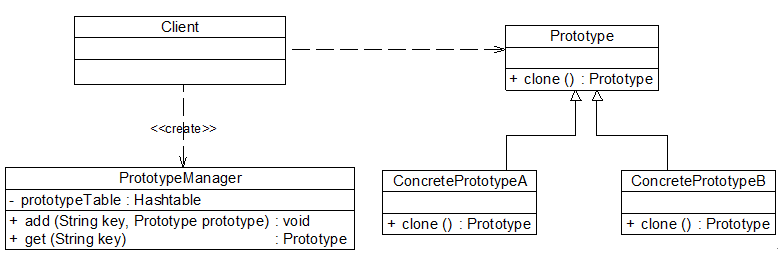
图7-8 带原型管理器的原型模式
下面通过模拟一个简单的公文管理器来介绍原型管理器的设计与实现:
|
Sunny软件公司在日常办公中有许多公文需要创建、递交和审批,例如《可行性分析报告》、《立项建议书》、《软件需求规格说明书》、《项目进展报告》等,为了提高工作效率,在OA系统中为各类公文均创建了模板,用户可以通过这些模板快速创建新的公文,这些公文模板需要统一进行管理,系统根据用户请求的不同生成不同的新公文。 |
我们使用带原型管理器的原型模式实现公文管理器的设计,其结构如图7-9所示:
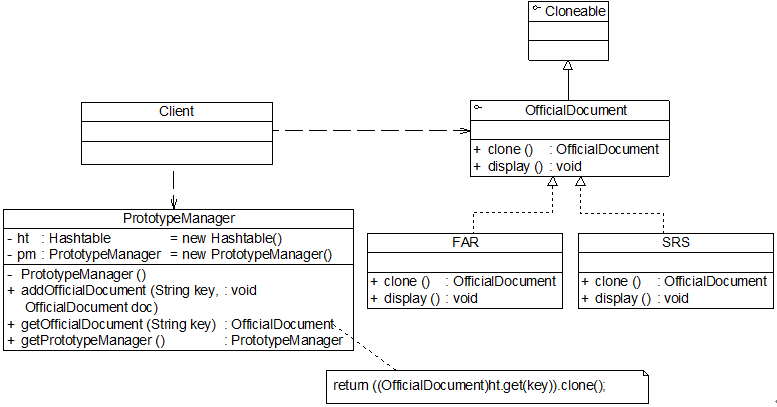
图7-9 公文管理器结构图
以下是实现该功能的一些核心代码,考虑到代码的可读性,我们对所有的类都进行了简化:
|
import Java.util.*; //抽象公文接口,也可定义为抽象类,提供clone()方法的实现,将业务方法声明为抽象方法 interface OfficialDocument extends Cloneable { public OfficialDocument clone(); public void display(); } //可行性分析报告(Feasibility Analysis Report)类 class FAR implements OfficialDocument { public OfficialDocument clone() { OfficialDocument far = null; try { far = (OfficialDocument)super.clone(); } catch(CloneNotSupportedException e) { System.out.println("不支持复制!"); } return far; } public void display() { System.out.println("《可行性分析报告》"); } } //软件需求规格说明书(Software Requirements Specification)类 class SRS implements OfficialDocument { public OfficialDocument clone() { OfficialDocument srs = null; try { srs = (OfficialDocument)super.clone(); } catch(CloneNotSupportedException e) { System.out.println("不支持复制!"); } return srs; } public void display() { System.out.println("《软件需求规格说明书》"); } } //原型管理器(使用饿汉式单例实现) class PrototypeManager { //定义一个Hashtable,用于存储原型对象 private Hashtable ht=new Hashtable(); private static PrototypeManager pm = new PrototypeManager();
//为Hashtable增加公文对象 private PrototypeManager() { ht.put("far",new FAR()); ht.put("srs",new SRS()); }
//增加新的公文对象 public void addOfficialDocument(String key,OfficialDocument doc) { ht.put(key,doc); }
//通过浅克隆获取新的公文对象 public OfficialDocument getOfficialDocument(String key) { return ((OfficialDocument)ht.get(key)).clone(); }
public static PrototypeManager getPrototypeManager() { return pm; } } |
客户端代码如下所示:
|
class Client { public static void main(String args[]) { //获取原型管理器对象 PrototypeManager pm = PrototypeManager.getPrototypeManager(); OfficialDocument doc1,doc2,doc3,doc4; doc1 = pm.getOfficialDocument("far"); doc1.display(); doc2 = pm.getOfficialDocument("far"); doc2.display(); System.out.println(doc1 == doc2); doc3 = pm.getOfficialDocument("srs"); doc3.display(); doc4 = pm.getOfficialDocument("srs"); doc4.display(); System.out.println(doc3 == doc4); } } |
编译并运行程序,输出结果如下:
|
《可行性分析报告》 《可行性分析报告》 false 《软件需求规格说明书》 《软件需求规格说明书》 false |
在PrototypeManager中定义了一个Hashtable类型的集合对象,使用“键值对”来存储原型对象,客户端可以通过Key(如“far”或“srs”)来获取对应原型对象的克隆对象。PrototypeManager类提供了类似工厂方法的getOfficialDocument()方法用于返回一个克隆对象。在本实例代码中,我们将PrototypeManager设计为单例类,使用饿汉式单例实现,确保系统中有且仅有一个PrototypeManager对象,有利于节省系统资源,并可以更好地对原型管理器对象进行控制。
|
6 原型模式总结
原型模式作为一种快速创建大量相同或相似对象的方式,在软件开发中应用较为广泛,很多软件提供的复制(Ctrl + C)和粘贴(Ctrl + V)操作就是原型模式的典型应用,下面对该模式的使用效果和适用情况进行简单的总结。
1.主要优点
原型模式的主要优点如下:
(1) 当创建新的对象实例较为复杂时,使用原型模式可以简化对象的创建过程,通过复制一个已有实例可以提高新实例的创建效率。
(2) 扩展性较好,由于在原型模式中提供了抽象原型类,在客户端可以针对抽象原型类进行编程,而将具体原型类写在配置文件中,增加或减少产品类对原有系统都没有任何影响。
(3) 原型模式提供了简化的创建结构,工厂方法模式常常需要有一个与产品类等级结构相同的工厂等级结构,而原型模式就不需要这样,原型模式中产品的复制是通过封装在原型类中的克隆方法实现的,无须专门的工厂类来创建产品。
(4) 可以使用深克隆的方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,以便在需要的时候使用(如恢复到某一历史状态),可辅助实现撤销操作。
2.主要缺点
原型模式的主要缺点如下:
(1) 需要为每一个类 配备一个克隆方法,而且该克隆方法位于一个类的内部,当对已有的类进行改造时,需要修改源代码,违背了“开闭原则”。
(2) 在实现深克隆时需要编写较为复杂的代码,而且当对象之间存在多重的嵌套引用时,为了实现深克隆,每一层对象对应的类都必须支持深克隆,实现起来可能会比较麻烦。
3.适用场景
在以下情况下可以考虑使用原型模式:
(1) 创建新对象成本较大(如初始化需要占用较长的时间,占用太多的CPU资源或网络资源),新的对象可以通过原型模式对已有对象进行复制来获得,如果是相似对象,则可以对其成员变量稍作修改。
(2) 如果系统要保存对象的状态,而对象的状态变化很小,或者对象本身占用内存较少时,可以使用原型模式配合备忘录模式来实现。
(3) 需要避免使用分层次的工厂类来创建分层次的对象,并且类的实例对象只有一个或很少的几个组合状态,通过复制原型对象得到新实例可能比使用构造函数创建一个新实例更加方便。
|
将近5个多月的时间,创建型模式终于写完了,这效率也是慢到爆了,特别闲的时候就写一会,所以效率也是太慢,看来我真是不适合做这种需要长期坚持下去的工作丫,不过自己通过这篇博客学到了一些东西。特别是单例模式和原型模式,及程序设计思想;所以这次一定要坚持下去;
由于这篇博客太长了,所以行为性模式及结构性模式会另开一个博文;
如果写的有披露或个人理解不对之处,欢迎大家批评,我们一起成长!
学习java23种设计模式自我总结的更多相关文章
- java23种设计模式 (转)
文章在:http://www.cnblogs.com/maowang1991/archive/2013/04/15/3023236.html 随着自己的开发经验增加以及自己做了很多的 大专栏 jav ...
- java23种设计模式——四、原型模式
源码在我的github和gitee中获取 目录 java23种设计模式-- 一.设计模式介绍 java23种设计模式-- 二.单例模式 java23种设计模式--三.工厂模式 java23种设计模式- ...
- java23种设计模式—— 一、设计模式介绍
Java23种设计模式全解析 目录 java23种设计模式-- 一.设计模式介绍 java23种设计模式-- 二.单例模式 java23种设计模式--三.工厂模式 java23种设计模式--四.原型模 ...
- java23种设计模式——五、建造者模式
源码在我的github和gitee中获取 目录 java23种设计模式-- 一.设计模式介绍 java23种设计模式-- 二.单例模式 java23种设计模式--三.工厂模式 java23种设计模式- ...
- java23种设计模式——八、组合模式
目录 java23种设计模式-- 一.设计模式介绍 java23种设计模式-- 二.单例模式 java23种设计模式--三.工厂模式 java23种设计模式--四.原型模式 java23种设计模式-- ...
- java23种设计模式——七、桥接模式
原文地址:https://www.cnblogs.com/chenssy/p/3317866.html 源码在我的github和gitee中获取 目录 java23种设计模式-- 一.设计模式介绍 j ...
- java23种设计模式详解(转)
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- java23种设计模式等等。。
23种设计模式http://www.cnblogs.com/maowang1991/archive/2013/04/15/3023236.html 提升Java代码性能和安全性https://blog ...
- Java23种设计模式学习笔记【目录总贴】
创建型模式:关注对象的创建过程 1.单例模式:保证一个类只有一个实例,并且提供一个访问该实例的全局访问点 主要: 饿汉式(线程安全,调用效率高,但是不能延时加载) 懒汉式(线程安全,调用效率不高,但 ...
随机推荐
- 《JAVA与模式》之工厂方法模式
在阎宏博士的<JAVA与模式>一书中开头是这样描述工厂方法模式的: 工厂方法模式是类的创建模式,又叫做虚拟构造子(Virtual Constructor)模式或者多态性工厂(Polymor ...
- [SMB share]Create SMB share under powershell / poweshell下创建本机的SMB共享
New-SmbShare -Name share-name -Path C:\share -FolderEnumerationMode AccessBased -CachingMode Documen ...
- Kubernetes之调度器和调度过程
scheduler 当Scheduler通过API server 的watch接口监听到新建Pod副本的信息后,它会检查所有符合该Pod要求的Node列表,开始执行Pod调度逻辑.调度成功后将Pod绑 ...
- pthread mutex 进程间互斥锁实例
共享标志 定义 名称 描述 0 PTHREAD_PROCESS_PRIVATE 进程内互斥锁 仅可当前进程内共享 1 PTHREAD_PROCESS_SHARED 进程间互斥锁 多个进程间共享 第一个 ...
- ARIMA模型原理
一.时间序列分析 北京每年每个月旅客的人数,上海飞往北京每年的游客人数等类似这种顾客数.访问量.股价等都是时间序列数据.这些数据会随着时间变化而变化.时间序列数据的特点是数据会随时间的变化而变化. 随 ...
- Exp1:PC平台逆向破解 20164314 郭浏聿
一.实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另一个代码片段,getS ...
- kai linux安装搜狗输入法以及更新源地址
需要去搜狗官网下载linux版的输入法,根据自己的系统选择多少位进行下载. 首先执行如下命令:dpkg -i 输入法包名,这时会报错,会报没有安装依赖包,这时需要执行apt-get install - ...
- 在linux安装mysql重启提示You must SET PASSWORD before executing this statement的解决方法
利用安全模式成功登陆,然后修改密码,等于给MySql设置了密码.登陆进去后,想查询所有存在的数据库测试下.得到的结果确实: ERROR 1820 (HY000): You must SET PASSW ...
- webbrowser设置为相应的IE版本
注册表路径: HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Internet Explorer\Main\FeatureControl\FEATU ...
- 论文阅读笔记(七)YOLO
You Only Look Once: Unified, Real-Time Object Detection Joseph Redmon, CVPR, 2016 1. 之前的目标检测工作将分类器用作 ...