【Spark篇】---Spark中Action算子
一、前述
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序(就是我们编写的一个应用程序)中有几个Action类算子执行,就有几个job运行。
二、具体
原始数据集:
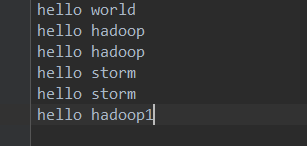
1、count
返回数据集中的元素数。会在结果计算完成后回收到Driver端。返回行数
package com.spark.spark.actions; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext; /**
* count
* 返回结果集中的元素数,会将结果回收到Driver端。
*
*/
public class Operator_count {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("collect");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
long count = lines.count();
System.out.println(count);
jsc.stop();
}
}
结果:返回行数即元素数

2、take(n)
first=take(1) 返回数据集中的第一个元素。
返回一个包含数据集前n个元素的集合。是一个(array)有几个partiotion 会有几个job触发
package com.spark.spark.actions; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* take
*
* @author root
*
*/
public class Operator_takeAndFirst {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("take");
JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> parallelize = jsc.parallelize(Arrays.asList("a","b","c","d"));
List<String> take = parallelize.take(2);
String first = parallelize.first();
for(String s:take){
System.out.println(s);
}
jsc.stop();
}
}
结果:

3、foreach
循环遍历数据集中的每个元素,运行相应的逻辑。
4、collect
将计算结果回收到Driver端。当数据量很大时就不要回收了,会造成oom.
一般在使用过滤算子或者一些能返回少量数据集的算子后
package com.spark.spark.actions; import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function; /**
* collect
* 将计算的结果作为集合拉回到driver端,一般在使用过滤算子或者一些能返回少量数据集的算子后,将结果回收到Driver端打印显示。
*
*/
public class Operator_collect {
public static void main(String[] args) {
/**
* SparkConf对象中主要设置Spark运行的环境参数。
* 1.运行模式
* 2.设置Application name
* 3.运行的资源需求
*/
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("collect");
/**
* JavaSparkContext对象是spark运行的上下文,是通往集群的唯一通道。
*/
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> resultRDD = lines.filter(new Function<String, Boolean>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Boolean call(String line) throws Exception {
return !line.contains("hadoop");
} });
List<String> collect = resultRDD.collect();
for(String s :collect){
System.out.println(s);
} jsc.stop();
}
}
结果:

- countByKey
作用到K,V格式的RDD上,根据Key计数相同Key的数据集元素。(也就是个数)
java代码:
package com.spark.spark.actions; import java.util.Arrays;
import java.util.Map;
import java.util.Map.Entry; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2;
/**
* countByKey
*
* 作用到K,V格式的RDD上,根据Key计数相同Key的数据集元素。返回一个Map<K,Object>
* @author root
*
*/
public class Operator_countByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("countByKey");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<Integer, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
new Tuple2<Integer,String>(1,"a"),
new Tuple2<Integer,String>(2,"b"),
new Tuple2<Integer,String>(3,"c"),
new Tuple2<Integer,String>(4,"d"),
new Tuple2<Integer,String>(4,"e")
)); Map<Integer, Object> countByKey = parallelizePairs.countByKey();
for(Entry<Integer,Object> entry : countByKey.entrySet()){
System.out.println("key:"+entry.getKey()+"value:"+entry.getValue());
} }
}
结果:

- countByValue
根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
java代码:
package com.spark.spark.actions; import java.util.Arrays;
import java.util.Map;
import java.util.Map.Entry; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2;
/**
* countByValue
* 根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
*
* @author root
*
*/
public class Operator_countByValue {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("countByKey");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaPairRDD<Integer, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
new Tuple2<Integer,String>(1,"a"),
new Tuple2<Integer,String>(2,"b"),
new Tuple2<Integer,String>(2,"c"),
new Tuple2<Integer,String>(3,"c"),
new Tuple2<Integer,String>(4,"d"),
new Tuple2<Integer,String>(4,"d")
)); Map<Tuple2<Integer, String>, Long> countByValue = parallelizePairs.countByValue(); for(Entry<Tuple2<Integer, String>, Long> entry : countByValue.entrySet()){
System.out.println("key:"+entry.getKey()+",value:"+entry.getValue());
}
}
}
scala代码:
package com.bjsxt.spark.actions import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* countByValue
* 根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
*/
object Operator_countByValue {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("countByValue")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List("a","a","b"))
val rdd2 = rdd1.countByValue()
rdd2.foreach(println)
sc.stop()
}
}
代码结果:
java:

scala:

- reduce
根据聚合逻辑聚合数据集中的每个元素。(reduce里面需要具体的逻辑,根据里面的逻辑对相同分区的数据进行计算)
java代码:
package com.spark.spark.actions; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
/**
* reduce
*
* 根据聚合逻辑聚合数据集中的每个元素。
* @author root
*
*/
public class Operator_reduce {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("reduce");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3,4,5)); Integer reduceResult = parallelize.reduce(new Function2<Integer, Integer, Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
System.out.println(reduceResult);
sc.stop();
}
}
scala代码:
package com.bjsxt.spark.actions import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* reduce
*
* 根据聚合逻辑聚合数据集中的每个元素。
*/
object Operator_reduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("reduce") val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(Array(1,2)) val result = rdd1.reduce(_+_) println(result)
sc.stop()
}
}
结果:
java:

scala:

【Spark篇】---Spark中Action算子的更多相关文章
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- 【Spark篇】---Spark中Transformations转换算子
一.前述 Spark中默认有两大类算子,Transformation(转换算子),懒执行.action算子,立即执行,有一个action算子 ,就有一个job. 通俗些来说由RDD变成RDD就是Tra ...
- Spark中的各种action算子操作(java版)
在我看来,Spark编程中的action算子的作用就像一个触发器,用来触发之前的transformation算子.transformation操作具有懒加载的特性,你定义完操作之后并不会立即加载,只有 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- 【Spark篇】---SparkStreaming算子操作transform和updateStateByKey
一.前述 今天分享一篇SparkStreaming常用的算子transform和updateStateByKey. 可以通过transform算子,对Dstream做RDD到RDD的任意操作.其实就是 ...
- 关于spark RDD trans action算子、lineage、宽窄依赖详解
这篇文章想从spark当初设计时为何提出RDD概念,相对于hadoop,RDD真的能给spark带来何等优势.之前本想开篇是想总体介绍spark,以及环境搭建过程,但个人感觉RDD更为重要 铺垫 在h ...
- 【Spark篇】---Spark中广播变量和累加器
一.前述 Spark中因为算子中的真正逻辑是发送到Executor中去运行的,所以当Executor中需要引用外部变量时,需要使用广播变量. 累机器相当于统筹大变量,常用于计数,统计. 二.具体原理 ...
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- 【Spark】RDD操作具体解释4——Action算子
本质上在Actions算子中通过SparkContext运行提交作业的runJob操作,触发了RDD DAG的运行. 依据Action算子的输出空间将Action算子进行分类:无输出. HDFS. S ...
随机推荐
- pyqt win32发送QQ消息
标题应该改为:python+win32发送QQ消息,全程使用python套个pyqt壳. 其实代码来自: http://blog.csdn.net/suzyu12345/article/details ...
- 开发中常用的JS知识点集锦
索引 1.对象深拷贝 2.网络图片转base64, 在线图片点击下载 3.常用CSS样式记录(超出宽高省略展示/播放icon/按钮背景颜色渐变...) 4.对象深拷贝 5.对象深拷贝 6.对象深拷贝 ...
- maya cmds pymel 选择 uv area(uv 面积) 为0 的面
maya cmds pymel 选择 uv area(uv 面积) 为0 的面 cmds.selectType( pf=True ) cmds.polySelectConstraint( m=3, t ...
- 关于DataTable序列化的事儿
今天写了一个小demo,从数据库中读取到了dataTable,想序列化成json字符串,然后传到前端,进行页面展示,其实很简单的一个步骤,谁知道它出错了!!! 出错的原因是:序列化类型为XX的对象时检 ...
- Chrome开发者工具面板
Chrome开发者工具面板 面板上包含了Elements面板.Console面板.Sources面板.Network面板.Timeline面板.Profiles面板.Application面板.Sec ...
- QT—QTextEdit控件显示日志
功能:利用QTextEdit开发一个日志显示窗口.没有太多操作,需要实现的是日志自动向上滚动,总体的日志量可以控制在x行(比如300行)以内:其他的应用功能我后面继续添加 #include <Q ...
- sublime设置sublimeREPL-python-run current file 快捷键
弄了3个小时的快捷键,一直不能成功使用,百度上一堆一样的方法,最后FQ才找到能用的方法,真是服了. 方法: ①首选项->快捷键设置 填写如下内容: [ {"keys": [& ...
- vue-router路由学习总结
vue路由 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- Httpclient代码
/// <summary> /// 显示 /// </summary> /// <returns></returns> public ActionRes ...
- Fence Repair POJ - 3253 (贪心)
Farmer John wants to repair a small length of the fence around the pasture. He measures the fence an ...