tensorboard基础使用
github上的tensorboard项目:https://github.com/tensorflow/tensorboard/blob/master/README.md
目录
- 基础介绍
- 基本使用
- 几种图
- 实例源码
一、基本介绍
tensorboard:一个网页应用,可以方便观察TensorFlow的运行过程和网络结构等(过程可视化)
工作流程
- Summary Ops:从TensorFlow获取数据
Ops是指tf.matmul、tf.nn.relu等,也就是在TensorFlow图中的操作
执行过程中的张量包含序列化的原始缓存,它会被写到磁盘并传给TensorBoard。然后需要执行summary op,来恢复这些结果,实现对TensorBoard中的数据可视化
summary ops包括:tf.summary.scalar, tf.summary.image, tf.summary.audio, tf.summary.text, tf.summary.histogram
- tags:给数据一个名字
当进行summary op时,也可以给一个tag。这个tag是该op记录的数据的名字,作为一种标识
- Event Files和logDir:如何加载数据
summary.FileWriters从TensorFlow把summary 数据写到磁盘中特定的目录,也就是logDir。数据是以追加的方式写入,文件名中有"tfevents"。TensorBoard从一个完整的目录中读取数据,并组织成一次TensorFlow执行过程
说明
- 为什么不是从一个独立文件读取?
如果你用superviosr.py来跑模型,当TensorFlow崩溃,superviso将从一个checkpoint重新开始跑。因为重新开始,就会产生一个新的event 文件,然后TensorBoard就可以把这些不同的event文件组织成一个连续的历史
- 执行:比较模型的不同执行
比如对某个超参数做了调整,想要比较该超参数不同值的执行效果。希望可视化的时候,可以同时展示这两个效果
实现方法:给TensorBoard传一个参数logdir,它将递归查找,每次遇到一个子目录,就会把它当成一个新的执行。
例:下面有run1和run2两个结果
|
/some/path/mnist_experiments/ /some/path/mnist_experiments/run1/ /some/path/mnist_experiments/run1/events.out.tfevents.1456525581.name /some/path/mnist_experiments/run1/events.out.tfevents.1456525585.name /some/path/mnist_experiments/run2/ /some/path/mnist_experiments/run2/events.out.tfevents.1456525385.name /tensorboard --logdir /some/path/mnist_experiments |
二、基本操作
定一个writer(log位置),用来写summary结果:train_writer = tf.summary.FileWriter("./resource/logdir", sess.graph)- 对要统计的变量使用summary操作:比如 tf.summary.scalar("accuarcy_train", accuracy_train) 对精确度的统计,第一个参数是名字,第二个参数是变量名
- 把所有summary操作merge起来: merged = tf.summary.merge_all()
- 执行过程中fetch merged获得想要的变量值: summary, _ = sess.run([merged, train_step], feed_dict={x: batch_xs, y_: batch_ys})
- 把第i次迭代的结果summary添加到train_writer: train_writer.add_summary(summary, i)
- 关闭写 train_writer.close()
启动tensorboard
- windows:进入{path}/Anaconda/Scripts,执行 ./tensorboard.exe --logdir={path}/resource/logdir/
- ubuntu:进入{path}/Anaconda/envs/tensorflow/bin,执行 ./tensorboard --logdir={path}/resource/logdir/
根据提示,访问网页即可结果
三、几种图
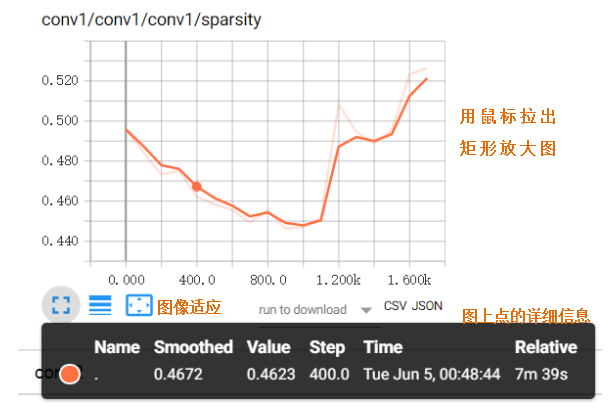
Scalar Dashboard: tf.summary.scalar
将标量值随时间时间变化进行可视化,如losss或学习率
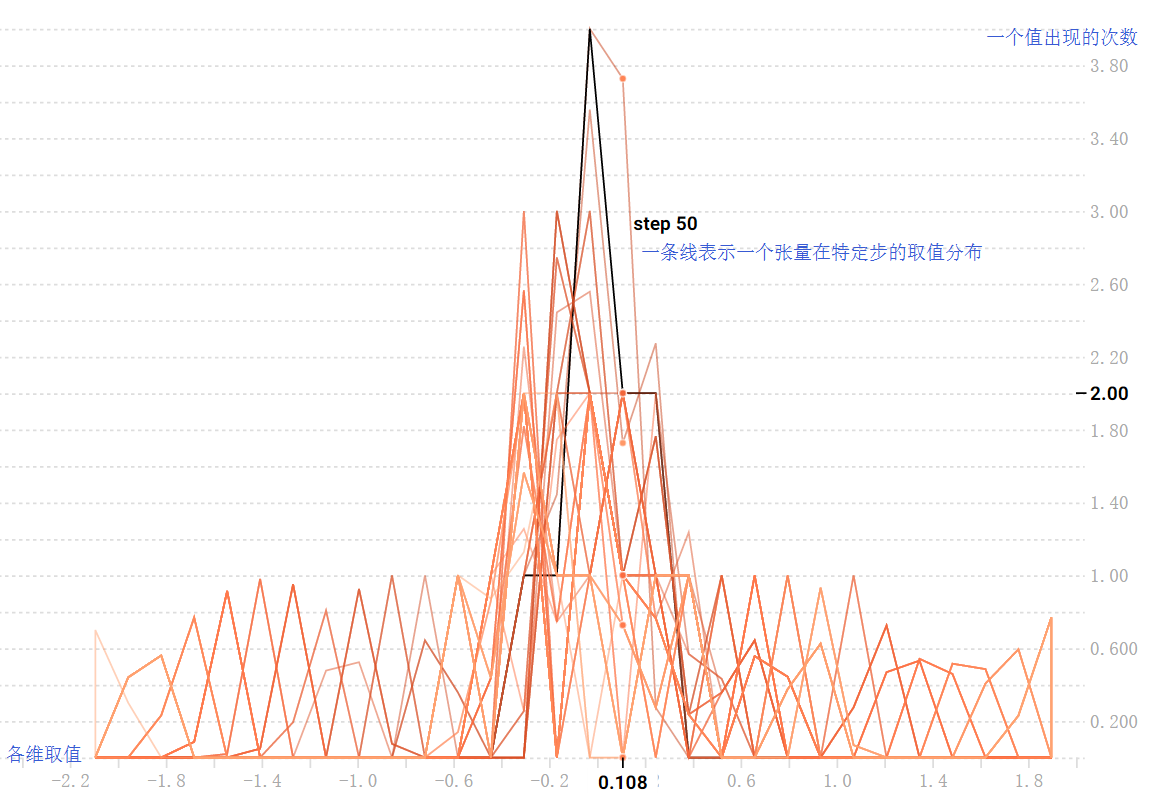
Histogram Dashboard: tf.summary.histogram
张量随时间变化的分布情况。每个图表是数据的临时切片,每个切片是特定一步的张量的柱状图。越早的时间步结果越靠后
overlay-step offset-step
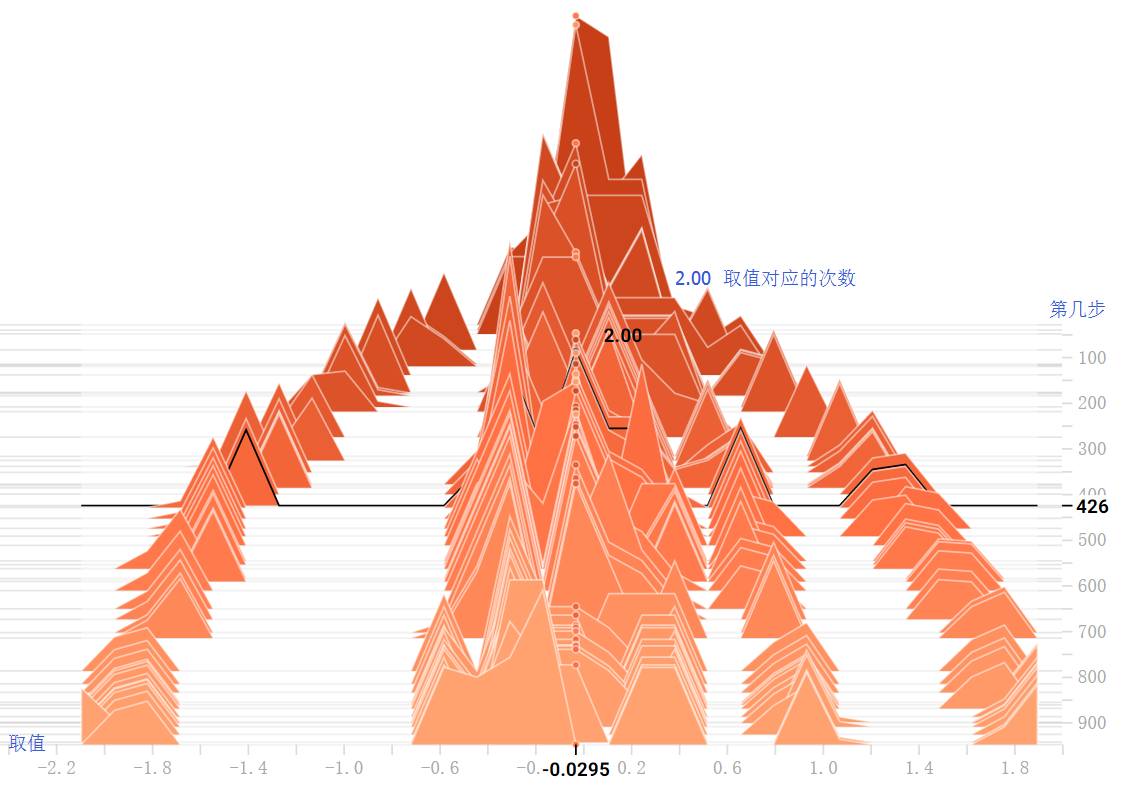
Distribution Dashboard: tf.summary.histogram
tf.summary.histogram的另一种展示方式。每一行代表一个值随时间步的变化情况。最下面是最小的值,向上值不断增大。每一列代表一个时间步中值的取值范围
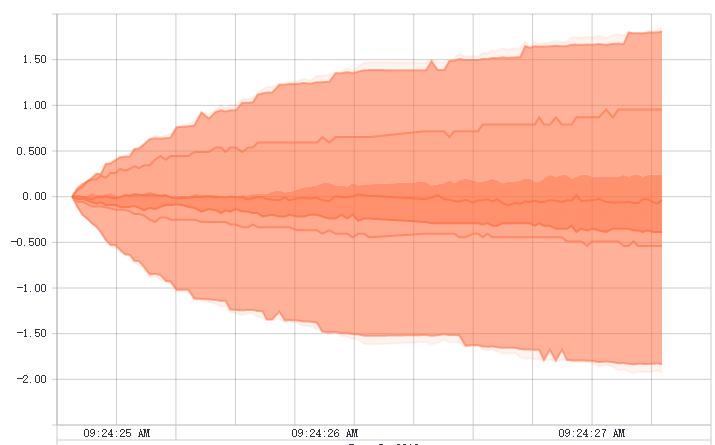
Image Dashboard:tf.summary.image
展示png图像,每一行对应不同的tag,每一列是一个执行。tf.summary.image("images", tf.reshape(input_images, [100, 28, 28, 1]))

Audio Dashboard:tf.summary.audio(没用过)
嵌入可播放的音频容器。每行对应不同的tag,每列是一次运行。总是嵌入最新的一次结果
Graph Explorer
对TensorFlow模型的可视化
Embedding Projector
展示高维度的数据。projector是从模型的checkpoint文件读取数据,也可以用其他metadata配置,比如词汇表或雪碧图
Text Dashboar(没用过)
四、实例源码
def tensorboard():
# None表示此张量的第一个维度可以是任何长度的
x = tf.placeholder("float", [None, 784])
y_ = tf.placeholder("float", [None, 10]) # 标签,正确结果 # 初始化两个参数
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
m = [1,2,3,4,5,6]
tf.summary.histogram("xx", b)
# softmax函数
y = tf.nn.softmax(tf.matmul(x, W) + b) # 执行结果 # 交叉熵,成本函数
# tf.reduce_sum 计算张量的所有元素的总和
cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) # 梯度下降法来优化成本函数
# 下行代码往计算图上添加一个新操作,其中包括计算梯度,计算每个参数的步长变化,并且计算出新的参数值
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) init = tf.initialize_all_variables()
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) prediction_train = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy_train = tf.reduce_mean(tf.cast(prediction_train, "float"))
tf.summary.scalar("accuarcy_train", accuracy_train) # 显示图像
batch_xs, batch_ys = mnist.train.next_batch(100)
tf.summary.image('images', tf.reshape(batch_xs, [100, 28, 28, 1])) # 用于tensorboard
merged = tf.summary.merge_all() with tf.Session() as sess:
sess.run(init)
train_writer = tf.summary.FileWriter("./resource/mnist_logs", sess.graph) # 循环遍历1000次训练模型
for i in range(1000):
# 每一步迭代加载100个训练样本,然后执行一次train_step,并通过feed_dict将x 和 y张量占位符用训练训练数据替代
summary, _ = sess.run([merged, train_step], feed_dict={x: batch_xs, y_: batch_ys}) if i % 10 == 0:
train_writer.add_summary(summary, i)
for index, d in enumerate(m):
m[index] -= 0.1
batch_xs, batch_ys = mnist.train.next_batch(100)
train_writer.close() correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
tensorboard基础使用的更多相关文章
- 基于Python玩转人工智能最火框架 TensorFlow应用实践✍✍✍
基于Python玩转人工智能最火框架 TensorFlow应用实践 随着 TensorFlow 在研究及产品中的应用日益广泛,很多开发者及研究者都希望能深入学习这一深度学习框架.而在昨天机器之心发起 ...
- Python玩转人工智能最火框架 TensorFlow应用实践 学习 教程
随着 TensorFlow 在研究及产品中的应用日益广泛,很多开发者及研究者都希望能深入学习这一深度学习框架.而在昨天机器之心发起的框架投票中,2144 位参与者中有 1441 位都在使用 Tenso ...
- 第七节,TensorFlow编程基础案例-TensorBoard以及常用函数、共享变量、图操作(下)
这一节主要来介绍TesorFlow的可视化工具TensorBoard,以及TensorFlow基础类型定义.函数操作,后面又介绍到了共享变量和图操作. 一 TesnorBoard可视化操作 Tenso ...
- TensorFlow基础笔记(9) Tensorboard可视化显示以及查看pb meta模型文件的方法
参考: http://blog.csdn.net/l18930738887/article/details/55000008 http://www.jianshu.com/p/19bb60b52dad ...
- CNN基础四:监测并控制训练过程的法宝——Keras回调函数和TensorBoard
训练模型时,很多事情一开始都无法预测.比如之前我们为了找出迭代多少轮才能得到最佳验证损失,可能会先迭代100次,迭代完成后画出运行结果,发现在中间就开始过拟合了,于是又重新开始训练. 类似的情况很多, ...
- tensorflow笔记(一)之基础知识
tensorflow笔记(一)之基础知识 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7399701.html 前言 这篇no ...
- tensorflow笔记(三)之 tensorboard的使用
tensorflow笔记(三)之 tensorboard的使用 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7429344.h ...
- 机器学习笔记4-Tensorflow线性模型示例及TensorBoard的使用
前言 在上一篇中,我简单介绍了一下Tensorflow以及在本机及阿里云的PAI平台上跑通第一个示例的步骤.在本篇中我将稍微讲解一下几个基本概念以及Tensorflow的基础语法. 本文代码都是基于A ...
- TensorFlow基础
TensorFlow基础 SkySeraph 2017 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站点:www.skyseraph.com Over ...
随机推荐
- AI要被祭天了!删Bug,删着删着把全部代码都删了
近日,美国版的“大众点评”,本想训练 AI 来消除 bug,结果它把所有内容删除了... Yelp 在其最新更新的 App 中写道: “我们为本周使用该app遇到问题的用户致歉.我们训练了一个神经网络 ...
- Office开发必备知识----为什么要释放非托管Com资源
https://www.cnblogs.com/Charltsing/p/RealeaseComObject.html QQ:564955427 目前,国内Office插件开发的风头正盛,很多VBAe ...
- MySQL源码包编译安装
+++++++++++++++++++++++++++++++++++++++++++标题:MySQL数据库实力部署时间:2019年3月9日内容:MySQL源码包进行编译,然后部署MySQL单实例重点 ...
- java.lang.IllegalStateException: LifecycleProcessor not initialized - call 'refresh' before invoking lifecycle methods via the context: Root WebApplicationContext: startup date [Mon Oct 01 16:32:37 CS
使用idea工具更改项目包名时报 :java.lang.ClassNotFoundException 解决方案: 1.删除项目的target目录,这个目录存放的是编译后的文件 2.清除缓存 3.重新编 ...
- React Native——react-navigation的使用
在 React Native 中,官方已经推荐使用 react-navigation 来实现各个界面的跳转和不同板块的切换. react-navigation 主要包括三个组件: StackNavig ...
- Django分布式任务队列celery的实践
不使用数据库作为 Broker Broker 的选择大致有消息队列和数据库两种,这里建议尽量避免使用数据库作为 Broker,除非你的业务系统足够简单.在并发量很高的复杂系统中,大量 Workers ...
- 用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建二:配置MyBatis 并测试(1 构建目录环境和依赖)
引言:在用IntelliJ IDEA 开发Spring+SpringMVC+Mybatis框架 分步搭建一 的基础上 继续进行项目搭建 该部分的主要目的是测通MyBatis 及Spring-dao ...
- Linux中的pipe(管道)与named pipe(FIFO 命名管道)
catalogue . pipe匿名管道 . named pipe(FIFO)有名管道 1. pipe匿名管道 管道是Linux中很重要的一种通信方式,是把一个程序的输出直接连接到另一个程序的输入,常 ...
- 用vim打开.py和.sh文件自动添加头
在~/.vimrc文件最后一行添加 "auto add pyhton header --start autocmd BufNewFile *.py 0r ~/.vim/template/py ...
- 13、 使用openpyxl存储周杰伦的歌曲信息
import requests import openpyxl res = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search ...