Scrapyd
scrapyd
安装
scrapyd-中心节点,子节点安装scrapyd-client
pip3 install scrapyd
pip3 install scrapyd-client

scrapyd-client两个作用
把本地的代码打包生成egg包
把egg上传到远程的服务器上
windows配置scrapyd-deploy
H:\Python36\Scripts下创建scrapyd-deploy.bat
python H:/Python36/Scripts/scrapyd-deploy %*
curl.exe放入H:\Python36\Scripts
启动scrapyd启动服务!!!!!!!!!!
scrapyd-deploy 查询
切换到scrapy中cmd运行scrapyd-deploy
H:\DDD-scrapy\douban>scrapyd-deploy
scrapyd-deploy -l

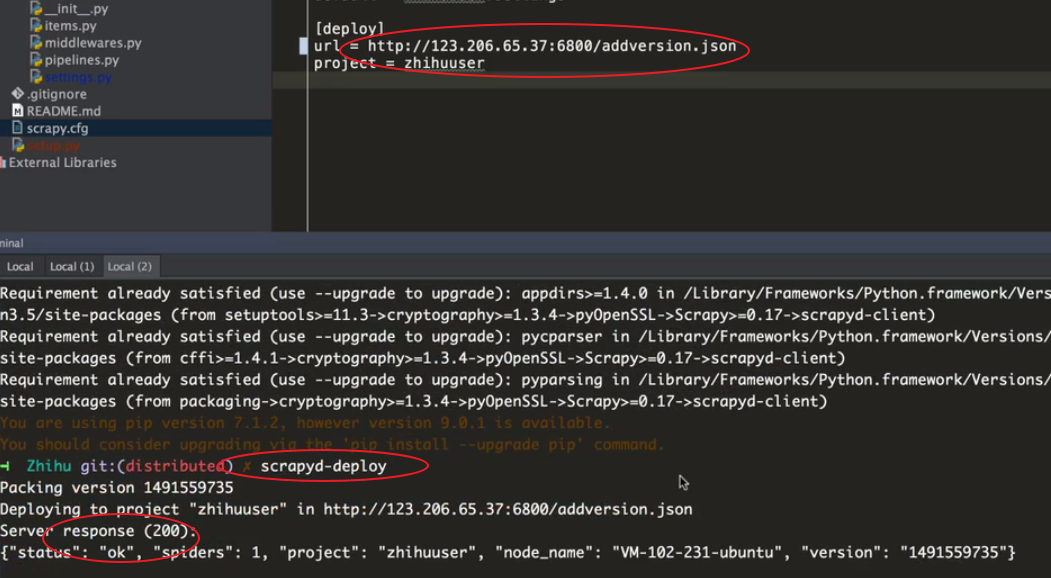
scrapy中scrapy.cfg修改配置
[deploy:dj] #开发项目名
url = http://localhost:6800/
project = douban #项目名
scrapy list这个命令确认可用,结果dang是spider名

如不可用,setting中添加以下

scrapyd-deploy 添加爬虫
scrapyd-deploy dj -p douban
H:/Python36/Scripts/scrapyd-deploy dang1 -p dangdang
dang1是开发项目名,dangdang是项目名

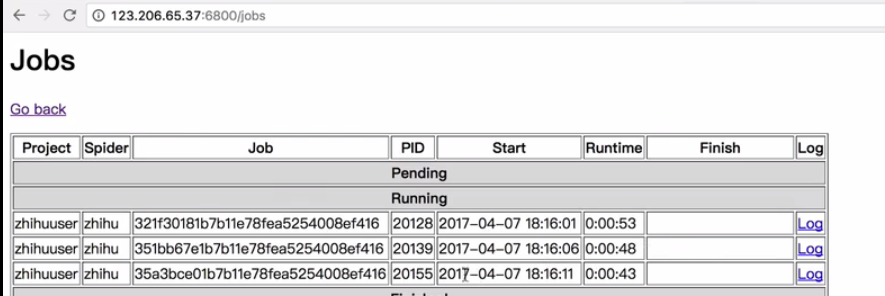
http://127.0.0.1:6800/jobs
scrapyd 当前项目的状态
curl http://localhost:6800/daemonstatus.json

curl启动爬虫
curl http://localhost:6800/schedule.json -d project=dangdang -d spider=dang
dangdang是项目名,dang是爬虫名

project=douban,spider=doubanlogin
curl http://localhost:6800/schedule.json -d project=douban -d spider=doubanlogin


远程部署:scrapyd-deploy
scrapyd-deploy 17k -p my17k
列出所有已经上传的spider
curl http://47.97.169.234:6800/listprojects.json

列出当前项目project的版本version
curl http://47.97.169.234:6800/listversions.json\?project\=my17k

远程启动spider
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

运行三次,就类似于开启三个进程
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

查看当前项目的运行情况

取消爬虫项目的job任务
curl http://localhost:6800/cancel.json -d project=dangdang -d job=68d25db0506111e9a4c0e2df1c2eb35b
curl http://47.97.169.234:6800/cancel.json -d project=my17k -d job=be6ed036508611e9b68000163e08dec9

centos配置scrapyd
https://www.cnblogs.com/ss-py/p/9661928.html
安装后新建一个配置文件:
sudo mkdir /etc/scrapyd
sudo vim /etc/scrapyd/scrapyd.conf
写入如下内容:(给内容在https://scrapyd.readthedocs.io/en/stable/config.html可找到)
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root [services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
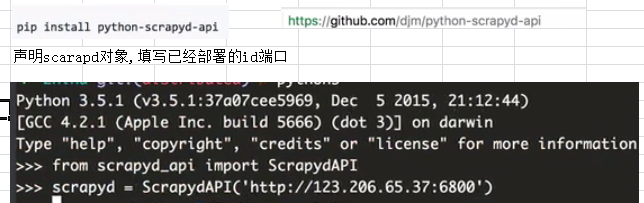
scrapyd-api
安装
scrapyd-api对scrapyd进行了一些封装
from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
使用
显示所有的projects
scrapyd.list_projects()

显示该项目下的spiders
scrapyd.list_spiders('my17k')

from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
print(scrapyd.list_projects()) #查询项目名
print(scrapyd.list_spiders('my17k')) #查询该项目名下的爬虫名
Scrapyd的更多相关文章
- scrapy的scrapyd使用方法
一直以来,很多人疑惑scrapy提供的scrapyd该怎么用,于我也是.自己在实际项目中只是使用scrapy crawl spider,用python来写一个多进程启动,还用一个shell脚本来监控进 ...
- 如何将Scrapy 部署到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- 如何部署Scrapy 到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 芝麻HTTP:Scrapyd的安装
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行. 既然是Scrapy项目部署,基本上都使用Linux主机,所以本 ...
- Scrapyd日志输出优化
现在维护着一个新浪微博爬虫,爬取量已经5亿+,使用了Scrapyd部署分布式. Scrapyd运行时会输出日志到本地,导致日志文件会越来越大,这个其实就是Scrapy控制台的输出.但是这个日志其实有用 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API
0.提出问题 Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备 ...
- Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码
0.问题现象和原因 如下图所示,由于 Scrapyd 的 Web Interface 的 log 链接直接指向 log 文件,Response Headers 的 Content-Type 又没有声明 ...
随机推荐
- mysql c connector 多条sql语句执行示例
// 假设参数 sql已经包含多条sql语句.如 sql = "insert into table1(...) values(...); update table2 set a=1;& ...
- NIO原理及案例使用
什么是NIO Java提供了一个叫作NIO(New I/O)的第二个I/O系统,NIO提供了与标准I/O API不同的I/O处理方式.它是Java用来替代传统I/O API(自Java 1.4以来). ...
- wepy项目创建
全局安装wepy npm install wepy-cli -g 创建项目 wepy init standard mywepy 安装依赖 npm install 实时编译 wepy build --w ...
- spring cloud实战与思考(三) 微服务之间通过fiegn上传一组文件(下)
需求场景: 用户调用微服务1的接口上传一组图片和对应的描述信息.微服务1处理后,再将这组图片上传给微服务2进行处理.各个微服务能区分开不同的图片进行不同处理. 上一篇博客已经讨论了在微服务之间传递一组 ...
- MT【320】依次动起来
已知$ BC=6,AC=2AB, $点$ D $满足$ \overrightarrow{AD}=\dfrac{2x}{x+y}\overrightarrow{AB}+\dfrac{y}{2(x+y)} ...
- 【dp】求最长上升子序列
题目描述 给定一个序列,初始为空.现在我们将1到N的数字插入到序列中,每次将一个数字插入到一个特定的位置.我们想知道此时最长上升子序列长度是多少? 输入 第一行一个整数N,表示我们要将1到N插入序列中 ...
- luogu4770 [NOI2018]你的名字 (SAM+主席树)
对S建SAM,拿着T在上面跑 跑的时候不仅无法转移要跳parent,转移过去不在范围内也要跳parent(注意因为范围和长度有关,跳的时候应该把长度一点一点地缩) 这样就能得到对于T的每个前缀,它最长 ...
- 2019南昌邀请赛网络预选赛 J.Distance on the tree(树链剖分)
传送门 题意: 给出一棵树,每条边都有权值: 给出 m 次询问,每次询问有三个参数 u,v,w ,求节点 u 与节点 v 之间权值 ≤ w 的路径个数: 题解: 昨天再打比赛的时候,中途,凯少和我说, ...
- Android TextView
常用属性 text:文本框中展示的文字 android:text="下载" android:text="@string/tv_text" ------- ...
- 使用mysqlbinlog对主库binlog进行同步
#!/bin/bash BASEDIR="/usr/local/mysql" BIN="$BASEDIR/bin" MYSQLBINLOG="$BIN ...